通过集成spring-boot-starter-data-redis之后一共有三种redis hash数据操作方式可以供我们选择
这种方式在本专栏上一文章中的代码,已经得以体现。
@Test
public void HashOperations() {
Person person = new Person("kobe","byrant");
person.setAddress(new Address("洛杉矶","美国"));
//使用hash的方法存储对象数据(一个属性一个属性的存,下节教大家简单的方法)
hashOperations.put("hash:player","firstname",person.getFirstname());
hashOperations.put("hash:player","lastname",person.getLastname());
hashOperations.put("hash:player","address",person.getAddress());
String firstName = (String)hashOperations.get("hash:player","firstname");
System.out.println(firstName);
}
数据在redis数据库里面存储结构是下面这样的
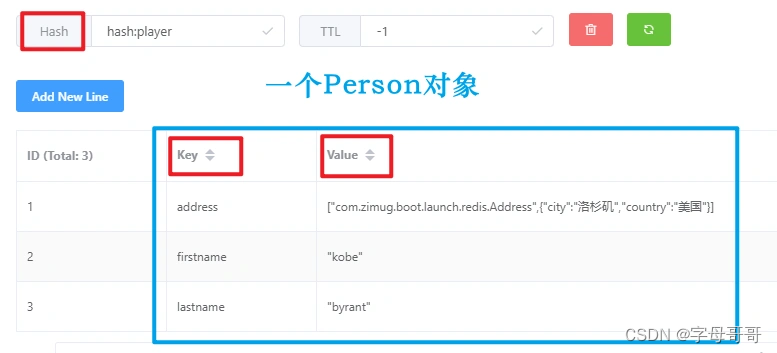
上一小节我们操作hash对象的时候是一个属性一个属性设置的,那我们有没有办法将对象一次性hash入库呢?我们可以使用jacksonHashOperations和Jackson2HashMapper
import static org.junit.jupiter.api.Assertions.assertEquals;
@SpringBootTest
public class RedisConfigTest3 {
@Resource(name="redisTemplate")
private HashOperations<String, String, Object> jacksonHashOperations;
//注意这里的false,下文会讲解
private HashMapper<Object, String, Object> jackson2HashMapper = new Jackson2HashMapper(false);
@Test
public void testHashPutAll(){
Person person = new Person("kobe","bryant");
person.setId("kobe");
person.setAddress(new Address("洛杉矶","美国"));
//将对象以hash的形式放入redis数据库
Map<String,Object> mappedHash = jackson2HashMapper.toHash(person);
jacksonHashOperations.putAll("player:" + person.getId(), mappedHash);
//将对象从数据库取出来
Map<String,Object> loadedHash = jacksonHashOperations.entries("player:" + person.getId());
Object map = jackson2HashMapper.fromHash(loadedHash);
Person getback = new ObjectMapper().convertValue(map,Person.class);
//Junit5,验证放进去的和取出来的数据一致
assertEquals(person.getFirstname(),getback.getFirstname());
}
}
使用这种方式可以一次性的存取java 对象为redis数据库的hash数据类型。需要注意的是:执行上面的测试用例,Person和Address一定要有public无参构造方法,在将map转换成Person或Address对象的时候用到,如果没有的话会报错。
当new Jackson2HashMapper(false),注意属性对象Address的存储格式(两张图对比观察)
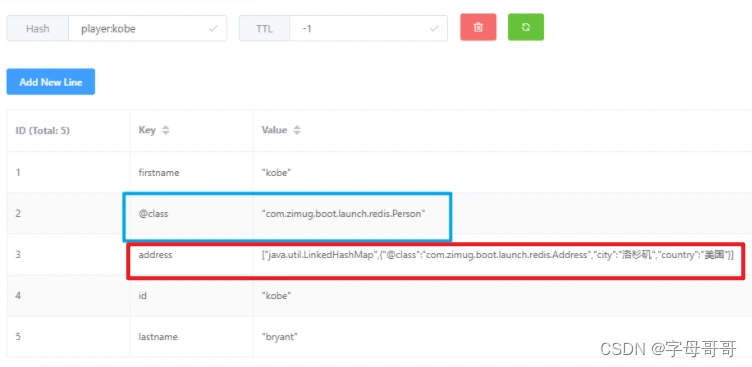
当new Jackson2HashMapper(true),注意属性对象Address的存储格式(两张图对比观察)
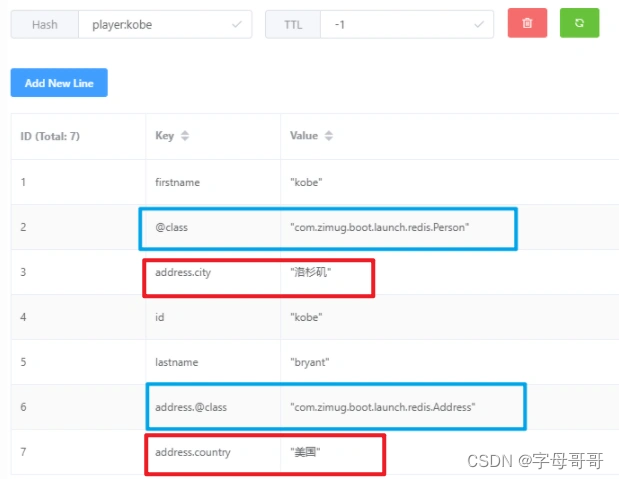
需要注意的是:使用这种方法存储hash数据,需要多出一个键值对@class说明该hash数据对应的java类。在反序列化的时候会使用到,用于将hash数据转换成java对象。
下面为大家介绍使用RedisRepository进行redis数据操作,它不只是能简单的存取数据,还可以做很多的CURD操作。使用起来和我们用JPA进行关系型数据库的单表操作,几乎是一样的。
首先,我们需要在需要操作的java实体类上面加上@RedisHash注解,并使用@Id为该实体类指定id。是不是和JPA挺像的?
@RedisHash("people") //注意这里的person,下文会说明
public class Person {
@Id
String id;
//其他和上一节代码一样
}
然后写一个PersonRepository ,继承CrudRepository,是不是也和JPA差不多?
//泛型第二个参数是id的数据类型
public interface PersonRepository extends CrudRepository<Person, String> {
// 继承CrudRepository,获取基本的CRUD操作
}
CrudRepository默认为我们提供了下面的这么多方法,我们直接调用就可以了。
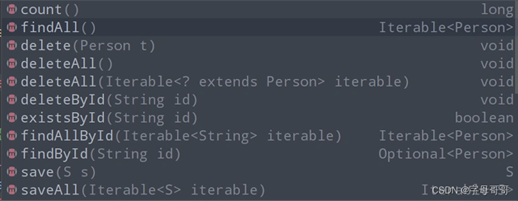
在项目入口方法上加上注解@EnableRedisRepositories(笔者测试,在比较新的版本中这个注解已经不需要添加了,默认支持),然后进行下面的测试
@SpringBootTest
public class RedisRepositoryTest {
@Resource
PersonRepository personRepository;
@Test
public void test(){
Person rand = new Person("zimug", "汉神");
rand.setAddress(new Address("杭州", "中国"));
personRepository.save(rand); //存
Optional<Person> op = personRepository.findById(rand.getId()); //取
Person p2 = op.get();
personRepository.count(); //统计Person的数量
personRepository.delete(rand); //删除person对象rand
}
}
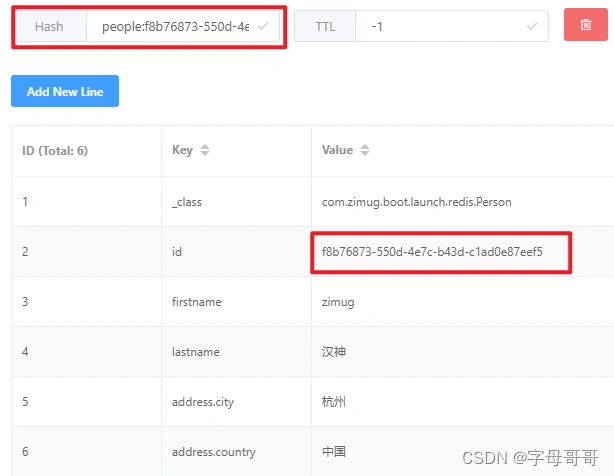
测试结果:需要注意的是RedisRepository在存取对象数据的时候,实际上使用了redis的2种数据类型
第一种是Set类型,用于保存每一个存入redis的对象(Person)的id。我们可以利用这个Set实现person对象集合类的操作,比如说:count()统计,统计redis数据库中一共保存了多少个person。注意:下图中set集合的key名称,就是通过上文代码中@RedisHash("people") 指定的。
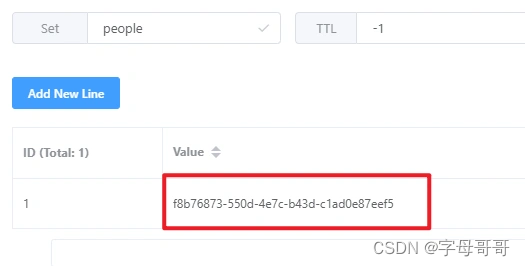
第二种是Hash类型,是用来保存Java对象的,id是RedisRepository帮我们生成的,这个id和上图中set集合中保存的id是一致的。