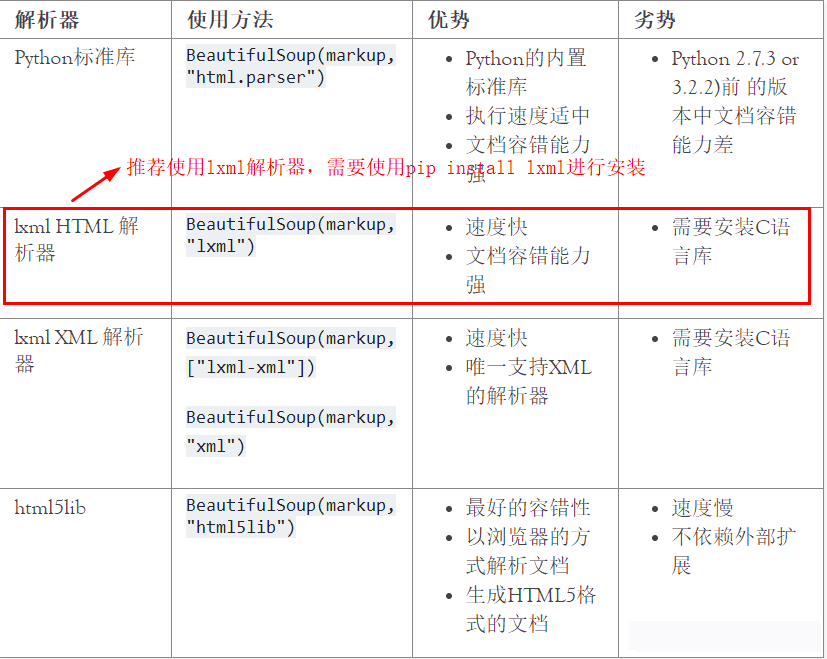
简述bs4:使用pip install beautifulsoup4将bs4包安装到当前的python解释器环境,使用from bs4 import BeautifulSoup导入BeautifulSoup类,进而生成BeautifulSoup类实例并调用实例相应的属性和方法。
bs类似于正则查询字符串,不过不需要我们自己写正则表达式,bs4已经将处理爬虫数据时的实际问题进行了统一归类并提出了解决方法,即:将处理html文档字符串时遇到的问题进行简化并给出api,以便于对html字符串文档进行信息提取和筛选(不需要自己写正则了)。
Beatifil soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要机取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiul Soup自动将输入文档转换为Unicode编码,输出文档转换为utf8编码。你不需要考虑编码方式,除非文档有指定一个编码方式,这时,Beautiful soup就不能自动识别编码方了。然后,你仅仅需要说明—下原始编码方式就可以了。一般的编码为:utf8,gb2312等。
Beautiful Soup已成为和bxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策胳或强劲的速度。
总结:Beautiful Soup依据给定的解释器来解析html文档,其依据html中标签把html文档在内存中转化为类似于二叉树的数据结构,并通过实现的查询方法来查询二叉树以得到我们想要的爬虫数据。也就是Beautiful Soup专门用于处理html这种有着规范格式的文档字符串,他会自动补全html标签以及根据标签层级结构进行文档格式化,使其更美观,而且支持query各种标签。
# soup对象 = BeautifulSoup(爬取得到的文档字符串, 解析器) soup = BeautifulSoup(html, 'lxml')
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , Navigablestring , BeautifulSoup , Comment .

具体指代如下:BeautifulSoup指代整个html文档,即document。
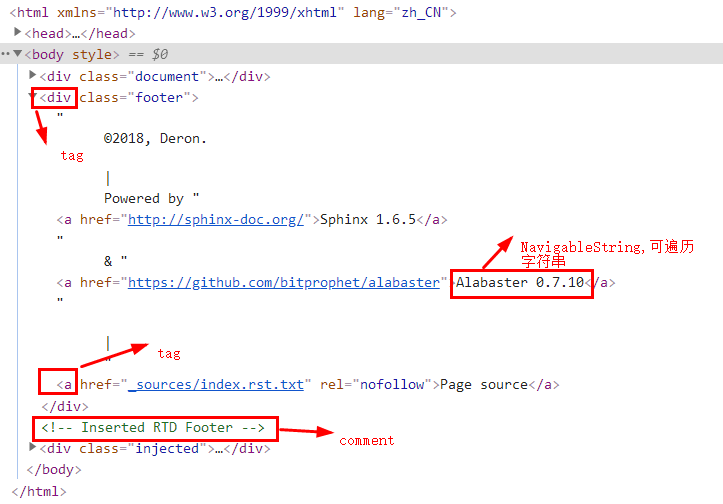
tag为一个统称,可以具体为html的各种标签,如h1-h6,div,a……等。实际上tag与一个节点对象绑定,这个节点对象拥有string,name,parent,attrs等属性,指代一个html标签。注:只有第一个先出现的tag会被捕捉到。
详细如下图:
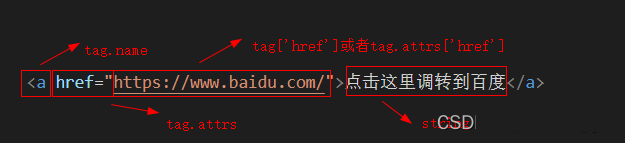
举例如下:
soup = BeautifulSoup(html, 'lxml')
title = soup.title # 获取文档的标题,并与变量title绑定
# tag对象常见的属性如下:
title.name # 返回当前tag的标签名称,该属性可读写
title.string # 获取当前tag的navigatiblestring对象
title.parent # 获取当前tag的父节点
title.attrs # 获取当前tag的属性字典
# tag对象常见的方法如下:
title.get('class') # 括号里面写属性名称,title.get('属性名称')
title.get('href')
title.get_text() # 获取tag的元素内容,与string一模一样用于打印整个格式化之后的html文档,会自动补全缺少的标签。
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b id="boldest"> ','lxml')
soup.prettify()
soup.prettify
# 上面两个等价
属性可以通过tag['key']来读取,也可以用一个全新的变量来绑定tag的attrs属性进行访问。或者使用tag.get(attr_name)来获取属性的value。另外attrs是一个字典,支持字典的增删改查等操作,从而操作tag的属性。
多值属性指的是某些标签属性如class,charset……等具有多个属性值,如:<class="mmd mmd2 mmd3">,对于这种标签,bs将他们的属性值放在一个list中。而如id等属性只有一个值,他们的属性值为str类型。多值属性列表会自动转换为html里面的多值属性语法格式。
css_soup = BeautifulSoup('<p class="body"></p>')
css_soup.p['class']
# ["body"]
id_soup = BeautifulSoup('<p id="my id"></p>')
id_soup.p['id']
# 'my id'一般指tag.string,他是一个伪字符串对象,使用str()将其转换为python的字符串即可。转换之后本质上等同于python的字符串类型。所有字符串的属性及对字符串的方法都对其适用。
也可以不使用str()转换,直接使用tag.text就是一个字符串。
他指代某个标签里面的文字内容,而不包括里面嵌套的标签。由于其类似字符串,所以无法修改,但是可以使用replace_with() 方法将其修改为其他字符串。
from bs4 import BeautifulSoup
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>','lxml')
tag = soup.b
print(tag.string)
print(type(tag.string))
# Extremely bold
# <class 'bs4.element.NavigableString'>
#---------------------------------------------------#
unicode_string = str(tag.string)
print(unicode_string)
print(type(unicode_string))
# Extremely bold
# <class 'str'>
#---------------------------------------------------#
tag.string.replace_with("No longer bold")
print(tag)
# No longer bold了解即可。beautiful soup对象指代document文档对象,本质上也是一个tag;comment指代html文档中的注释内容,是一种特殊的 NavigableString对象,实际中应注意注释混在元素内容之中,造成数据污染。
说其是一种特殊的 NavigableString对象,是因为:tag.string可以为一个 NavigableString对象,也有可能为一个comment对象。但是一般使用tag.string来访问元素内容,而不是元素里面的注释。
使用tag.prettify属性来打印出某个tag里面的所有内容,来判断使元素内容还是注释。
使用bs最重要的部分就是标签定位,定位之后才能获取得到我们想要的数据。各种定位方法都是基于对html解析树的操作,类似于二叉树从一个节点向四周寻找节点。所有我们需要做的就是:先定位到一个容易定位的二叉树节点,再从这个节点定位到我们需要的节点。或者使用css选择器精准定位。
官方名字为过滤器,实际上就是通过正则匹配到我们想要的字符串。下面只介绍find_all(),find只能找一个,一般不使用。
需要注意find_all()的参数,可以是一个tag_name,一个正则对象,一个列表(如,['div','a']),一个keyword(如,id="mmd"),一个True……
具体用法如下图:
tag
soup.find_all('b')
# [<b>The Dormouse's story</b>]
正则
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
# body
# b
列表
soup.find_all(["a", "b"])
# [<b>The Dormouse's story</b>,
# <a class="sister" href="http://example.com/elsie" rel="external nofollow" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" rel="external nofollow" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" rel="external nofollow" id="link3">Tillie</a>]
True
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
方法
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
soup.find_all(has_class_but_no_id)
# [<p class="title"><b>The Dormouse's story</b></p>,
# <p class="story">Once upon a time there were...</p>,
# <p class="story">...</p>]常用写法:

参数是一个css选择器。 与前端css中的各种选择器一模一样,这个比find_all()更加常用,毕竟与前端比较类似,容错率高。
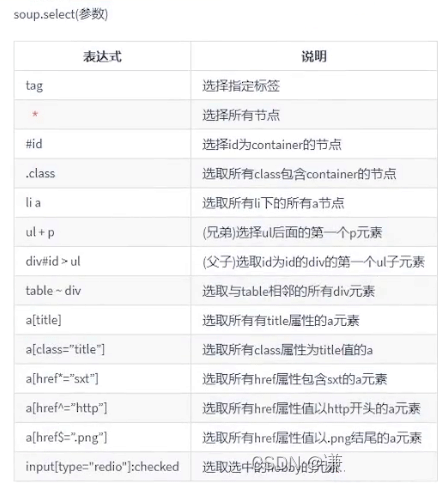
soup.select("title")
# [<title>The Dormouse's story</title>]
soup.select("p:nth-of-type(3)")
# [<p class="story">...</p>]参看官方文档,bs4官方文档。
上面的selec和find_all()基本上能够定位到任何位置了,不需要找爸爸找儿子这种形式去定位了。

