tensorflow中的梯度计算和更新
为了解决深度学习中常见的梯度消失(gradient explosion)和梯度爆炸(gradients vanishing)问题,tensorflow中所有的优化器tf.train.xxxOptimizer都有两个方法:
compute_gradients
对于compute_gradients方法,计算var_list中参数的梯度,使得loss变小。默认情况下,var_list为GraphKeys.TRAINABLE_VARIABLES中的所有参数。
compute_gradients方法返回由多个(gradients, variable)二元组组成的列表。
compute_gradients( loss, var_list=None, gate_gradients=GATE_OP, aggregation_method=None, colocate_gradients_with_ops=False, grad_loss=None )
apply_gradients
对于apply_gradients方法,根据compute_gradients的返回结果对参数进行更新
apply_gradients( grads_and_vars, global_step=None, name=None )
梯度裁剪(Gradient Clipping)
tensorflow中裁剪梯度的几种方式
方法一tf.clip_by_value
def clip_by_value(t, clip_value_min, clip_value_max,
name=None):
其中,t为一个张量,clip_by_value返回一个与t的type相同、shape相同的张量,但是新tensor中的值被裁剪到了clip_value_min和clip_value_max之间。
方法二:tf.clip_by_global_norm
def clip_by_global_norm(t_list, clip_norm, use_norm=None, name=None):
其中,t_list为A tuple or list of mixed Tensors, IndexedSlices, or None。clip_norm为clipping ratio,use_norm指定global_norm,如果use_norm为None,则按global_norm = sqrt(sum([l2norm(t)**2 for t in t_list]))计算global_norm。
最终,梯度的裁剪方式为

可知,如果clip_norm > global_norm, 则不对梯度进行裁剪,否则对梯度进行缩放。
scale = clip_norm * math_ops.minimum(
1.0 / use_norm,
constant_op.constant(1.0, dtype=use_norm.dtype) / clip_norm)
方法的返回值为裁剪后的梯度列表list_clipped和global_norm
示例代码
optimizer = tf.train.AdamOptimizer(learning_rate) gradients, v = zip(*optimizer.compute_gradients(loss)) gradients, _ = tf.clip_by_global_norm(gradients, grad_clip) updates = optimizer.apply_gradients(zip(gradients, v),global_step=global_step)
方法三tf.clip_by_average_norm
def clip_by_average_norm(t, clip_norm, name=None):
t为张量,clip_norm为maximum clipping value
裁剪方式如下,

其中,avg_norm=l2norm_avg(t)
方法四:tf.clip_by_norm
def clip_by_norm(t, clip_norm, axes=None, name=None):
t为张量,clip_norm为maximum clipping value
裁剪方式为
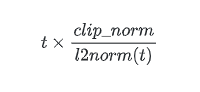
示例代码
optimizer = tf.train.AdamOptimizer(learning_rate, beta1=0.5)
grads = optimizer.compute_gradients(cost)
for i, (g, v) in enumerate(grads):
if g is not None:
grads[i] = (tf.clip_by_norm(g, 5), v) # clip gradients
train_op = optimizer.apply_gradients(grads)
注意到,clip_by_value、clib_by-avg_norm和clip_by_norm都是针对于单个张量的,而clip_by_global_norm可用于多个张量组成的列表。

