今天下午14:30左右,先是发现博客后台出现502(博客后台的 pod 健康检查时会连接数据库,如果连接过慢造成健康检查失败,pod 会重启,如果所有 pod 都因健康检查失败而重启,这时访问就会出现502)。过了一会,其中1个 pod 重启成功,博客后台恢复正常。
原以为只是一次短暂的波动,但随即发现博客站点响应速度变慢,难道数据库服务器又要出现 CPU 100%了,赶紧登录阿里云RDS控制台查看监控,CPU 正常,查看 CloudDBA 性能优化也没有异常的 SQL,看来数据库没出问题。
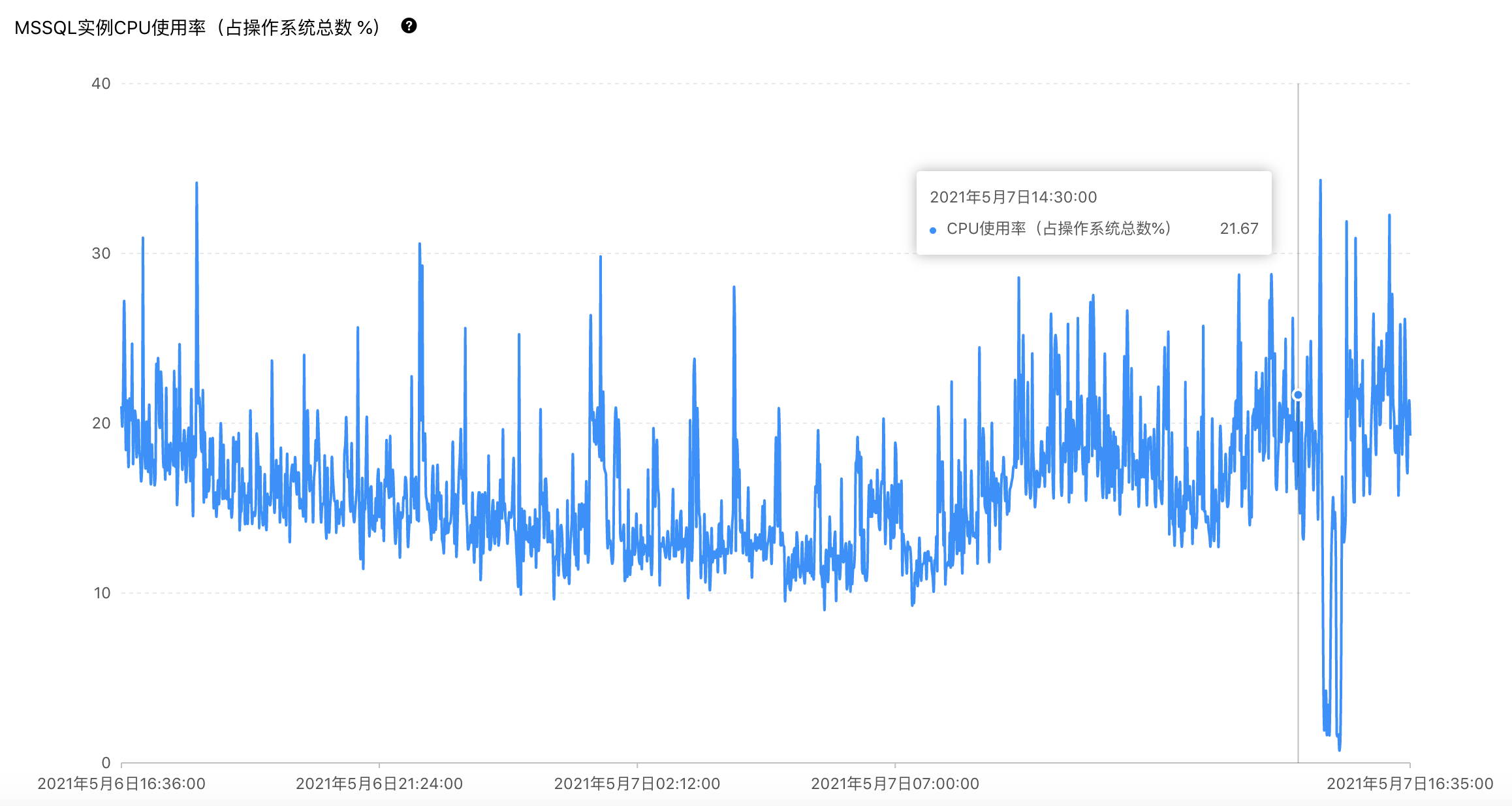
虽然貌似数据库没问题,但响应速度慢的问题越来越严重,大量请求执行缓慢,日志中记录了大量执行时间超过10秒的请求,查看数据库的其他监控指标,发现了一个异常情况,数据库连接数飙升。
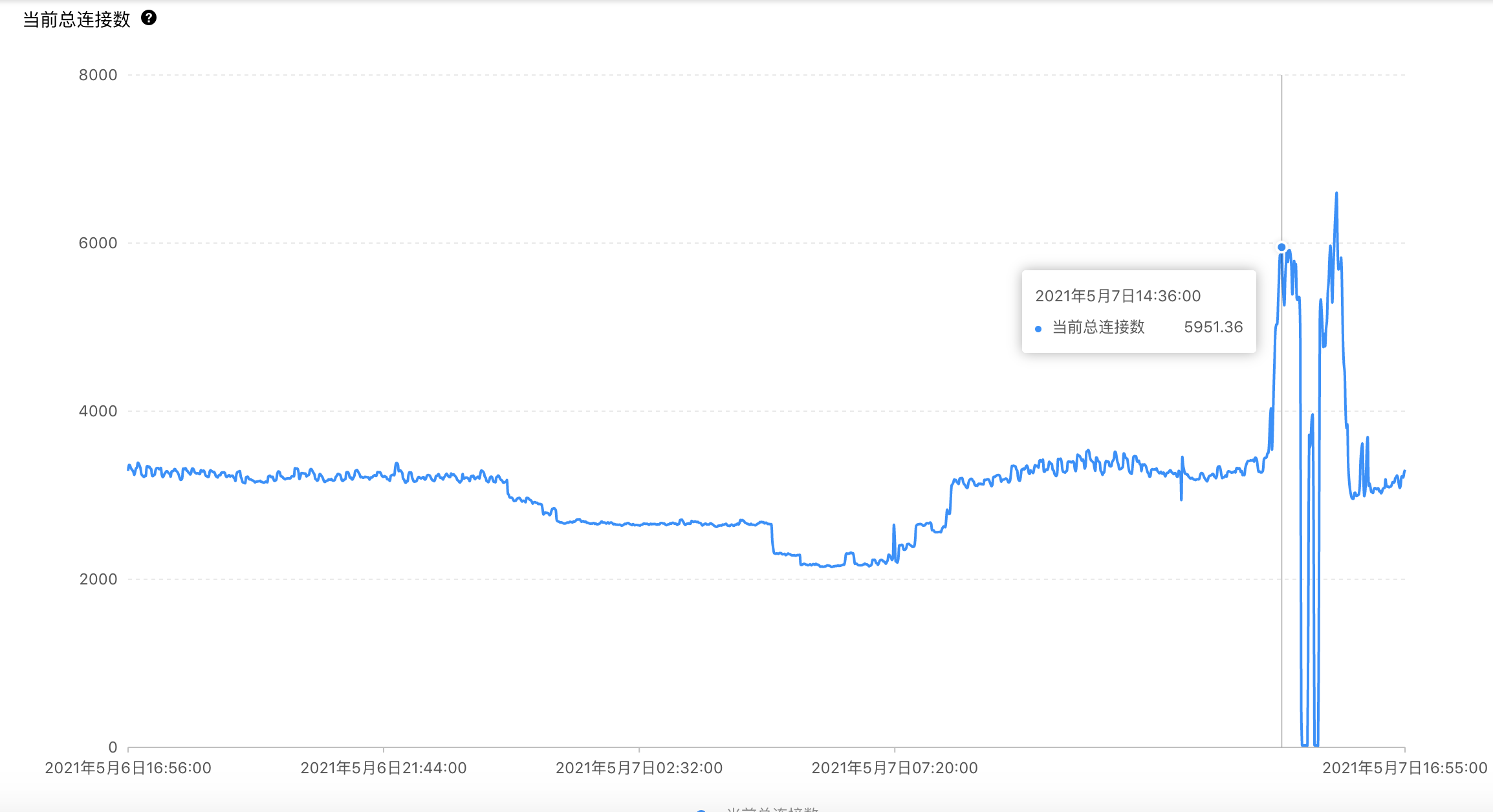
14:38 开始日志中开始出现大量连接超时的错误,这时访问园子从大量请求响应缓慢变成了大量500。
> ""Microsoft.Data.SqlClient.SqlException (0x80131904): Connection Timeout Expired. The timeout period elapsed while attempting to consume the pre-login handshake acknowledgement. This could be because the pre-login handshake failed or the server was unable to respond back in time. This failure occurred while attempting to connect to the Principle server. The duration spent while attempting to connect to this server was - [Pre-Login] initialization=15112; handshake=0;
---> System.ComponentModel.Win32Exception (258): Unknown error 258
从阿里云RDS的监控指标看,除了连接数飙升,其他指标都没有明显的异常,真不知道问题究竟出在哪里,只能拿出处理数据库故障的治标不治本的绝招——主备切换,第一次切换后问题依旧。这时你也许会想,看你每次图省事用绝招,这次不灵了吧。你太小看这个绝招了,它可以多次使用,一次不行,可以再来一次。于是,我们进行了第二次主备切换,也就是切换回原来的数据库实例,然后就恢复正常了。神奇的绝招,CPU 高用它,连接数高也可以用它。
非常抱歉,这次故障给您带来了很大的麻烦,请您谅解。
就在我们写这篇博文期间,博客后台又出现了502,而这次数据库一切正常,但博客后台的3个pod全部因健康检查失败而宕机。博客后台采用的基于k8s的蓝绿部署,之前版本的pod还在运行中,于是切换到之前的pod恢复正常,之前的pod与502的pod主要不同之处是部署不同的k8s节点上,问题比想象的还要诡异。
注:我们的数据库服务器用的是阿里云 RDS SQL Server 2016 标准版,16核CPU,32G内存。应用部署在用阿里云服务器自己搭建的 Kubernetes 集群上。

