前言:
最近几年,注意力机制用来提升模型性能有比较好的表现,大家都用得很舒服。本文将介绍一种新提出的坐标注意力机制,这种机制解决了SE,CBAM上存在的一些问题,产生了更好的效果,而使用与SE,CBAM同样简单。
论文地址:
https://arxiv.org/pdf/2103.02907.pdf
代码地址:
https://github.com/AndrewQibin/CoordAttention
大部分注意力机制用于深度神经网络可以带来很好的性能提升,但这些注意力机制用于移动网络(模型比较小)会明显落后于大网络,这主要是因为大多数注意力机制带来的计算开销对于移动网络而言是无法承受的,例如self-attention。
因此,在移动网络上主要使用Squeeze-and-Excitation (SE),BAM和CBAM。但SE只考虑内部通道信息而忽略了位置信息的重要性,而视觉中目标的空间结构是很重要的。BAM和CBAM尝试去通过在通道上进行全局池化来引入位置信息,但这种方式只能捕获局部的信息,而无法获取长范围依赖的信息。
这里稍微解释一下,经过几层的卷积后feature maps的每个位置都包含了原图像一个局部区域的信息,CBAM是通过对每个位置的多个通道取最大值和平均值来作为加权系数,因此这种加权只考虑了局部范围的信息。
在本文中提出了一种新颖且高效的注意力机制,通过嵌入位置信息到通道注意力,从而使移动网络获取更大区域的信息而避免引入大的开销。为了避免2D全局池化引入位置信息损失,本文提出分解通道注意为两个并行的1D特征编码来高效地整合空间坐标信息到生成的attention maps中。
具体而言,利用两个1D全局池化操作将沿垂直和水平方向的input features分别聚合为两个单独的direction-aware feature maps。 然后将具有嵌入的特定方向信息的这两个特征图分别编码为两个attention map,每个attention map都沿一个空间方向捕获输入特征图的远距离依存关系。 位置信息因此可以被保存在所生成的attention map中。 然后通过乘法将两个attention map都应用于input feature maps,以强调注意区域的表示。
考虑到其操作可以区分空间方向(即坐标)并生成coordinate-aware attention maps,因此论文将提出的注意力方法称为“coordinate attention”。
这种coordinate attention有三个优点:
1) 它捕获了不仅跨通道的信息,还包含了direction-aware和position-sensitive的信息,这使得模型更准确地定位到并识别目标区域。
2) 这种方法灵活且轻量,很容易插入到现有的经典移动网络中,例如MobileNet_v2中的倒残差块和MobileNeXt中的沙漏块中去提升特征表示性能。
3) 对一个预训练的模型来说,这种coordinate attention可以给使用移动网络处理的down-stream任务带来明显性能提升,尤其是那些密集预测的任务,例如语义分割。
在介绍coordinate attention前先回顾一下SE和CBAM。
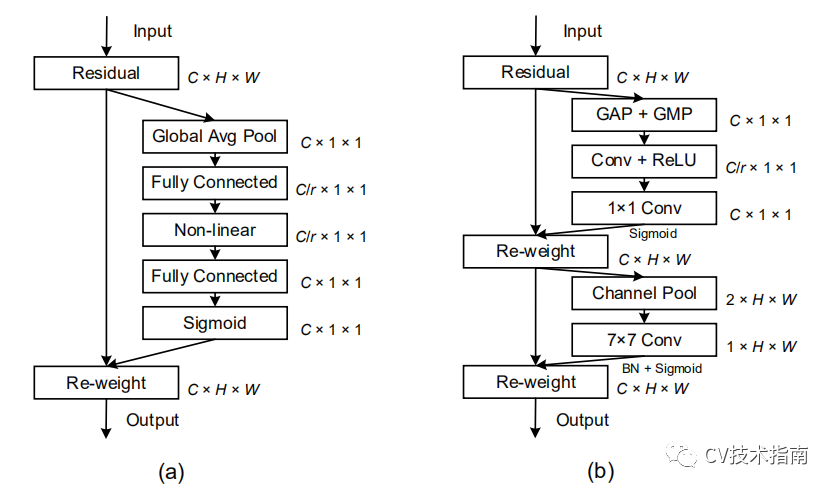

SE比较简单,如图a所示,看一下这个结构图就懂了。
稍微介绍一下CBAM,如图b所示,CBAM包含空间注意力和通道注意力两部分。
通道注意力:对input feature maps每个feature map做全局平均池化和全局最大池化,得到两个1d向量,再经过conv,ReLU,1x1conv,sigmoid进行归一化后对input feature maps加权。
空间注意力:对feature map的每个位置的所有通道上做最大池化和平均池化,得到两个feature map,再对这两个feature map进行7x7 Conv,再使BN和sigmoid归一化。
具体如下图所示:

回到Coordinate Attention上,如下图所示,分别对水平方向和垂直方向进行平均池化得到两个1D向量,在空间维度上Concat和1x1Conv来压缩通道,再是通过BN和Non-linear来编码垂直方向和水平方向的空间信息,接下来split,再各自通过1x1得到input feature maps一样的通道数,再归一化加权。
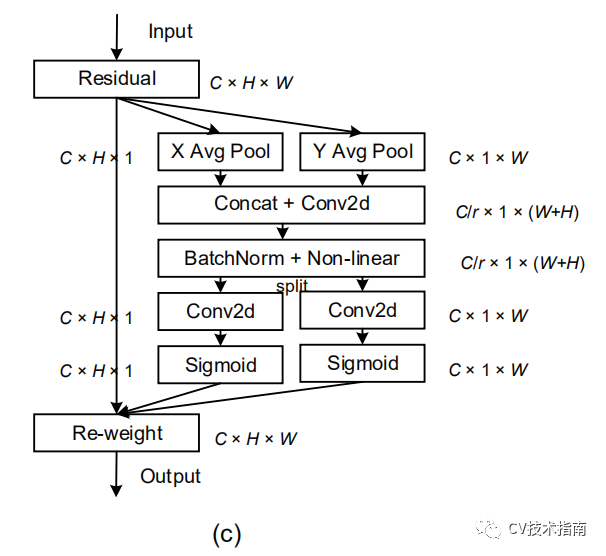
简单说来,Coordinate Attention是通过在水平方向和垂直方向上进行最大池化,再进行transform对空间信息编码,最后把空间信息通过在通道上加权的方式融合。
这种方式与SE,CBAM有明显提升。


下一篇将对注意力机制进行做一个总结。
最近把公众号所有的技术总结打包成了一个pdf,在公众号《CV技术指南》中回复关键字 “技术总结” 可获取。

本文来源于公众号CV技术指南的论文分享系列,更多内容请扫描文末二维码关注公众号。


