在许多自动化任务中,我们都需要从已知格式结构化的输入文本中提取相关信息。例如,我们可能需要在一段电影评论数据中提取观影时间、电影名、评分等信息,以便存储后进行进一步分析。在本节中,我们将以提取电影评论数据信息为例讲解如何从结构化字符串中提取数据。
假设我们具有以下结构的电影评分数据,我们需要解析存储观影时间、电影名、评分等信息:
[<Timestamp>] - MOVIE ID: <movie id> - MOVIE NAME: <movie name> - SCORE: <score of the movie>
例如,一条可能的电影评分记录如下所示:
[2022-08-01T11:58:41.504054] - MOVIE ID: 00015 - MOVIE NAME: Inception - SCORE: 8.5
其中,我们使用标准格式表示时间和日期,这在计算机中广泛应用。
首先,导入所需库,并给出所需解析的用户对电影的评分记录:
>>> import delorean >>> from decimal import Decimal >>> text = '[2022-08-01T11:58:41.504054] - MOVIE ID: 00015 - MOVIE NAME: Inception - SCORE: 8.5'
将评分记录使用 split() 方法拆分为多个部分,我们使用 “-” 作为分隔符拆分每个元素,将评分记录拆分为 4 部分——时间戳、电影 ID、电影名和电影评分,便于之后将它们解析为正确的类型:
>>> divided_text = text.split(' - ')
>>> divided_text
['[2022-08-01T11:58:41.504054]', 'MOVIE ID: 00015', 'MOVIE NAME: Inception', 'SCORE: 8.5']
>>> timestamp, movie_id, movie_name, score = divided_text将时间戳解析为 datetime 对象。由于在评分记录中时间戳包含在方括号中,为了正确解析时间戳,需要去掉括号,然后使用 delorean 模块将其解析为日期时间对象:
>>> timestamp = delorean.parse(timestamp.strip('[]'))
>>> timestamp
Delorean(datetime=datetime.datetime(2022, 1, 8, 11, 58, 41, 504054), timezone='UTC')将 movie_id 解析为整数。为了解析电影 ID,需要使用冒号作为分隔符拆分 movie_id,然后,将最后一个元素解析为整数:
>>> movie_id = int(movie_id.split(':')[-1])
>>> movie_id
15将评分解析为 Decimal 类型。为了解析电影评分,我们同样使用冒号作为分隔符拆分 score,并将其解析为十进制字符对象 Decimal (这是由于此值解析为浮点类型会改变精度):
>>> score = Decimal(score.split(':')[-1])
>>> score
Decimal('8.5')为了便于解析和聚合,我们可以将所解析的数据组合在一起成为一个对象。例如,我们可以通过在 Python 代码中定义一个类,来方便的解析和聚合结构化字符串中的数据:
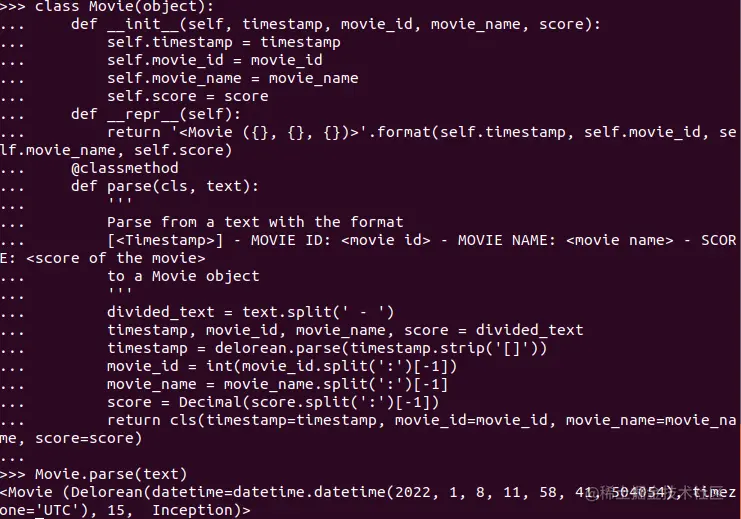
class Movie(object):
def __init__(self, timestamp, movie_id, movie_name, score):
self.timestamp = timestamp
self.movie_id = movie_id
self.movie_name = movie_name
self.score = score
def __repr__(self):
return '<Movie ({}, {}, {})>'.format(self.timestamp, self.movie_id, self.movie_name, self.score)
@classmethod
def parse(cls, text):
'''
Parse from a text with the format
[<Timestamp>] - MOVIE ID: <movie id> - MOVIE NAME: <movie name> - SCORE: <score of the movie>
to a Movie object
'''
divided_text = text.split(' - ')
timestamp, movie_id, movie_name, score = divided_text
timestamp = delorean.parse(timestamp.strip('[]'))
movie_id = int(movie_id.split(':')[-1])
movie_name = movie_name.split(':')[-1]
score = Decimal(score.split(':')[-1])
return cls(timestamp=timestamp, movie_id=movie_id, movie_name=movie_name, score=score)定义 Movie 类完成后,我们可以使用以下方式方便的对评分记录进行解析:
>>> Movie.parse(text) <Movie (Delorean(datetime=datetime.datetime(2022, 1, 8, 11, 58, 41, 504054), timezone='UTC'), 15, Inception)>