----------
莺嘴啄花红溜,燕尾点波绿皱。
指冷玉笙寒,吹彻小梅春透。
依旧,依旧,人与绿杨俱瘦。
——《如梦令·春景》 秦观
更多精彩内容请关注微信公众号 “**优化与算法**”
## 1、背景
随着信息技术的发展,数据量呈现爆照式增长,高维海量数据给传统的数据处理方法带来了严峻的挑战,因此,开发高效的数据处理技术是非常必要的。数据降维是解决维度灾难的一种有效方法,之所以对数据进行降维是因为:
1. 在原始的高维空间中,包含有冗余信息以及噪音信息,在实际应用例如图像识别中造成了误差,降低了准确率;而通过降维,我们希望减少冗余信息所造成的误差,提高识别(或其他应用)的精度。
2. 希望通过降维算法来寻找数据内部的本质结构特征。
主成分分析(Principal Component Analysis,PCA)是一种常见的线性降维方法,广泛应用于图像处理、人脸识别、数据压缩、信号去噪等领域。
## 2、算法思想与原理
设原数据大小为 $N\times M$ ,经过PCA降维后的数据大小为 $N \times K$,其中 $K
 表1. 理想房子面积与总价关系 表1. 理想房子面积与总价关系
|
这些数据在二维平面中可以表示为:
 图1. 理想房子面积与总价关系 图1. 理想房子面积与总价关系
|
然而在实际中并非如此,由于各种原因总会产生一些波动,有可能会是如表2所示的关系。
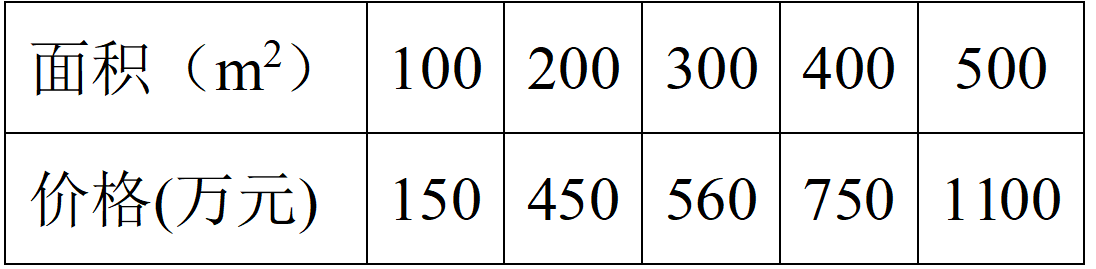 表2. 实际房子面积与总价关系 表2. 实际房子面积与总价关系
|
同样的,这些数据在二维平面中可以表示为:
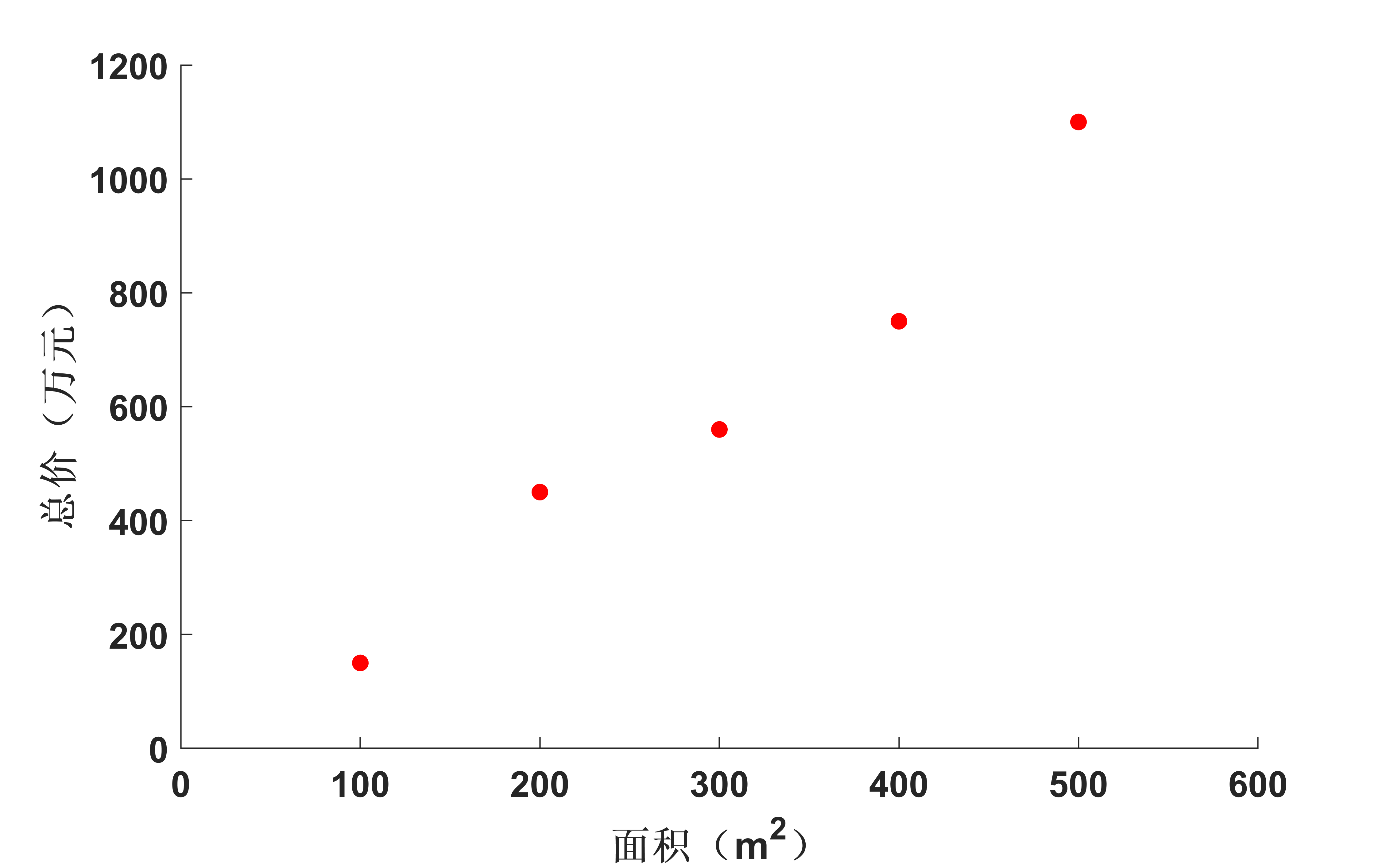 图2. 实际房子面积与总价关系 图2. 实际房子面积与总价关系
|
若把表一中的数据当作一个矩阵来看,就变成:
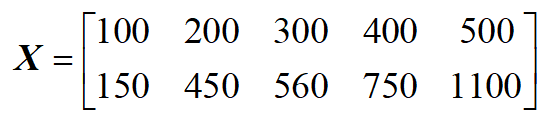 表3. 表1中数据的矩阵形式 表3. 表1中数据的矩阵形式
|
从表1中的数据来看,在理想情况下,房子面积和总价符合正比关系,也就是说房子面积和总价具有很大的相关性,若把它当成一个 $2\times 5$ 的矩阵的话,它的秩为1,这说明用表1中的10个数据来描述房子面积和总价的这种关系显得有些**冗余**,我们只需要一行数据($5$个)就可以描述清楚这种关系。在实际情况中,表2中的两行数据虽然不满足完全的正比关系,但是它们也非常接近正比关系,因此,他们之间的相关性也是非常大的。那么我们如何将 $\bf{X}$ 中的数据用一行数(也就是从二维降到一维)来表示呢?由前面相关性分析可知,应该是要进行“去相关性”操作,也就是要使两行数据通过一个变换,使其相关性变小。
数学里通常用方差和协方差来描述数据的相关性,方差定义如下:
$$Var({\bf{x}}) = \frac{1}{N}\sum\limits_{i = 1}^N {{{\left( {{x_i} - E({\bf{x}})} \right)}^2}} $$
其中 $E({\bf{x}}) = \frac{1}{N}\sum\limits_{i = 1}^N {\left( {{x_i}} \right)}$为向量 $\bf{x}$ 的期望。
很明显,方差是描述一个向量(维度)内数据的分散程度(相关性)的度量,若如果数据是像表3一样的矩阵形式呢?那么就用协方差来描述数据之间的相关性:
$$Cov( \bf{x},\bf{y}) \ =\ \frac{1}{N}\sum ^{N}_{i=1}( x_{i} \ -E(\bf{x}))( y_{i} -E(\bf{y}))
=E[( \bf{x}-E(\bf{x}))( \bf{y}-E(\bf{y}))$$
数量高于2个的 $N$ 维数据通常用协方差矩阵来表示:
$$ \bf{C}\ =\begin{pmatrix}
cov(\bf{x},\bf{x}) & cov( \bf{x},\bf{y})\\
cov( \bf{y},\bf{x}) & cov( \bf{y},\bf{y})
\end{pmatrix}$$
假设数据已经经过中心化处理,数据矩阵 $\bf{X}$ 的协方差矩阵就可以写成:
$$ \bf{C_{\bf{X}}}\ =\begin{pmatrix}
cov(\bf{X}_{1},\bf{X}_{1}) & cov(\bf{X}_{1},\bf{X}_{2})\\
cov( \bf{X}_{2},\bf{X}_{1}) & cov( \bf{X}_{2},\bf{X}_{2})
\end{pmatrix}$$
其中,$\bf{X}_{1}$ 和 $\bf{X}_{2}$ 分别为 $\bf{X}$ 的第一行和第二行。
在这个例子中,协方差具体表示什么意义呢?
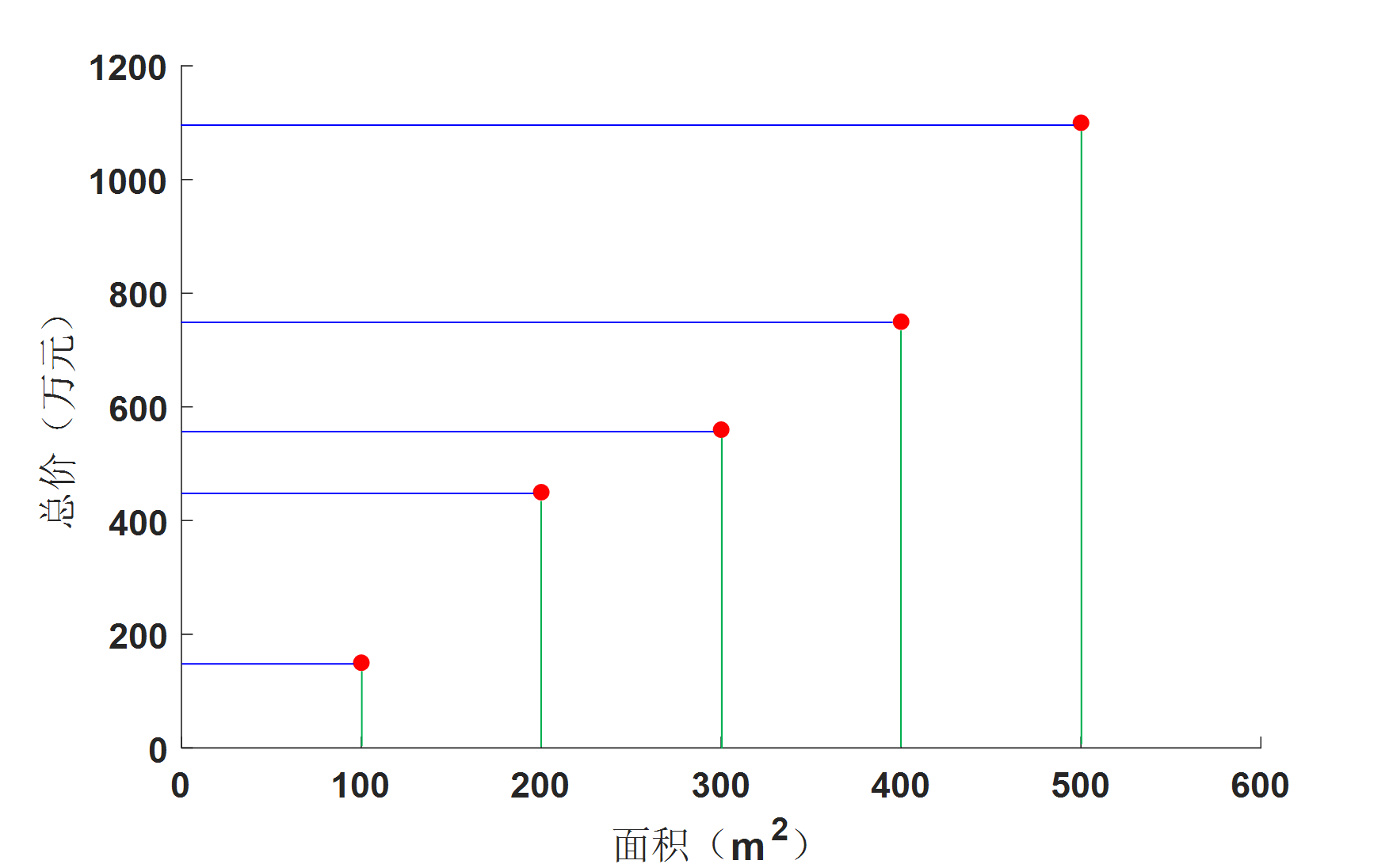 图3. 协方差的意义 图3. 协方差的意义
|
如图3所示,将各个数据点分别对横轴和纵轴做投影,其中绿色线与横轴的交点为数据在横轴上的投影,蓝线与纵轴的交点为数据在纵轴上的投影。那么横轴上交点的分散程度(方差)就对应了 $\bf{C}$ 中的 $cov(\bf{x},\bf{x})$,而纵轴上的交点的分散程度就对应了 $\bf{C}$ 中的 $cov(\bf{y},\bf{y})$。$cov( \bf{y},\bf{x}$ 则表示 $\bf{x}$ 和 $\bf{y}$ 之间的相关程度。
那么由PCA的中心思想:**将高维数据投影到具有最大方差的低维空间中**,我们就可以知道只要将数据投影到方差最大的低维($K$ 维)空间中就行,那么如何找到方差最大的低维空间呢?如图4所示,数据不仅可以投影到横轴和纵轴,还可以360度旋转,投影到任何直线(1维空间)上,对于图4中的 $pc1$ 方向和 $pc2$ 方向,可以直观的看出来肯定要投影到 $pc1$ 方向要好一点,因为投影之后的数据点更分散。
数据投影到一个维度越分散在一定程度上就说明两类数据的相关性越小,这就指导我们一条思路:只需要将 $\bf{C_{\bf{X}}}$ 中的两个协方差 $cov(\bf{X}_{1},\bf{X}_{2})$ 和 $cov(\bf{X}_{2},\bf{X}_{1})$ 变成0就可以了,这就意味着将 $\bf{C_{\bf{X}}}$ 变成对角矩阵就行了。
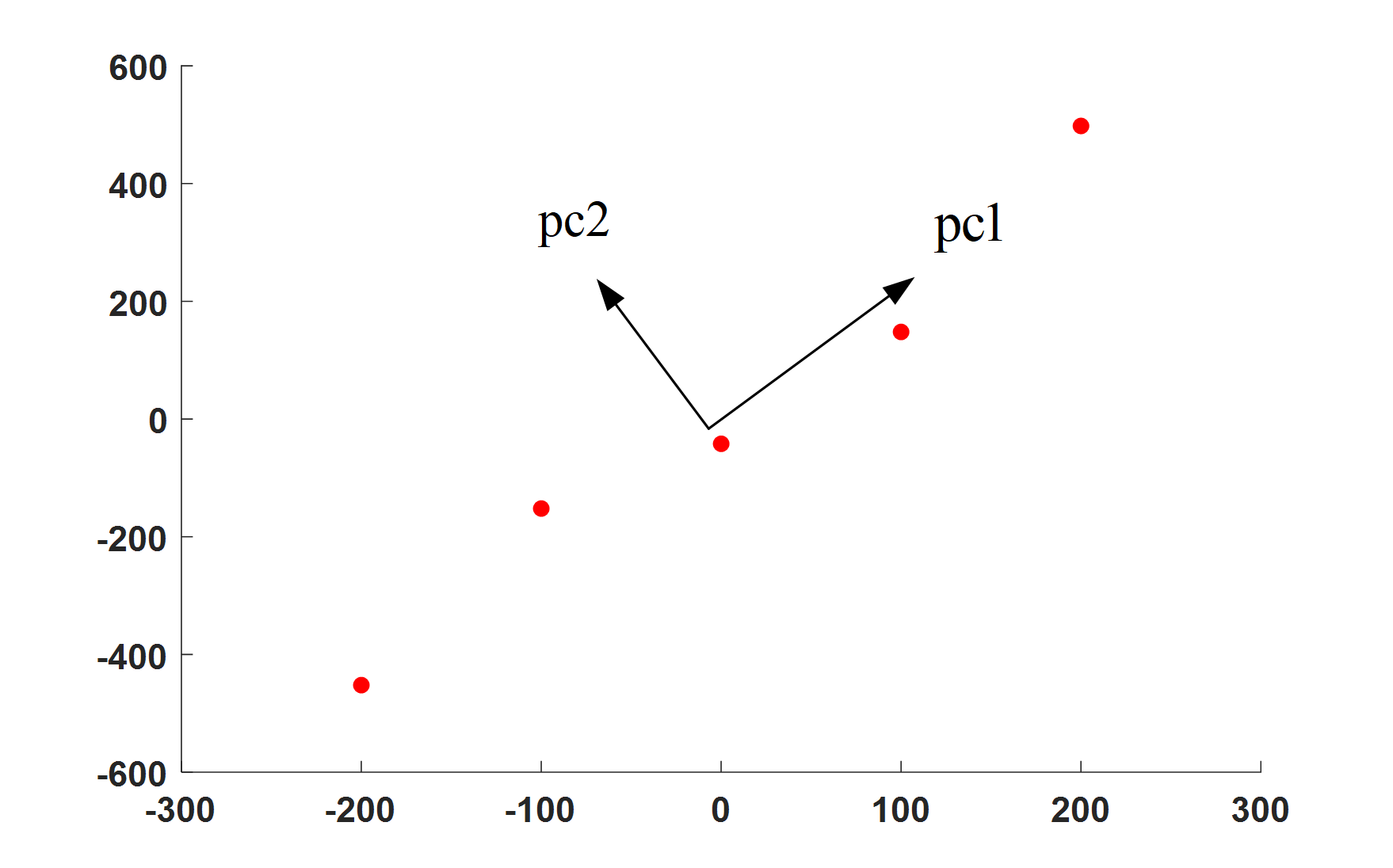 图4. 如何选择投影方向? 图4. 如何选择投影方向?
|
我们发现 $\bf{C_{\bf{X}}}$ 是一个对称矩阵,自然就会想到特征值分解。
> $\bf{C_{\bf{X}}}$ 是 $\bf{M}$ 阶对称矩阵,则必有正交矩阵 $\bf{P}$使得:
> ${{\bf{P}}^{ - 1}}{{\bf{C}}_{\bf{X}}}{\bf{P}} = {{\bf{P}}^{\rm T}}{{\bf{C}}_{\bf{X}}}{\bf{P}} = {\bf{\Lambda }}$
> 其中 $\bf{\Lambda }$ 是以 $\bf{C_{\bf{X}}}$ 的 $\bf{M}$ 个特征值为对角元
因此我们只要找到这个正交矩阵 $\bf{P}$ 和它对应的特征值,然后取前 $K$ 个最大的特征值及其对应的特征向量就可以了,这实际上就是进行特征值分解:
$${{\bf{C}}_{\bf{X}}} = {{\bf{P}}^{\rm T}}{\bf{\Lambda P}}$$
当然也可以通过奇异值分解来解决问题:
$${{\bf{C}}_{\bf{X}}} = {\bf{U\Sigma V}}$$
经过奇异值分解后得到的 $\bf{\Sigma}$ 中最大的 $K$ 个奇异值及其对应的 $\bf{U}$ 中的 $K$ 个列向量组成的矩阵就是变换矩阵。如果用右奇异矩阵 $\bf{U}$ 的话就是对 $\bf{X}$ 的列进行降维了。
求协方差矩阵 ${{\bf{C}}_{\bf{X}}} = {{\bf{X}}}{\bf{X}^{\rm T}}$ (这里实际上是散度矩阵,是协方差矩阵的 $N-1$ 倍)的复杂度为 $O\left( {M{N^2}} \right)$,当数据维度过大时,还是很耗时的,此时用奇异值分解有一定的优势,比如有一些SVD的实现算法可以先不求出协方差矩阵也能求出右奇异矩阵 $\bf{V}$,也就是说,PCA算法可以不用做特征分解而是通过SVD来完成,这个方法在样本量很大的时候很有效。
至于为什么协方差矩阵经过特征值(奇异值)分解后前 $K$ 个最大特征值对应的分量就是方差最大的 $K$ 维空间呢?这里给出一个简单的理解方法,数学证明就不贴出来了。$K$ 个特征值与$K$ 个特征向量构成了一个 $K$ 维空间,而特征值正是衡量每一维空间所占的分量的,特征值越大,说明这一维度所包含的信息量越大,权重就越大。前 $K$ 个最大特征值组成的空间当然是权重最大的,从而矩阵 $\bf{X}$ 投影到这 $K$ 维空间中足够分散,也就是说方差足够大。
### 2.3 PCA的理论推导
这里引用一下
这里是引用[主成分分析(PCA)原理总结](https://www.cnblogs.com/pinard/p/6239403.html)这篇博客的证明。



### 2.4 PCA实例求解
还是以某地房子面积与总价的问题作为例子来总结PCA算法步骤。
步骤1. 数据去中心化:
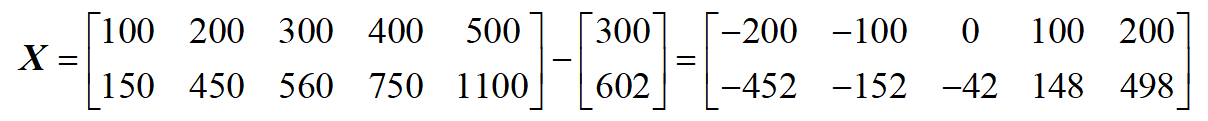 步骤2:计算散度矩阵(协方差矩阵)
步骤2:计算散度矩阵(协方差矩阵)
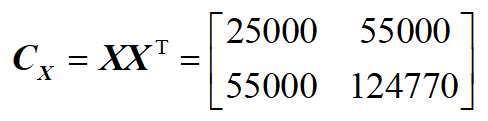 步骤3:对协方差矩阵进行特征值(奇异值分解):
步骤3:对协方差矩阵进行特征值(奇异值分解):
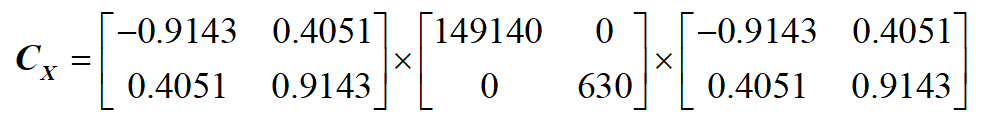 步骤4:取最大的 $K$ 个特征值与特征向量构成一个 变换矩阵 $\bf{P}_K$(这里 $K=1$):
步骤4:取最大的 $K$ 个特征值与特征向量构成一个 变换矩阵 $\bf{P}_K$(这里 $K=1$):
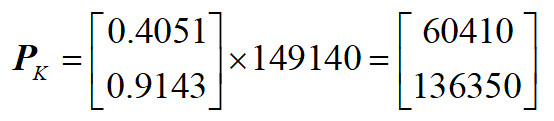 步骤5:将原始数据投影到 $K$ 维空间:
$${\bf{Y}} = {\bf{P}}_K^{\rm T}{\bf{X}}$$
我们可以看到最后结果,那条投影线跟我们直观感受的一样:
步骤5:将原始数据投影到 $K$ 维空间:
$${\bf{Y}} = {\bf{P}}_K^{\rm T}{\bf{X}}$$
我们可以看到最后结果,那条投影线跟我们直观感受的一样:
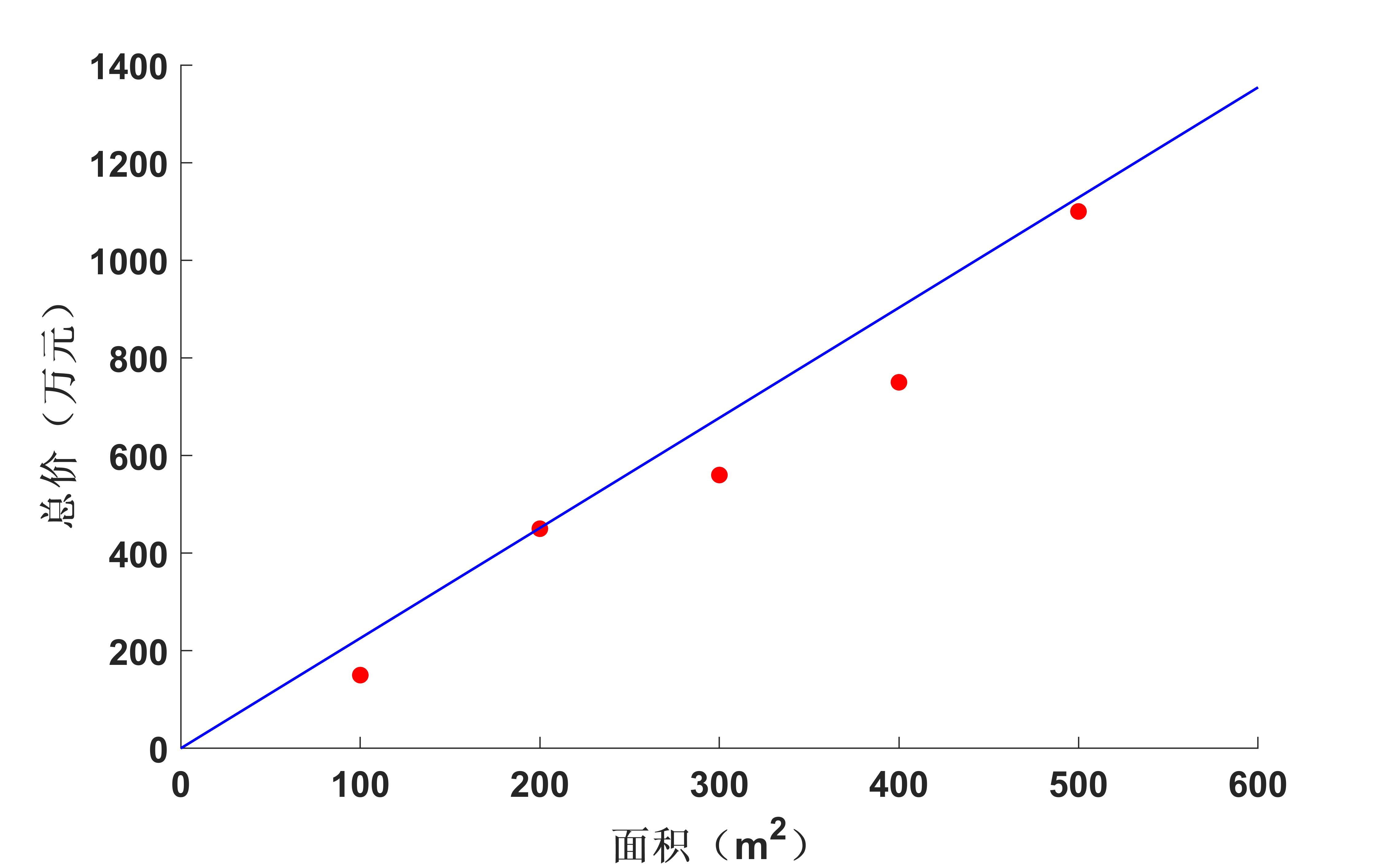 ## 3. PCA的应用
PCA在特征工程、计算机视觉、人脸识别、去噪等领域有很广泛的应用。这里仅仅测试一下PCA在图像压缩上的效果。matlab代码如下:
```matlab
function [P,r] = fun_pca(X,K)
% 输入:
% X:经过中心化处理的数据
% K: 需要降低到的维度
% 输出:
% P: 投影矩阵
% r:前K个奇异值占所有奇异值的比
Cov = X*X';
[u,s] = svd(Cov) ;
P = u(:,1:K) ;
s = diag(s) ;
r = sum(abs(s(1:K)))/sum(abs(s)) ;
end
```
```matlab
PCA for image compression
clear
img = imread('xinhuan.jpg');
img = im2double(img);
K=50;
% 保留主成分个数
img_matrix = [img(:,:,1),img(:,:,2),img(:,:,3)] ;
% 将RGB三通道图像合并成一个矩阵
img_matrix_mean = img_matrix - mean(img_matrix) ;
% 求均值
Proj = fun_pca(img_matrix_mean,K) ;
% 用PCA算法获得投影矩阵P
img_K = Proj'*img_matrix_mean ;
% 压缩到K维后的图像
%% 图像重建
img_rec = Proj*img_K ;
% 图像解压缩
img_rec = img_rec + mean(img_matrix) ;
% 重建后的图像加上均值
c_n = size(img_matrix,2)/3 ;
img_rec = cat(3,img_rec(:,1:c_n),img_rec(:,c_n+1:2*c_n),img_rec(:,2*c_n+1:end)) ;
figure(1)
subplot(1,2,1)
imshow(img),title('原图')
subplot(1,2,2)
imshow(img_rec),title(strcat('压缩后的图像(', '奇异值数量:10)'))
```
```matlab
SVD for image compression
clear
img = imread('xinhuan.jpg');
img = im2double(img);
K = 10 ;
for i = 1:3
[u,s,v] = svd(img(:,:,i)) ;
s = diag(s) ;
r = sum(abs(s(1:K)))/sum(abs(s)) ;
s = diag(s(1:K)) ;
W(:,:,i) = u(:,1:K)*s*v(:,1:K)' ;
end
figure(1)
subplot(2,2,1)
imshow(img),title('原图')
subplot(2,2,2)
imshow(P),title(strcat('压缩后的图像(', '奇异值数量:10)'))
```
奇异值分解图像压缩:
## 3. PCA的应用
PCA在特征工程、计算机视觉、人脸识别、去噪等领域有很广泛的应用。这里仅仅测试一下PCA在图像压缩上的效果。matlab代码如下:
```matlab
function [P,r] = fun_pca(X,K)
% 输入:
% X:经过中心化处理的数据
% K: 需要降低到的维度
% 输出:
% P: 投影矩阵
% r:前K个奇异值占所有奇异值的比
Cov = X*X';
[u,s] = svd(Cov) ;
P = u(:,1:K) ;
s = diag(s) ;
r = sum(abs(s(1:K)))/sum(abs(s)) ;
end
```
```matlab
PCA for image compression
clear
img = imread('xinhuan.jpg');
img = im2double(img);
K=50;
% 保留主成分个数
img_matrix = [img(:,:,1),img(:,:,2),img(:,:,3)] ;
% 将RGB三通道图像合并成一个矩阵
img_matrix_mean = img_matrix - mean(img_matrix) ;
% 求均值
Proj = fun_pca(img_matrix_mean,K) ;
% 用PCA算法获得投影矩阵P
img_K = Proj'*img_matrix_mean ;
% 压缩到K维后的图像
%% 图像重建
img_rec = Proj*img_K ;
% 图像解压缩
img_rec = img_rec + mean(img_matrix) ;
% 重建后的图像加上均值
c_n = size(img_matrix,2)/3 ;
img_rec = cat(3,img_rec(:,1:c_n),img_rec(:,c_n+1:2*c_n),img_rec(:,2*c_n+1:end)) ;
figure(1)
subplot(1,2,1)
imshow(img),title('原图')
subplot(1,2,2)
imshow(img_rec),title(strcat('压缩后的图像(', '奇异值数量:10)'))
```
```matlab
SVD for image compression
clear
img = imread('xinhuan.jpg');
img = im2double(img);
K = 10 ;
for i = 1:3
[u,s,v] = svd(img(:,:,i)) ;
s = diag(s) ;
r = sum(abs(s(1:K)))/sum(abs(s)) ;
s = diag(s(1:K)) ;
W(:,:,i) = u(:,1:K)*s*v(:,1:K)' ;
end
figure(1)
subplot(2,2,1)
imshow(img),title('原图')
subplot(2,2,2)
imshow(P),title(strcat('压缩后的图像(', '奇异值数量:10)'))
```
奇异值分解图像压缩:
 图5. SVD重构的图像与原图对比 图5. SVD重构的图像与原图对比
|
PCA图像压缩:
 图6. PCA重构的图像与原图对比 图6. PCA重构的图像与原图对比
|
从图5和图6基本看不出来PCA和SVD压缩图像有多大区别,其特征值贡献比差异很大确不能说明什么问题,图像重建质量可以使用峰值信噪比(PSNR)来评价,感兴趣的可以去试一试。
## 4. 讨论
PCA的主要优点有:
1)仅仅需要以方差衡量信息量,不受数据集以外的因素影响。
2)各主成分之间正交,可消除原始数据成分间的相互影响的因素。
3)计算方法简单,主要运算是特征值分解,易于实现。
PCA算法的主要缺点有:
1)主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
2)方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。
更多精彩内容请关注订阅号**优化与算法**和加入QQ讨论群1032493483获取更多资料


