R本身已经提供了超过50个数据集,而在众多功能包中,默认的数据集被存放在datasets程序包中,通过函数data()k可以查看系统提供所有的数据包,同时可以通过函数library()加载程序包中的数据。
矩阵型数据最常用的读取方式是read.table()具体的调用格式是()
read.table(file, header = FALSE, sep = "", quote = "\"'",dec = ".", numerals = c("allow.loss", "warn.loss", "no.loss"),row.names, col.names, as.is = !stringsAsFactors,
na.strings = "NA", colClasses = NA, nrows = -1,skip = 0, check.names = TRUE, fill = !blank.lines.skip,strip.white = FALSE, blank.lines.skip = TRUE,
comment.char = "#",allowEscapes = FALSE, flush = FALSE,stringsAsFactors = default.stringsAsFactors(), fileEncoding = "", encoding = "unknown", text, skipNul = FALSE)
file是要读的数据文件名称;header = TURE表示文件第一行变化变量名,sep = ""表示文件中的分割符为空格,dec = "."用来表示小数点的字符,
row.names, col.names,用来表示向量的行名与列名, na.strings = "NA"用来表示缺失值,skip = 0跳过前几行
读入数据后,可以通过简单的函数来查看数据的基本信息。mode(),names(),dim(), 且使用attach()函数,便可以直接通过变量名来获取变量中的信息,函数detach()用于执行相反的操作。
当数据量较少时,在EXCEL中复制好要用的数据然后导入到R中。
> data.excel = read.delim("clipboard")
> data.excel
X X1 X2 value
1 1 Be Be 1.00000000
2 2 B Be -0.20154586
3 3 Mg Be -0.31724811
4 4 Al Be -0.03359098
当数据量很多时,利用RODBC软件包(提供r和各类数据库的一个借口如access和SQL server等)所提供的方法便可以实现对Excel数据的直接访问~
在实际的应用中,从网站上直接获取数据也是非常常见的,例如国家统计局官方发布的权威统计数据,中国人民银行网站发布的经济数据或其他专业财经网站提供的股市、期货、债券数据都是进行宏观数据分析工作时常用的数据源。R读取网页中的HTML表格数据,需要用到XML程序包提供的readHTMLTable()函数。
readHTMLTable(doc, header = NA,
colClasses = NULL, skip.rows = integer(), trim = TRUE,
elFun = xmlValue, as.data.frame = TRUE, which = integer(),
...)
doc给出的是HTML文件或者网页地址,which是返回网页中的那几个表格,注意如果网址较长没在输入时需要换行,使用函数gsub将字符中的换行符删去。
baseURL = gsub("\\n", "", baseURL)
数据处理的结果或者中间结果应该被妥善保存,最基本的保存工作的函数为cat()函数。
cat(... , file = "", sep = " ", fill = FALSE, labels = NULL, append = FALSE)
参数file指定了输出的文件名,若文件已存在则原来的内容将被覆盖,若将参数append = T,则是在文件末尾追加内容。
> car = file("K:/car.txt")
> cat("Make lp100km mass.kg List.price", "\"Alpha Remeo\" 9.5 1242 38500", "\"Audi A3\" 8.8 1160 38700", file = car, sep = "\n")
> close(car)

更常用的写文件方式是把一个矩阵或者数据框以矩形块的形式整体写入文件,用write.table()函数
write.table(x, file = "", append = FALSE, quote = TRUE, sep = " ", eol = "\n", na = "NA", dec = ".", row.names = TRUE,
col.names = TRUE, qmethod = c("escape", "double"), fileEncoding = "")
sum(x) 对x中的元素求加和,
prod(x)对x中的元素求乘积,
max(x)/min(x)求x中元素的最大值和最小值,
range(x)返回取值范围,相当于[min(x),max(x)],
length(x)返回x中元素的个数,
median(x)返回x中元素的中位数,
var(x)求x中元素的方差,
sd(x)求x中元素的标准差,
cov(x,y)求x和y的协方差,
cor(x,y)求x和y的相关系数,
round(x,n)对x中的元素四舍五入,保留小数点后的第n位,
sort(x)/order(x)排序,默认升序,
rev(x)对x中的元素取逆序,
unique(x)对x中重复的元素只取一个,
table(x)统计x中完全相同的数据个数。
names()函数可以获取数据集的列标签,dimnames()[[1]]表示对行标签进行操作如:dimnames()[[1]][1:3] = c("1","2","3")将数据的取1-3行的标签改为1-3,dimnames()[[2]]表示列。
> air_data = airquality[1:7,1:4] > is.na(air_data) Ozone Solar.R Wind Temp 1 FALSE FALSE FALSE FALSE 2 FALSE FALSE FALSE FALSE 3 FALSE FALSE FALSE FALSE 4 FALSE FALSE FALSE FALSE 5 TRUE TRUE FALSE FALSE 6 FALSE TRUE FALSE FALSE 7 FALSE FALSE FALSE FALSE > sum(is.na(air_data)) [1] 3 > complete.cases(air_data) [1] TRUE TRUE TRUE TRUE FALSE FALSE TRUE > complete.cases(air_data$Ozone) [1] TRUE TRUE TRUE TRUE FALSE TRUE TRUE is.na用来分析数据中是否含有缺失值,complete.cases则是判断每一行是否有缺失值,当数据量变大时,利用aggr()函数进行判断。 > air_data = airquality[1:31,1:4] > aggr(air_data, las = 1, numbers = T)
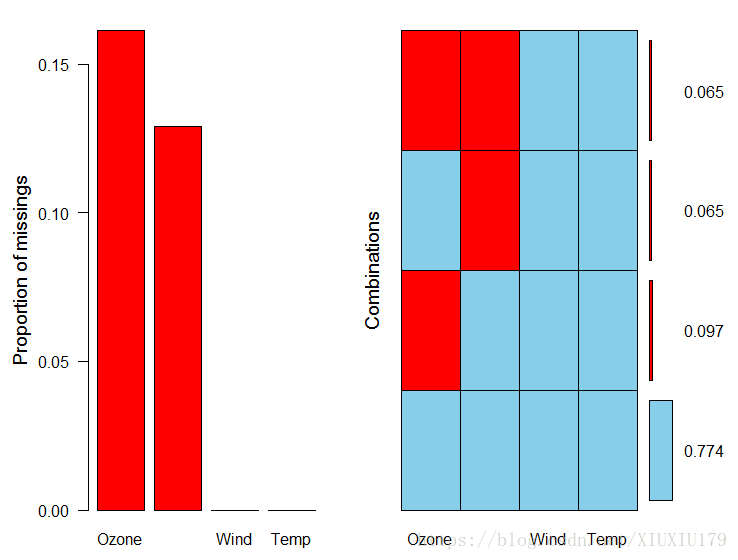
图中的的小长条的长度表示各个变量的缺失数据的比例,可见wind和temp变量数据是完整的。
> data = air_data[complete.cases(air_data),] > dim(data) [1] 24 4 > data = na.omit(air_data) > dim(data) [1] 24 4
用均值或者中位数去代替缺失值是通常的处理策略。
> air_data$Ozone[is.na(air_data$Ozone)] = median(air_data$Ozone[!is.na(air_data$Ozone)])
补充:R语言学习笔记--数据框输出和查看
write.table(C,file="ABC.csv",sep = ",",row.names=FALSE)
#ABC.csv将保存在R的工作目录下,当不加sep = " "时,输出的数据会在同一个单元格里,因此要加“,”。
行数:length(C[1, ])
列数:length(C[ ,1])
行数+列数:dim(C)
colnames(C)
length(unique(C$x1))
print()
cat ( )
换行的话加“\n”

以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。

