NameError: name 'unicode' is not defined
There is no such name in Python 3, no. You are trying to run Python 2 code in Python 3. In Python 3, unicode has been renamed to str.
翻译过来就是:Python 3中没有这样的名字,没有。 您正在尝试在Python 3中运行Python 2代码。在Python 3中,unicode已重命名为str。
函数转换:unicode()到 str()为:
//python2: unicode(nn,'utf-8') //python3: str(nn)
补充:根本解决Python2中unicode编码问题
Python2中编码问题
因为计算机只识别01这要的二进制,所以在计算机存储我们的文件时,要使用二进制数来表示。所以编码就是哪个二进制数表示哪个字符:
编码原由系统编码、文件编码与python系统编码Python字符编码python中的字典、数组转字符串中的中文编码
ASCII编码
最早出现的是ASCII码,使用8位二进制数组合表示128种字符。因为ASCII编码是美国人发明的,当初没考虑给别的国家用,所以,它仅仅表示了所有美式英语的语言字符。但是没有使用完。
ISO 8859-1/windows-1252
128位字符满足了美国人的需求,但是随之欧洲人加入互联网,为了满足欧洲人的需求,8位二进制后面还有128位。这一段编码我们称之扩展字符集,即ISO 8859-1编码标准,后来欧洲的需求变更,即规定了windows-1252代替了ISO 8859-1
GB2312
然后当我国加入后,8位二进制(即一个字节)用完了,于是我们保留ASCII编码即前128位,后面的全部删除。因为我国得语言博大精深,所以需要2个字节,即16位才能满足我们得需求,所以当计算机遇到大于127的字节时,就一次性读取两个字节,将他解码成汉字。即GB2312编码
GBK
相当于GB2312的改进版,增添了中文字符。但还是2个字节表示汉字
GB18030
为了满足日韩和我国的少数民族的需求,对GBK的改进,使用变长编码,要么使用两个字节,要么使用四个字节。
Unicode
虽然每种编码都兼容ASCII编码,但是各个国家是不兼容的。于是出现了Unicode,它将所有的编码进行了统一。它不能算是一种具体的编码标准,只是将全世界的字符进行了编号,并没有指定他们具体在计算机种以什么样的形式存储。
它的具体实现有UTF-8,UTF-16,UTF-32等。
在linux中获取系统编码结果:

Windows系统的编码,代码页936表示GBK编码
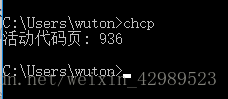
可以看到linux系统默认使用UTF-8编码,windows默认使用GBK编码。Linux环境下,文件默认使用UTF-8编码。当然你也可以指定文件编码方式。
Python解释器内部默认使用的ASCII编码方式去解读python源文件。
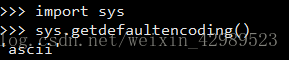
所以当文件内存在非ASCII字符时,python解释器无 法识别,就会出现编码错误。

So,这个时候需要告诉python解释器用utf-8去解读python源文件
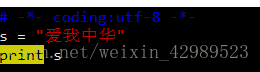

Python2中有两类字符串,分别是str与unicode。这两类字符串都派生自抽象类basestring。 Str即普通字符串类型
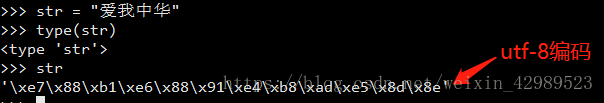
在字符串前加上u即unicode编码

在代码中通常用到的是unicode,文件保存的是utf-8编码。Unicode编码是固定2个字节代表一个字符。Utf-8是对英文只用一个字节,对中文是3个字节。所以unicode运行效率高,utf-8运行效率相比要低,但是空间存储要小。
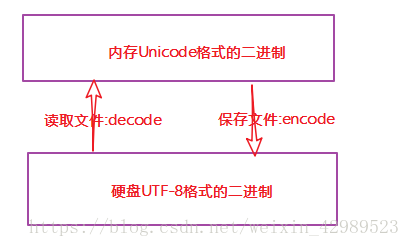
Python中str与unicode转换
Unicode转str
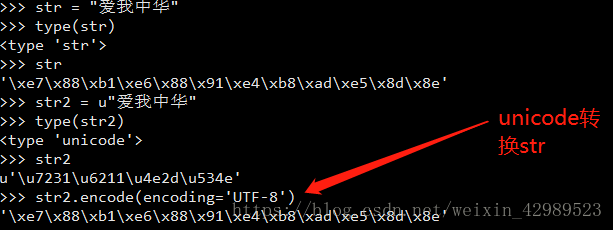
str转unicode

其函数中参数UTF-8是,以utf-8编码对unicode对象解码,或编码。
当字典中的中文字符是unicode类型时
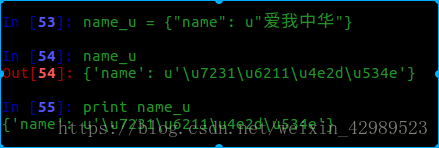
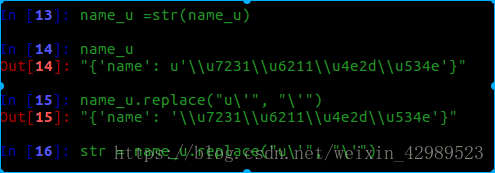

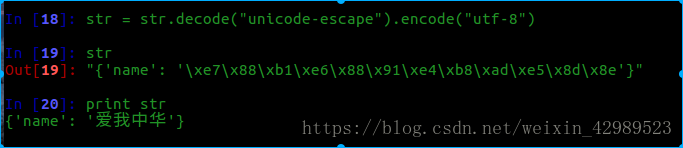
decode(“unicode-escape”)相当是反向编码.然后再进行utf-8编码即可
当字典中的字符串是string类型时
name = {"name": "中国"}
name = str(name)
print name.decode("string-escape")

当数组进行字符串化时
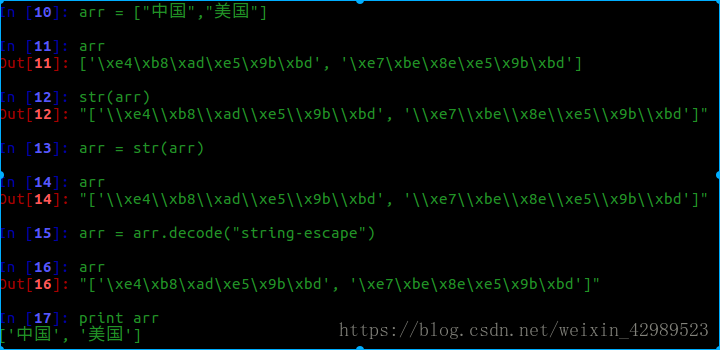
不管是数组还是字典,在进行字符串转换是,即是又一次编码,所以,对于本身还有的中文字符串又一次编码,所以要进行一次反编码,才能看到原有的编码。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。

