贝叶斯分类算法是统计学的一种分类方法,它是一类利用概率统计知识进行分类的算法。在许多场合,朴素贝叶斯(Naïve Bayes,NB)分类算法可以与决策树和神经网络分类算法相媲美,该算法能运用到大型数据库中,而且方法简单、分类准确率高、速度快。
由于贝叶斯定理假设一个属性值对给定类的影响独立于其它属性的值,而此假设在实际情况中经常是不成立的,因此其分类准确率可能会下降。为此,就衍生出许多降低独立性假设的贝叶斯分类算法,如TAN(tree augmented Bayes network)算法。
那么既然是朴素贝叶斯分类算法,它的核心算法又是什么呢?
是下面这个贝叶斯公式:
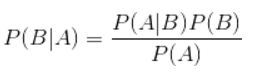
换个表达形式就会明朗很多,如下:
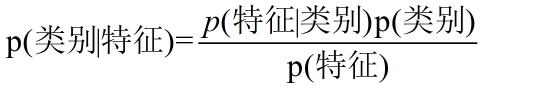
我们最终求的p(类别|特征)即可!就相当于完成了我们的任务。
下面以女生找对象举例,提取除女生找对象的几个关键特征,比如颜值,性格,身高,上进心,资产情况为择偶特征,通过事先调研等手段,获取一部分数据样本,即各类特征以及择偶结果(分类)数据集。根据数据集利用朴素贝叶斯函数计算出个各个特征集合在该分类下的值,结果值最大的分类,认为该数据属于这个分类。由于这个是利用概率学去计算得出的,不一定十分准确,数据集样本数据越大,准确率就越高。
下面数据集每行代码一条样本数据,每条数据中的具体特征用逗号“,” 分割,特征顺寻依次为
颜值,性格,身高,上进心,资产情况,女生中意结果
帅,好,高,上进,有钱,中意
不帅,好,高,上进,有钱,中意
帅,不好,高,上进,有钱,中意
帅,好,不高,上进,有钱,中意
帅,好,高,不上进,有钱,中意
帅,好,高,上进,不有钱,中意
帅,好,不高,不上进,有钱,不中意
不帅,不好,不高,上进,有钱,中意
不帅,不好,不高,上进,不有钱,不中意
帅,好,不高,上进,不有钱,中意
不帅,好,高,不上进,有钱,不中意
帅,不好,高,上进,有钱,不中意
不帅,好,高,上进,有钱,不中意
帅,不好,高,上进,不有钱,中意
帅,不好,高,不上进,有钱,中意
帅,好,高,上进,不有钱,不中意
帅,不好,不高,不上进,不有钱,不中意
不帅,不好,不高,不上进,不有钱,不中意
帅,好,不高,上进,有钱,中意
不帅,不好,不高,不上进,有钱,不中意
帅,好,高,上进,不有钱,中意
帅,好,不高,不上进,有钱,中意
帅,好,高,不上进,不有钱,不中意
帅,不好,高,不上进,有钱,不中意
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.*;
import java.util.stream.Collectors;
/**
* @author liuya
*/
public class NaiveBayesModel {
//样本数据
private static List<List<String>> data = new ArrayList<>();
//样本数据
private static Set<List<String>> dataSet = new HashSet<>();
//分类模型
public static Map<String,String> modelMap = new HashMap<>();
//样本数据集
private static String path = "./src/data.txt";
public static void main(String[] args) {
//训练模型
trainingModel();
//识别
classification("帅","好","高","上进","有钱");
classification("不帅","不好","不高","不上进","不有钱");
}
/**
* 导入数据
* @param path
* @return
*/
public static void readData(String path){
List<String> row = null;
try {
InputStreamReader isr = new InputStreamReader(new FileInputStream(new File(path)));
BufferedReader br = new BufferedReader(isr);
String str = null;
while((str = br.readLine()) != null){
row = new ArrayList<>();
String[] str1 = str.split(",");
for(int i = 0; i < str1.length ; i++) {
row.add(str1[i]);
}
dataSet.add(row);
data.add(row);
}
br.close();
isr.close();
} catch (Exception e) {
e.printStackTrace();
System.out.println("读取文件内容出错!");
}
}
public static void trainingModel() {
readData(path);
String category1="中意";
String category2="不中意";
dataSet.forEach(e->{
double categoryP1= calculateBayesian(e.get(0),e.get(1),e.get(2),e.get(3),e.get(4),category1);
double categoryP2= calculateBayesian(e.get(0),e.get(1),e.get(2),e.get(3),e.get(4),category2);
String result=categoryP1>categoryP2?category1:category2;
modelMap.put(e.get(0)+"-"+e.get(1)+"-"+e.get(2)+"-"+e.get(3)+"-"+e.get(4),result);
});
}
/**
* 分类的识别
* */
public static void classification(String look, String character, String height, String progresses, String wealthy){
String key=look+"-"+character+"-"+height+"-"+progresses+"-"+wealthy;
String result=modelMap.get(key);
System.out.println("特征为"+look+","+character+","+height+","+progresses+","+wealthy+"的对象,女生"+result);
}
/**
* 分类的核心是比较朴素贝叶斯的结果值,结果值大的认为就属于该分类(会有误差,数据集量越大,结果判定的准确率就会越高)由于分母相同可以直接比较分子来确定分类
* */
public static double calculateBayesian(String look, String character, String height, String progresses, String wealthy,String category) {
//获取P(x|y)的分母
// double denominator = getDenominator(look,character,height,progresses,wealthy);
//获取P(x|y)的分子
double molecule = getMolecule(look,character,height,progresses,wealthy,category);
return molecule/1;
}
/**
* 获取p(x|y)分子
* @return
*/
public static double getMolecule(String look, String character, String height, String progresses, String wealthy,String category) {
double resultCP = getProbability(5, category);
double lookCP = getProbability(0, look, category);
double characterCP = getProbability(1, character, category);
double heightCP = getProbability(2, height, category);
double progressesCP = getProbability(3, progresses, category);
double wealthyCP = getProbability(4, wealthy, category);
return lookCP * characterCP * heightCP * progressesCP * wealthyCP * resultCP;
}
/**
* 获取p(x|y)分母
* @return
*/
public static double getDenominator(String look, String character, String height, String progresses, String wealthy) {
double lookP = getProbability(0, look);
double characterP = getProbability(1, character);
double heightP = getProbability(2, height);
double progressesP = getProbability(3, progresses);
double wealthyP = getProbability(4, wealthy);
return lookP * characterP * heightP * progressesP * wealthyP;
}
/**
* 获取某特征的概率
* @return
*/
private static double getProbability(int index, String feature) {
int size = data.size();
int num = 0;
for (int i = 0; i < size; i++) {
if (data.get(i).get(index).equals(feature)) {
num++;
}
}
return (double) num / size;
}
/**
* 获取某类别下某特征的概率
* @return
*/
private static double getProbability(int index, String feature, String category) {
List<List<String>> filterData=data.stream().filter(e -> e.get(e.size() - 1).equals(category)).collect(Collectors.toList());
int size =filterData.size();
int num = 0;
for (int i = 0; i < size; i++) {
if (data.get(i).get(index).equals(feature)) {
num++;
}
}
return (double) num / size;
}
}
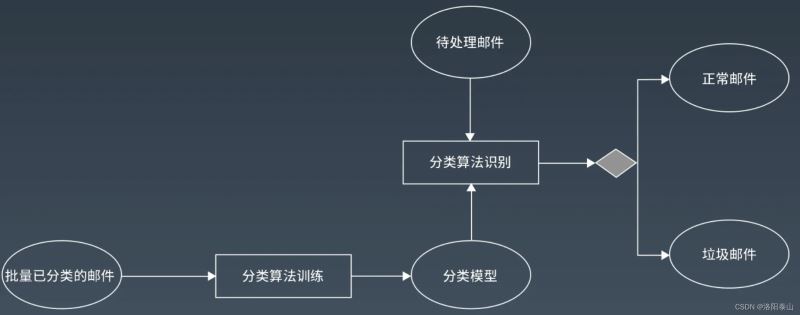
比如网站垃圾信息分类,文章自动分类,网站垃圾邮件分类,文件分类等。
以反垃圾啊邮件为例说明分类算法的使用,先将批量已经分类的邮件样本(如5000封正常的邮件,2000封垃圾邮件),输入分类算法进行训练,得到一个垃圾邮件分类模型,然后利用分类算法结合分类模型对待处理邮件进行分类识别。
根据已经分类的样本信息提取出一组特征信息的概率,比如邮件中“信用卡”这个词出现在垃圾邮件的中的概率为20%,在非垃圾邮件的概率为1%,就得到一个分类模型。然后从待识别处理的邮件中提取特征值,结合分类模型,就可以判断其分类是不是垃圾邮件。由于贝叶斯算法得到的分类判断是概率值,所以可能会出现误判。