在看CS231n的时候,有这么一行代码
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
查了查np.nditer原来是numpy array自带的迭代器。这里简单写个demo解释一下np.nditer的用法。


flags=['multi_index']表示对a进行多重索引,具体解释看下面的代码。
op_flags=['readwrite']表示不仅可以对a进行read(读取),还可以write(写入),即相当于在创建这个迭代器的时候,我们就规定好了有哪些权限。

print it.multi_index表示输出元素的索引,可以看到输出的结果都是index。
it.iternext()表示进入下一次迭代,如果不加这一句的话,输出的结果就一直都是(0, 0)。
补充:it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
在看cs221n代码的时候碰到一行代码。
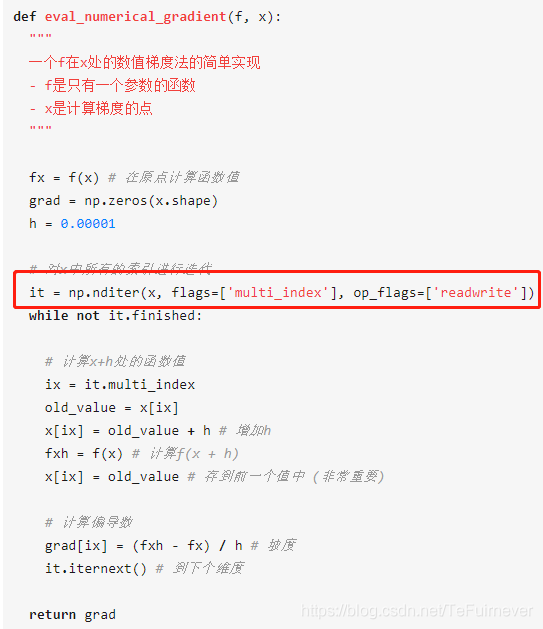
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
class np.nditer()
op : ndarray或array_like的序列。迭代的数组。
flags : str的序列,可选。用于控制迭代器行为的标志。
“buffered”可在需要时启用缓冲。
“c_index”导致跟踪C顺序索引。
“f_index”导致跟踪Fortran-order索引。
“multi_index”导致跟踪多个索引或每个迭代维度一个索引元组。
“common_dtype”会将所有操作数转换为公共数据类型,并根据需要进行复制或缓冲。
“copy_if_overlap”使迭代器确定读操作数是否与写操作数重叠,并根据需要进行临时复制以避免重叠。在某些情况下,可能会出现误报(不必要的复制)。
“delay_bufalloc”延迟缓冲区的分配,直到进行reset()调用。允许“allocate”操作数在其值复制到缓冲区之前进行初始化。
“external_loop”导致给定的值是具有多个值的一维数组,而不是零维数组。
当同时使用“buffered”和“external”循环时,“grow-inner”允许值数组大小大于缓冲区大小。
“ranged”允许将迭代器限制为iterindex值的子范围。
“refs_ok”允许迭代引用类型,例如对象数组。
“reduce_ok”允许迭代广播的“readwrite”操作数,也称为缩减操作数。
“zerosize_ok”允许itersize为零。
op_flags : str列表,可选。这是每个操作数的标志列表。至少,必须指定“readonly”,“readwrite”或“writeonly”中的一个。
“readonly”表示只读取操作数。
“readwrite”表示将读取和写入操作数。
“writeonly”表示只会写入操作数。
“no_broadcast”阻止操作数被广播。
“contig”强制操作数数据是连续的。
“aligned”强制操作数数据对齐。
“nbo”强制操作数数据以本机字节顺序排列。
如果需要,“copy”允许临时只读副本。
“updateifcopy”允许在需要时使用临时读写副本。
如果在op参数中为None,则“allocate”会导致分配数组。
“no_subtype”阻止“allocate”操作数使用子类型。
“arraymask”表示此操作数是在写入设置了“writemasked”标志的操作数时用于选择元素的掩码。迭代器不强制执行此操作,但是当从缓冲区写回数组时,它只复制由此掩码指示的元素。
'writemasked'表示只写入所选'arraymask'操作数为True的元素。
“overlap_assume_elementwise”可用于标记仅在迭代器顺序中访问的操作数,以便在存在“copy_if_overlap”时允许不太保守的复制。
op_dtypes : dtype的dtype 或tuple,可选。操作数所需的数据类型。如果启用了复制或缓冲,则数据将转换为原始类型或从其原始类型转换。
order: {‘C',‘F',‘A',‘K'},可选
控制迭代顺序。'C'表示C顺序,'F'表示Fortran顺序,'A'表示'F'顺序,如果所有数组都是Fortran连续,否则'C'顺序,‘K'表示接近数组元素出现的顺序在内存中尽可能。这也会影响“allocate”操作数的元素内存顺序,因为它们被分配为与迭代顺序兼容。默认为'K'。
casting :{‘no', ‘equiv', ‘safe', ‘same_kind', ‘unsafe'},可选。控制进行复制或缓冲时可能出现的数据转换类型。建议不要将此设置为“unsafe”,因为它会对累积产生不利影响。
“no”表示完全不应强制转换数据类型。
“equiv”表示只允许更改字节顺序。
“safe”表示只允许保留值的强制转换。
“same_kind”意味着只允许安全的类型或类型内的类型,如float64到float32。
“unsafe”表示可以进行任何数据转换。
op_axes : 整数列表列表,可选。如果提供,则是每个操作数的int或None列表。操作数的轴列表是从迭代器的维度到操作数的维度的映射。可以为条目放置值-1,从而将该维度视为“newaxis”。
itershape : 整数元组,可选。迭代器的理想形状。这允许“allocate”具有由op_axes映射的维度的操作数不对应于不同操作数的维度,以获得该维度不等于1的值。
buffersize : int,可选。启用缓冲时,控制临时缓冲区的大小。设置为0表示默认值。
默认情况下,nditer将视待迭代遍历的数组为只读对象(read-only),为了在遍历数组的同时,实现对数组元素值得修改,必须指定op_flags=['readwrite']模式:
基本迭代参数flag=['f_index'/'mulit_index'],可输出自身坐标it.index/it.multi_index。
“multi_index”表示对x进行表示对x进行多重索引。
print("%d <%s>" % (it[0], it.multi_index))表示输出元素的索引,可以看到输出的结果都是index。
下面分别举例子说明:
import numpy as np
x = np.arange(6).reshape(2,3)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
print("%d <%s>" % (it[0], it.multi_index))
it.iternext()
# 0 <(0, 0)>
# 1 <(0, 1)>
# 2 <(0, 2)>
# 3 <(1, 0)>
# 4 <(1, 1)>
# 5 <(1, 2)>
it.iternext()表示进入下一次迭代,如果不加这一句的话,输出的结果就一直都是0 <(0, 0)>且不间断地输出。
0 <(0, 0)> 0 <(0, 0)> 0 <(0, 0)> 0 <(0, 0)> 0 <(0, 0)> 0 <(0, 0)> ...... ......
import numpy as np
x = np.arange(6).reshape(2,3)
# 单维迭代
it = np.nditer(x, flags=['f_index'])
while not it.finished:
print("%d <%s>" % (it[0], it.index))
it.iternext()
# 0 <0>
# 1 <2>
# 2 <4>
# 3 <1>
# 4 <3>
# 5 <5>
import numpy as np
x = np.arange(6).reshape(2,3)
# 多维迭代
it = np.nditer(x, flags=['multi_index'])
while not it.finished:
print("%d <%s>" % (it[0], it.multi_index))
it.iternext()
# 0 <(0, 0)>
# 1 <(0, 1)>
# 2 <(0, 2)>
# 3 <(1, 0)>
# 4 <(1, 1)>
# 5 <(1, 2)>
import numpy as np
x = np.arange(6).reshape(2,3)
# 列顺序迭代
it = np.nditer(x, flags=['f_index'], order='F')
while not it.finished:
print("%d <%s>" % (it[0], it.index), end=' | ')
it.iternext()
# 0 <0> | 3 <1> | 1 <2> | 4 <3> | 2 <4> | 5 <5> |
import numpy as np
x = np.arange(6).reshape(2,3)
# 行顺序迭代
it = np.nditer(x, flags=['f_index'], order='C')
while not it.finished:
print("%d <%s>" % (it[0], it.index), end=' | ')
it.iternext()
# 0 <0> | 1 <2> | 2 <4> | 3 <1> | 4 <3> | 5 <5> |
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。

