很多时候需要对自己模型进行性能评估,对于一些理论上面的知识我想基本不用说明太多,关于校验模型准确度的指标主要有混淆矩阵、准确率、精确率、召回率、F1 score。另外还有P-R曲线以及AUC/ROC,这些我都有写过相应的理论和具体理论过程:
机器学习:性能度量篇-Python利用鸢尾花数据绘制ROC和AUC曲线
机器学习:性能度量篇-Python利用鸢尾花数据绘制P-R曲线
这里我们主要进行实践利用sklearn快速实现模型数据校验,完成基础指标计算。
查准率(precision)与查全率(recall)是对于需求在信息检索、Web搜索等应用评估性能度量适应度高的检测数值。对于二分类问题,可将真实类别与算法预测类别的组合划分为真正例(ture positive)、假证例(false positive)、真反例(true negative)、假反例(false negative)四种情形。显然TP+FP+TN+FN=样例总数。分类结果为混淆矩阵:
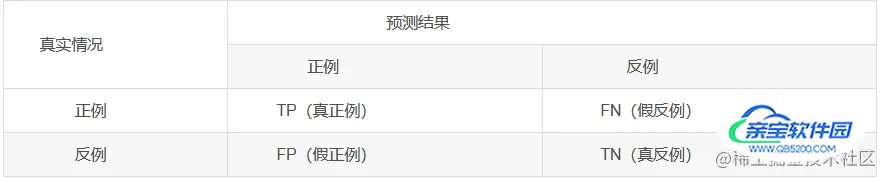
以分类模型中最简单的二分类为例,对于这种问题,我们的模型最终需要判断样本的结果是0还是1,或者说是positive还是negative。 因此,我们就能得到这样四个基础指标,我称他们是一级指标(最底层的):
预测性分类模型,肯定是希望越准越好。那么,对应到混淆矩阵中,那肯定是希望TP与TN的数量大,而FP与FN的数量小。所以当我们得到了模型的混淆矩阵后,就需要去看有多少观测值在第二、四象限对应的位置,这里的数值越多越好;反之,在第一、三象限对应位置出现的观测值肯定是越少越好。
混淆矩阵一般来说可以有三种实现展示方法,需要前置计算出混淆矩阵数据,这一点使用sklearn就可以实现:
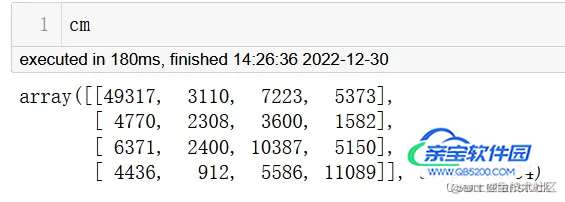
from sklearn.metrics import confusion_matrix y_true =df_evaluation.state_y y_pred =df_evaluation.state_x cm= confusion_matrix(y_true, y_pred,labels=[2,3,4,5])
其中cm就是计算出来的混淆矩阵:
利用sklearn的confusion_matrix函数就可以实现,这里将该函数的参数铺开一下:
sklearn.metrics.confusion_matrix(y_true,
y_pred,
*,
labels=None,
sample_weight=None,
normalize=None)
参数说明:
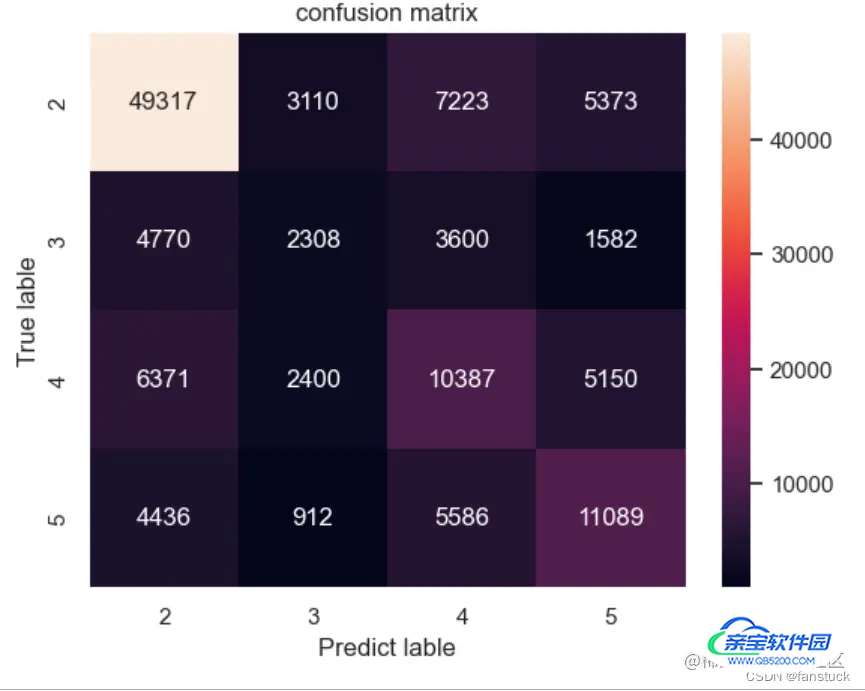
得到了混淆矩阵接下来进行数据可视化就好了,这里有三种实现形式,其中matplotlib和seaborn实现方法是一样的,都是热力图实现,另外sklearn自带一个ConfusionMatrixDisplay也可以直接实现热力。 第一种matplotlib/seaborn:
import seaborn as sns
import matplotlib.pyplot as plt
labels=[2,3,4,5]
sns.heatmap(cm,annot=True ,fmt="d",xticklabels=labels,yticklabels=labels)
plt.title('confusion matrix') # 标题
plt.xlabel('Predict lable') # x轴
plt.ylabel('True lable') # y轴
plt.show()
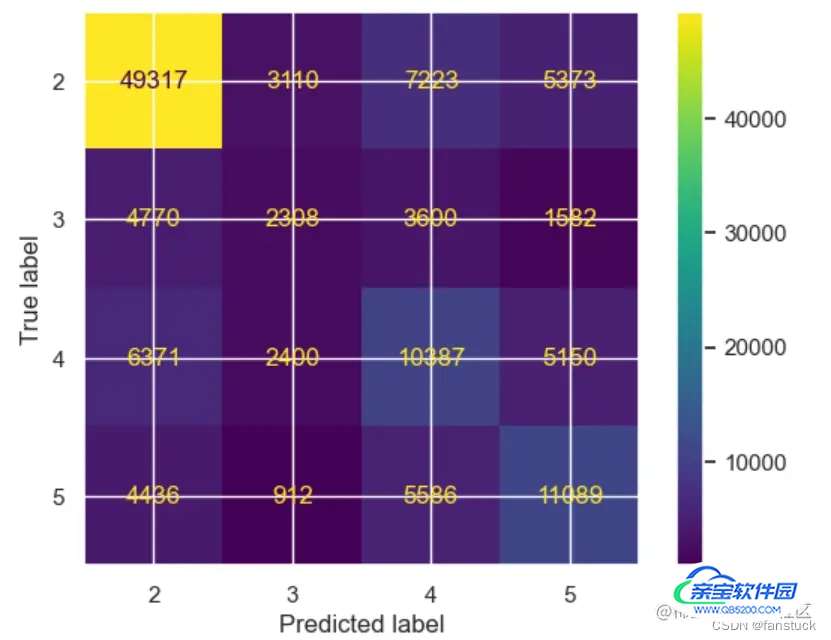
第二种ConfusionMatrixDisplay:
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot(
include_values=True,
cmap="viridis",
ax=None,
xticks_rotation="horizontal",
values_format="d"
)
plt.show()
这里我主要将一下ConfusionMatrixDisplay.plot()的可选参数:
plot(*,
include_values=True,
cmap='viridis',
xticks_rotation='horizontal',
values_format=None,
ax=None,
colorbar=True,
im_kw=None,
text_kw=None)
参数说明:

