日常工作中,我们多少都会遇到应用的性能问题。在阿里面试中,性能优化也是常被问到的题目,用来考察是否有实际的线上问题处理经验。面对这类问题,阿里工程师齐光给出了详细流程。来阿里面试前,先看看这篇文章哦。
性能问题和Bug不同,后者的分析和解决思路更清晰,很多时候从应用日志(文中的应用指分布式服务下的单个节点)即可直接找到问题根源,而性能问题,其排查思路更为复杂一些。
对应用进行性能优化,是一个系统性的工程,对工程师的技术广度和技术深度都有所要求。一个简单的应用,它不仅包含了应用代码本身,还和容器(虚拟机)、操作系统、存储、网络、文件系统等紧密相关,线上应用一旦出现了性能问题,需要我们从多方面去考虑。
与此同时,除了一些低级的代码逻辑引发的性能问题外,很多性能问题隐藏的较深,排查起来会比较困难,需要我们对应用的各个子模块、应用所使用的框架和组件的原理有所了解,同时掌握一定的性能优化工具和经验。
本文总结了我们在进行性能优化时常用的一些工具及技巧,目的是希望通过一个全面的视角,去感知性能优化的整体脉络。本文主要分为下面三个部分:
- 第一部分会介绍性能优化的一些背景知识。
- 第二部分会介绍性能优化的通用流程以及常见的一些误区。
- 第三部分会从系统层和业务层的角度,介绍高效的性能问题定位工具和高频性能瓶颈点分布。
本文中提到的线程、堆、垃圾回收等名词,如无特别说明,指的是 Java 应用中的相关概念。

1.性能优化的背景
前面提到过,应用出现性能问题和应用存在缺陷是不一样的,后者大多数是由于代码的质量问题导致,会导致应用功能性的缺失或出现风险,一经发现,会被及时修复。而性能问题,可能是由多方面的因素共同作用的结果:代码质量一般、业务发展太快、应用架构设计不合理等,这些问题处理起来一般耗时较长、分析链路复杂,大家都不愿意干,因此可能会被一些临时性的补救手段所掩盖,如:系统水位高或者单机的线程池队列爆炸,那就集群扩容增加机器;内存占用高/高峰时段 OOM,那就重启分分钟解决......
临时性的补救措施只是在给应用埋雷,同时也只能解决部分问题。譬如,在很多场景下,加机器也并不能解决应用的性能问题,如对时延比较敏感的一些应用必须把单机的性能优化到极致,与此同时,加机器这种方式也造成了资源的浪费,长期来看是得不偿失的。对应用进行合理的性能优化,可在应用稳定性、成本核算获得很大的收益。
上面我们阐述了进行性能优化的必要性。假设现在我们的应用已经有了性能问题(eg. CPU 水位比较高),准备开始进行优化工作了,在这个过程中,潜在的痛点会有哪些呢?下面列出一些较为常见的:
- 对性能优化的流程不是很清晰。初步定为一个疑似瓶颈点后,就兴高采烈地吭哧吭哧开始干,最终解决的问题其实只是一个浅层次的性能瓶颈,真实的问题的根源并未触达;
- 对性能瓶颈点的分析思路不是很清晰。CPU、网络、内存......这么多的性能指标,我到底该关注什么,应该从哪一块儿开始入手?
- 对性能优化的工具不了解。遇到问题后,不清楚该用哪个工具,不知道通过工具得到的指标代表什么。
2.性能优化的流程
在性能优化这个领域,并没有一个严格的流程定义,但是对于绝大多数的优化场景,我们可以将其过程抽象为下面四个步骤。
- 准备阶段:主要工作是是通过性能测试,了解应用的概况、瓶颈的大概方向,明确优化目标;
- 分析阶段:通过各种工具或手段,初步定位性能瓶颈点;
- 调优阶段:根据定位到的瓶颈点,进行应用性能调优;
- 测试阶段:让调优过的应用进行性能测试,与准备阶段的各项指标进行对比,观测其是否符合预期,如果瓶颈点没有消除或者性能指标不符合预期,则重复步骤2和3。
- 下图即为上述四个阶段的简要流程。
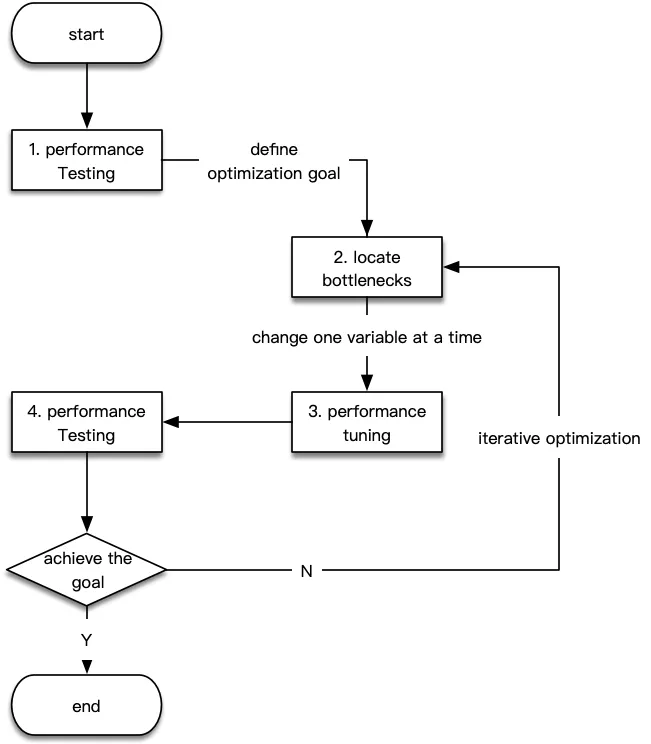
2.1 通用流程详解
在上述通用流程的四个步骤当中,步骤2和3我们会在接下来两个部分重点进行介绍。首先我们来看一下,在准备阶段和测试阶段,我们需要做一些什么。
| 2.1.1 准备阶段
准备阶段是非常关键的一步,不能省略。
首先,需要对我们进行调优的对象进行详尽的了解,所谓知己知彼,百战不殆。
- 对性能问题进行粗略评估,过滤一些因为低级的业务逻辑导致的性能问题。譬如,线上应用日志级别不合理,可能会在大流量时导致 CPU 和磁盘的负载飙高,这种情况调整日志级别即可;
- 了解应用的的总体架构,比如应用的外部依赖和核心接口有哪些,使用了哪些组件和框架,哪些接口、模块的使用率较高,上下游的数据链路是怎么样的等;
- 了解应用对应的服务器信息,如服务器所在的集群信息、服务器的 CPU/内存信息、安装的 Linux 版本信息、服务器是容器还是虚拟机、所在宿主机混部后是否对当前应用有干扰等;
其次,我们需要获取基准数据,然后结合基准数据和当前的一些业务指标,确定此次性能优化的最终目标。
- 使用基准测试工具获取系统细粒度指标。可以使用若干 Linux 基准测试工具(eg. jmeter、ab、loadrunnerwrk、wrk等),得到文件系统、磁盘 I/O、网络等的性能报告。除此之外,类似 GC、Web 服务器、网卡流量等信息,如有必要也是需要了解记录的;
- 通过压测工具或者压测平台(如果有的话),对应用进行压力测试,获取当前应用的宏观业务指标,譬如:响应时间、吞吐量、TPS、QPS、消费速率(对于有 MQ 的应用)等。压力测试也可以省略,可以结合当前的实际业务和过往的监控数据,去统计当前的一些核心业务指标,如午高峰的服务 TPS。
| 2.1.2 测试阶段
进入到这一阶段,说明我们已经初步确定了应用性能瓶颈的所在,而且已经进行初步的调优了。检测我们调优是否有效的方式,就是在仿真的条件下,对应用进行压力测试。注意:由于 Java 有 JIT(just-in-time compilation)过程,因此压力测试时可能需要进行前期预热。
如果压力测试的结果符合了预期的调优目标,或者与基准数据相比,有很大的改善,则我们可以继续通过工具定位下一个瓶颈点,否则,则需要暂时排除这个瓶颈点,继续寻找下一个变量。

2.2 注意事项
在进行性能优化时,了解下面这些注意事项可以让我们少走一些弯路。
- 性能瓶颈点通常呈现 2/8 分布,即80%的性能问题通常是由20%的性能瓶颈点导致的,2/8 原则也意味着并不是所有的性能问题都值得去优化;
- 性能优化是一个渐进、迭代的过程,需要逐步、动态地进行。记录基准后,每次改变一个变量,引入多个变量会给我们的观测、优化过程造成干扰;
- 不要过度追求应用的单机性能,如果单机表现良好,则应该从系统架构的角度去思考; 不要过度追求单一维度上的极致优化,如过度追求 CPU 的性能而忽略了内存方面的瓶颈;
- 选择合适的性能优化工具,可以使得性能优化取得事半功倍的效果;
- 整个应用的优化,应该与线上系统隔离,新的代码上线应该有降级方案。
3.瓶颈点分析工具箱
性能优化其实就是找出应用存在性能瓶颈点,然后设法通过一些调优手段去缓解。性能瓶颈点的定位是较困难的,快速、直接地定位到瓶颈点,需要具备下面两个条件:
- 恰到好处的工具;
- 一定的性能优化经验。
工欲善其事,必先利其器,我们该如何选择合适的工具呢?不同的优化场景下,又该选择那些工具呢?
首选,我们来看一下大名鼎鼎的「性能工具(Linux Performance Tools-full)图」,想必很多工程师都知道,它出自系统性能专家 Brendan Gregg。该图从 Linux 内核的各个子系统出发,列出了我们在对各个子系统进行性能分析时,可使用的工具,涵盖了监测、分析、调优等性能优化的方方面面。除了这张全景图之外,Brendan Gregg 还单独提供了基准测试工具(Linux Performance Benchmark Tools)图、性能监测工具(Linux Performance Observability Tools)图等,更详细的内容请参考 Brendan Gregg 的网站说明。
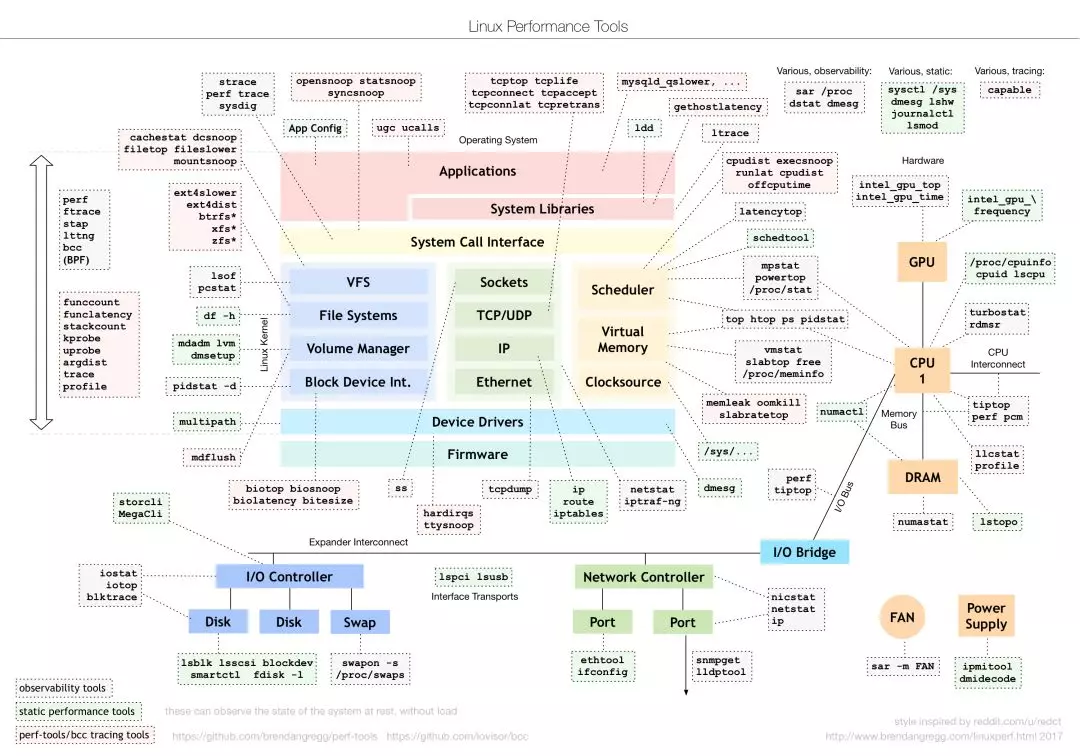
图片来源:
http://www.brendangregg.com/linuxperf.html?spm=ata.13261165.0.0.34646b44KX9rGc上面这张图非常经典,是我们做性能优化时非常好的参考资料,但事实上,我们在实际运用的时候,会发现可能它并不是最合适的,原因主要有下面两点:
1)对分析经验要求较高。上面这张图其实是从 Linux 系统资源的角度去观测性能指标的,这要求我们对 Linux 各个子系统的功能、原理要有所了解。举例:遇到性能问题了,我们不会拿每个子系统下的工具都去试一遍,大多数情况是:我们怀疑某个子系统有问题,然后根据这张图上列举的工具,去观测或者验证我们的猜想,这无疑拔高了对性能优化经验的要求;
2)适用性和完整性不是很好。我们在分析性能问题时,从系统底层自底向上地分析是较低效的,大多数时候,从应用层面去分析会更加有效。性能工具(Linux Performance Tools-full)图只是从系统层一个角度给出了工具集,如果从应用层开始分析,我们可以使用哪些工具?哪些点是我们首先需要关注的?
鉴于上面若干痛点,下面给出了一张更为实用的「性能优化工具图谱」,该图分别从系统层、应用层(含组件层)的角度出发,列举了我们在分析性能问题时首先需要关注的各项指标(其中?标注的是最需要关注的),这些点是最有可能出现性能瓶颈的地方。需要注意的是,一些低频的指标或工具,在图中并没有列出来,如 CPU 中断、索引节点使用、I/O事件跟踪等,这些低频点的排查思路较复杂,一般遇到的机会也不多,在这里我们聚焦最常见的一些就可以了。
对比上面的性能工具(Linux Performance Tools-full)图,下图的优势在于:把具体的工具同性能指标结合了起来,同时从不同的层次去描述了性能瓶颈点的分布,实用性和可操作性更强一些。系统层的工具分为CPU、内存、磁盘(含文件系统)、网络四个部分,工具集同性能工具(Linux Performance Tools-full)图中的工具基本一致。组件层和应用层中的工具构成为:JDK 提供的一些工具 + Trace 工具 + dump 分析工具 + Profiling 工具等。
这里就不具体介绍这些工具的具体用法了,我们可以使用 man 命令得到工具详尽的使用说明,除此之外,还有另外一个查询命令手册的方法:info。info 可以理解为 man 的详细版本,如果 man 的输出不太好理解,可以去参考 info 文档,命令太多,记不住也没必要记住。
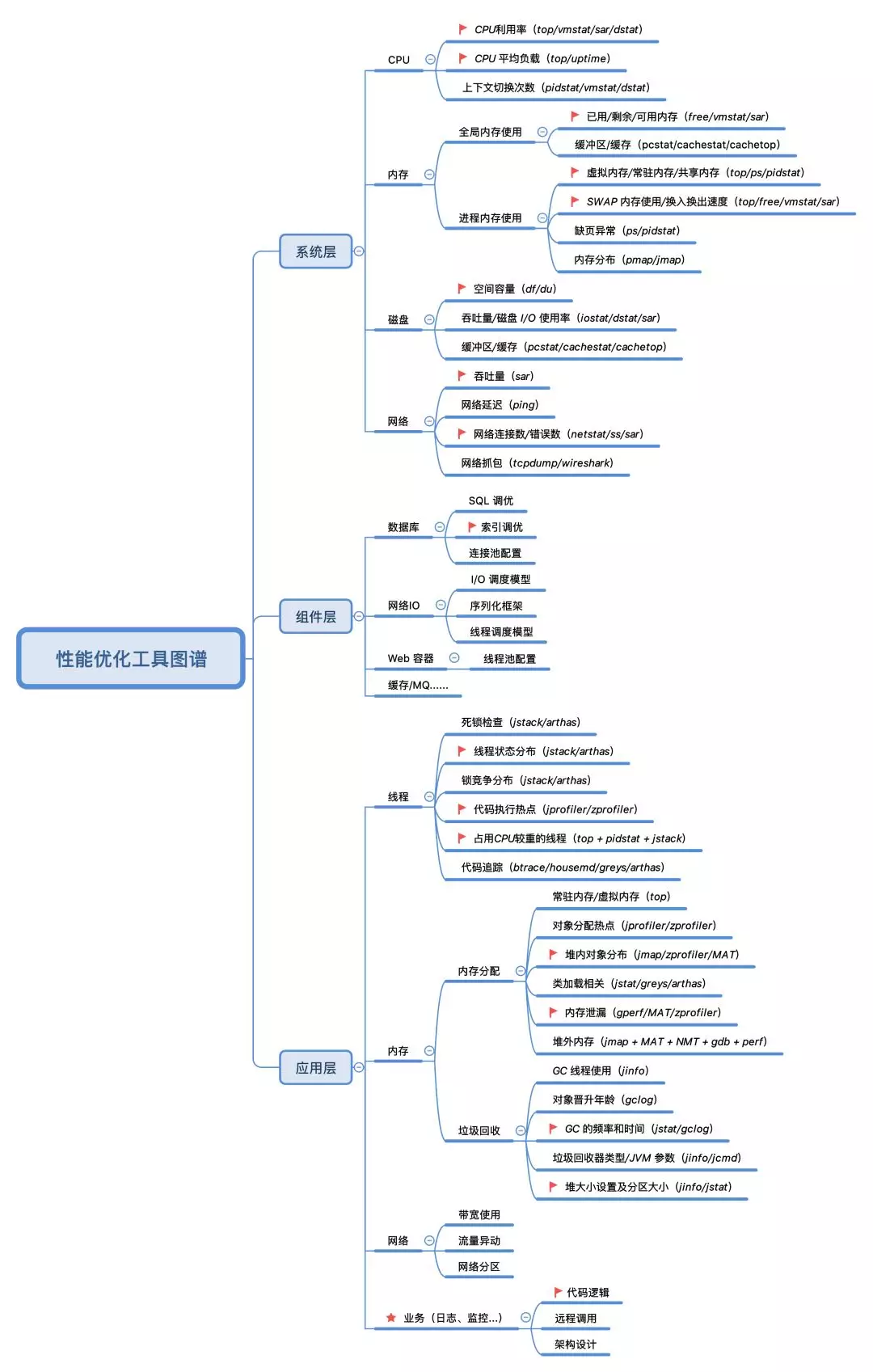
上面这张图该如何使用?
首先,虽然从系统、组件、应用两个三个角度去描述瓶颈点的分布,但在实际运行时,这三者往往是相辅相成、相互影响的。系统是为应用提供了运行时环境,性能问题的本质就是系统资源达到了使用的上限,反映在应用层,就是应用/组件的各项指标开始下降;而应用/组件的不合理使用和设计,也会加速系统资源的耗尽。因此,分析瓶颈点时,需要我们结合从不同角度分析出的结果,抽出共性,得到最终的结论。
其次,建议先从应用层入手,分析图中标注的高频指标,抓出最重要的、最可疑的、最有可能导致性能的点,得到初步的结论后,再去系统层进行验证。这样做的好处是:很多性能瓶颈点体现在系统层,会是多变量呈现的,譬如,应用层的垃圾回收(GC)指标出现了异常,通过 JDK 自带的工具很容易观测到,但是体现在系统层上,会发现系统当前的 CPU 利用率、内存指标都不太正常,这就给我们的分析思路带来了困扰。
最后,如果瓶颈点在应用层和系统层均呈现出多变量分布,建议此时使用 ZProfiler、JProfiler 等工具对应用进行 Profiling,获取应用的综合性能信息(注:Profiling 指的是在应用运行时,通过事件(Event-based)、统计抽样(Sampling Statistical)或植入附加指令(Byte-Code instrumentation)等方法,收集应用运行时的信息,来研究应用行为的动态分析方法)。譬如,可以对 CPU 进行抽样统计,结合各种符号表信息,得到一段时间内应用内的代码热点。
下面介绍在不同的分析层次,我们需要关注的核心性能指标,同时,也会介绍如何初步根据这些指标,判断系统或应用是否存在性能瓶颈点,至于瓶颈点的确认、瓶颈点的成因、调优手段,将会在下一部分展开。
3.1 CPU&&线程
和 CPU 相关的指标主要有以下几个。常用的工具有 top、 ps、uptime、 vmstat、 pidstat等。
- CPU利用率(CPU Utilization)
- CPU 平均负载(Load Average)
- 上下文切换次数(Context Switch)
top - 12:20:57 up 25 days, 20:49, 2 users, load average: 0.93, 0.97, 0.79
Tasks: 51 total, 1 running, 50 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.6 us, 1.8 sy, 0.0 ni, 89.1 id, 0.1 wa, 0.0 hi, 0.1 si, 7.3 st
KiB Mem : 8388608 total, 476436 free, 5903224 used, 2008948 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 0 avail MemPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
119680 admin 20 0 600908 72332 5768 S 2.3 0.9 52:32.61 obproxy
65877 root 20 0 93528 4936 2328 S 1.3 0.1 449:03.61 alisentry_cli第一行显示的内容:当前时间、系统运行时间以及正在登录用户数。load average 后的三个数字,依次表示过去 1 分钟、5 分钟、15 分钟的平均负载(Load Average)。平均负载是指单位时间内,系统处于可运行状态(正在使用 CPU 或者正在等待 CPU 的进程,R 状态)和不可中断状态(D 状态)的平均进程数,也就是平均活跃进程数,CPU 平均负载和 CPU 使用率并没有直接关系。
第三行的内容表示 CPU 利用率,每一列的含义可以使用 man 查看。CPU 使用率体现了单位时间内 CPU 使用情况的统计,以百分比的方式展示。计算方式为:CPU 利用率 = 1 - (CPU 空闲时间)/ CPU 总的时间。需要注意的是,通过性能分析工具得到的 CPU 的利用率其实是某个采样时间内的 CPU 平均值。注:top 工具显示的的 CPU 利用率是把所有 CPU 核的数值加起来的,即 8 核 CPU 的利用率最大可以到达800%(可以用 htop 等更新一些的工具代替 top)。
使用 vmstat 命令,可以查看到「上下文切换次数」这个指标,如下表所示,每隔1秒输出1组数据:
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 504804 0 1967508 0 0 644 33377 0 1 2 2 88 0 9上表的 cs(context switch) 就是每秒上下文切换的次数,按照不同场景,CPU 上下文切换还可以分为中断上下文切换、线程上下文切换和进程上下文切换三种,但是无论是哪一种,过多的上下文切换,都会把 CPU 时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正运行的时间,导致系统的整体性能大幅下降。vmstat 的输出中 us、sy 分别用户态和内核态的 CPU 利用率,这两个值也非常具有参考意义。
vmstat 的输只给出了系统总体的上下文切换情况,要想查看每个进程的上下文切换详情(如自愿和非自愿切换),需要使用 pidstat,该命令还可以查看某个进程用户态和内核态的 CPU 利用率。

CPU 相关指标异常的分析思路是什么?
1)CPU 利用率:如果我们观察某段时间系统或应用进程的 CPU利用率一直很高(单个 core 超过80%),那么就值得我们警惕了。我们可以多次使用 jstack 命令 dump 应用线程栈查看热点代码,非 Java 应用可以直接使用 perf 进行 CPU 采采样,离线分析采样数据后得到 CPU 执行热点(Java 应用需要符号表进行堆栈信息映射,不能直接使用 perf得到结果)。
2)CPU 平均负载:平均负载高于 CPU 数量 70%,意味着系统存在瓶颈点,造成负载升高的原因有很多,在这里就不展开了。需要注意的是,通过监控系统监测平均负载的变化趋势,更容易定位问题,有时候大文件的加载等,也会导致平均负载瞬时升高。如果 1 分钟/5 分钟/15 分钟的三个值相差不大,那说明系统负载很平稳,则不用关注,如果这三个值逐渐降低,说明负载在渐渐升高,需要关注整体性能;
3)CPU 上下文切换:上下文切换这个指标,并没有经验值可推荐(几十到几万都有可能),这个指标值取决于系统本身的 CPU 性能,以及当前应用工作的情况。但是,如果系统或者应用的上下文切换次数出现数量级的增长,就有很大概率说明存在性能问题,如非自愿上下切换大幅度上升,说明有太多的线程在竞争 CPU。
上面这三个指标是密切相关的,如频繁的 CPU 上下文切换,可能会导致平均负载升高。如何根据这三者之间的关系进行应用调优,将在下一部分介绍。
CPU 上的的一些异动,通常也可以从线程上观测到,但需要注意的是,线程问题并不完全和 CPU 相关。与线程相关的指标,主要有下面几个(均都可以通过 JDK 自带的 jstack 工具直接或间接得到):
- 应用中的总的线程数;
- 应用中各个线程状态的分布;
- 线程锁的使用情况,如死锁、锁分布等;
关于线程,可关注的异常有:
1)线程总数是否过多。过多的线程,体现在 CPU 上就是导致频繁的上下文切换,同时线程过多也会消耗内存,线程总数大小和应用本身和机器配置相关;
2)线程的状态是否异常。观察 WAITING/BLOCKED 线程是否过多(线程数设置过多或锁竞争剧烈),结合应用内部锁使用的情况综合分析;
3)结合 CPU 利用率,观察是否存在大量消耗 CPU 的线程。

3.2 内存&&堆
和内存相关的指标主要有以下几个,常用的分析工具有:top、free、vmstat、pidstat 以及 JDK 自带的一些工具。
- 系统内存的使用情况,包括剩余内存、已用内存、可用内存、缓存/缓冲区;
- 进程(含 Java 进程)的虚拟内存、常驻内存、共享内存;
- 进程的缺页异常数,包含主缺页异常和次缺页异常;
- Swap 换入和换出的内存大小、Swap 参数配置;
- JVM 堆的分配,JVM 启动参数;
- JVM 堆的回收,GC 情况。
使用 free 可以查看系统内存的使用情况和 Swap 分区的使用情况,top 工具可以具体到每个进程,如我们可以用使用 top 工具查看 Java 进程的常驻内存大小(RES),这两个工具结合起来,可用覆盖大多数内存指标。下面是使用 free命令的输出:
$free -h
total used free shared buff/cache availableMem: 125G 6.8G 54G 2.5M 64G 118G
Swap: 2.0G 305M 1.7G
上述输出各列的具体含义在这里不在赘述,也比较容易理解。重点介绍下 swap 和 buff/cache 这两个指标。
Swap 的作用是把一个本地文件或者一块磁盘空间作为内存来使用,包括换出和换入两个过程。Swap 需要读写磁盘,所以性能不是很高,事实上,包括 ElasticSearch 、Hadoop 在内绝大部分 Java 应用都建议关掉 Swap,这是因为内存的成本一直在降低,同时这也和 JVM 的垃圾回收过程有关:JVM在 GC 的时候会遍历所有用到的堆的内存,如果这部分内存被 Swap 出去了,遍历的时候就会有磁盘 I/O 产生。Swap 分区的升高一般和磁盘的使用强相关,具体分析时,需要结合缓存使用情况、swappiness 阈值以及匿名页和文件页的活跃情况综合分析。
buff/cache 是缓存和缓冲区的大小。缓存(cache):是从磁盘读取的文件的或者向磁盘写文件时的临时存储数据,面向文件。使用 cachestat 可以查看整个系统缓存的读写命中情况,使用 cachetop 可以观察每个进程缓存的读写命中情况。缓冲区(buffer)是写入磁盘数据或从磁盘直接读取的数据的临时存储,面向块设备。free 命令的输出中,这两个指标是加在一起的,使用 vmstat 命令可以区分缓存和缓冲区,还可以看到 Swap 分区换入和换出的内存大小。
了解到常见的内存指标后,常见的内存问题又有哪些?总结如下:
- 系统剩余内存/可用不足(某个进程占用太多、系统本身内存不足),内存溢出;
- 内存回收异常:内存泄漏(进程在一段时间内内存使用持续走高)、GC 频率异常;
- 缓存使用过大(大文件读取或写入)、缓存命中率不高;
- 缺页异常过多(频繁的 I/O 读);
- Swap 分区使用异常(使用过大);
内存相关指标异常后,分析思路是怎么样的?
- 使用 free/top 查看内存的全局使用情况,如系统内存的使用、Swap 分区内存使用、缓存/缓冲区占用情况等,初步判断内存问题存在的方向:进程内存、缓存/缓冲区、Swap 分区;
- 观察一段时间内存的使用趋势。如通过 vmstat 观察内存使用是否一直在增长;通过 jmap 定时统计对象内存分布情况,判断是否存在内存泄漏,通过 cachetop 命令,定位缓冲区升高的根源等;
- 根据内存问题的类型,结合应用本身,进行详细分析。
举例:使用 free 发现缓存/缓冲区占用不大,排除缓存/缓冲区对内存的影响后 -> 使用 vmstat 或者 sar 观察一下各个进程内存使用变化趋势 -> 发现某个进程的内存时候用持续走高 -> 如果是 Java 应用,可以使用 jmap / VisualVM / heap dump 分析等工具观察对象内存的分配,或者通过 jstat 观察 GC 后的应用内存变化 -> 结合业务场景,定位为内存泄漏/GC参数配置不合理/业务代码异常等。
3.3 磁盘&&文件
在分析和磁盘相关的问题时,通常是将其和文件系统同时考虑的,下面不再区分。和磁盘/文件系统相关的指标主要有以下几个,常用的观测工具为 iostat和 pidstat,前者适用于整个系统,后者可观察具体进程的 I/O。
- 磁盘 I/O 利用率:是指磁盘处理 I/O 的时间百分比;
- 磁盘吞吐量:是指每秒的 I/O 请求大小,单位为 KB;
- I/O 响应时间,是指 I/O 请求从发出到收到响应的间隔,包含在队列中的等待时间和实际处理时间;
- IOPS(Input/Output Per Second):每秒的 I/O 请求数;
- I/O 等待队列大小,指的是平均 I/O 队列长度,队列长度越短越好;
使用 iostat 的输出界面如下:
$iostat -dx
Linux 3.10.0-327.ali2010.alios7.x86_64 (loginhost2.alipay.em14) 10/20/2019 x86_64 (32 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.01 15.49 0.05 8.21 3.10 240.49 58.92 0.04 4.38 2.39 4.39 0.09 0.07上图中 %util ,即为磁盘 I/O 利用率,同 CPU 利用率一样,这个值也可能超过 100%(存在并行 I/O);rkB/s 和 wkB/s分别表示每秒从磁盘读取和写入的数据量,即吞吐量,单位为 KB;磁盘 I/O处理时间的指标为 r_await 和 w_await 分别表示读/写请求处理完成的响应时间,svctm 表示处理 I/O 所需要的平均时间,该指标已被废弃,无实际意义。r/s + w/s 为 IOPS 指标,分别表示每秒发送给磁盘的读请求数和写请求数;aqu-sz 表示等待队列的长度。
pidstat 的输出大部分和 iostat 类似,区别在于它可以实时查看每个进程的 I/O 情况。
如何判断磁盘的指标出现了异常?
- 当磁盘 I/O 利用率长时间超过 80%,或者响应时间过大(对于 SSD,从 0.0x 毫秒到 1.x 毫秒不等,机械磁盘一般为5ms~10ms),通常意味着磁盘 I/O 存在性能瓶颈;
- 如果 %util 很大,而 rkB/s 和 wkB/s 很小,一般是因为存在较多的磁盘随机读写,最好把随机读写优化成顺序读写,(可以通过 strace 或者 blktrace 观察 I/O 是否连续判断是否是顺序的读写行为,随机读写应可关注 IOPS 指标,顺序读写可关注吞吐量指标);
- 如果 avgqu-sz 比较大,说明有很多 I/O 请求在队列中等待。一般来说,如果单块磁盘的队列长度持续超过2,一般认为该磁盘存在 I/O 性能问题。

3.4 网络
网络这个概念涵盖的范围较广,在应用层、传输层、网络层、网络接口层都有不同的指标去衡量。这里我们讨论的「网络」,特指应用层的网络,通常使用的指标如下:
- 网络带宽:表示链路的最大传输速率;
- 网络吞吐:表示单位时间内成功传输的数据量大小;
- 网络延时:表示从网络请求发出后直到收到远端响应,所需要的时间;
- 网络连接数和错误数;
一般来说,应用层的网络瓶颈有如下几类:
- 集群或机器所在的机房的网络带宽饱和,影响应用 QPS/TPS 的提升;
- 网络吞吐出现异常,如接口存在大量的数据传输,造成带宽占用过高;
- 网络连接出现异常或错误;
- 网络出现分区。
带宽和网络吞吐这两个指标,一般我们会关注整个应用的,通过监控系统可直接得到,如果一段时间内出现了明显的指标上升,说明存在网络性能瓶颈。对于单机,可以使用 sar 得到网络接口、进程的网络吞吐。
使用 ping 或者 hping3 可以得到是否出现网络分区、网络具体时延。对于应用,我们更关注整个链路的时延,可以通过中间件埋点后输出的 trace 日志得到链路上各个环节的时延信息。
使用 netstat、ss 和 sar 可以获取网络连接数或网络错误数。过多网络链接造成的开销是很大的,一是会占用文件描述符,二是会占用缓存,因此系统可以支撑的网络链接数是有限的。
3.5 工具总结
可以看到的是,在分析 CPU、内存、磁盘等的性能指标时,有几种工具是高频出现的,如 top、vmstat、pidstat,这里稍微总结一下:
- CPU:top、vmstat、pidstat、sar、perf、jstack、jstat;
- 内存:top、free、vmstat、cachetop、cachestat、sar、jmap;
- 磁盘:top、iostat、vmstat、pidstat、duhttps://img.qb5200.com/download-x/df;
- 网络:netstat、sar、dstat、tcpdump;
- 应用:profiler、dump分析。
上述的很多工具,大部分是用于查看系统层指标的,在应用层,除了有 JDK 提供的一系列工具,一些商用的产品如 gceasy.io(分析 GC 日志)、fastthread.io(分析线程 dump 日志)也是不错的。
排查 Java 应用的线上异常或者分析应用代码瓶颈,可以使用阿里开源的 Arthas ,这个工具非常强大,下面简单介绍下。
Arthas 主要面向线上应用实时诊断,解决的是类似「线上应用异常了,需要在线进行分析和定位」的问题,当然,Arthas 提供的一些方法调用追踪工具,对我们排查诸如「慢查询」等问题,也是非常有帮助的。Arthas 提供的主要功能有:
- 获取线程统计,如线程持有的锁统计、CPU 利用率统计等;
- 类加载信息、动态类加载、方法加载信息;
- 调用栈追踪,调用耗时统计;
- 方法调用参数、结果检测;
- 系统配置、应用配置信息;
- 反编译加载类;
- ....
需要注意的是,性能工具只是解决性能问题的手段,我们了解常用工具的一般用法即可,不要在工具学习上投入过多精力。

