现在”人工智能“如此火爆的一大直接原因便是deepmind做出的阿尔法狗打败李世石,从那时开始计算机科学/人工智能成为了吹逼的主流。记得当时还是在学校晚新闻的时候看到的李世石输的消息,这个新闻都是我给打开的hhhhh,对当时场景的印象还是蛮深的。现在涵哥就带大家追根溯源,看看把人工智能推上吹逼大道的研究与技术到底是怎么一回事。
在研读aphago工作原理前建议先学完david silver的RL基础课,这样读起来才有意思。
文章分了五个小块,分别是:
supervised learning of policy networks
reinforcement learning of policy networks
reinforcement learning of value networks
searching with policy and value networks
evaluating the playing strength of AlphaGO
如果用一句话说明白alphaGO是怎么工作的,那应该是“combines the policy and value network with MCTS”.

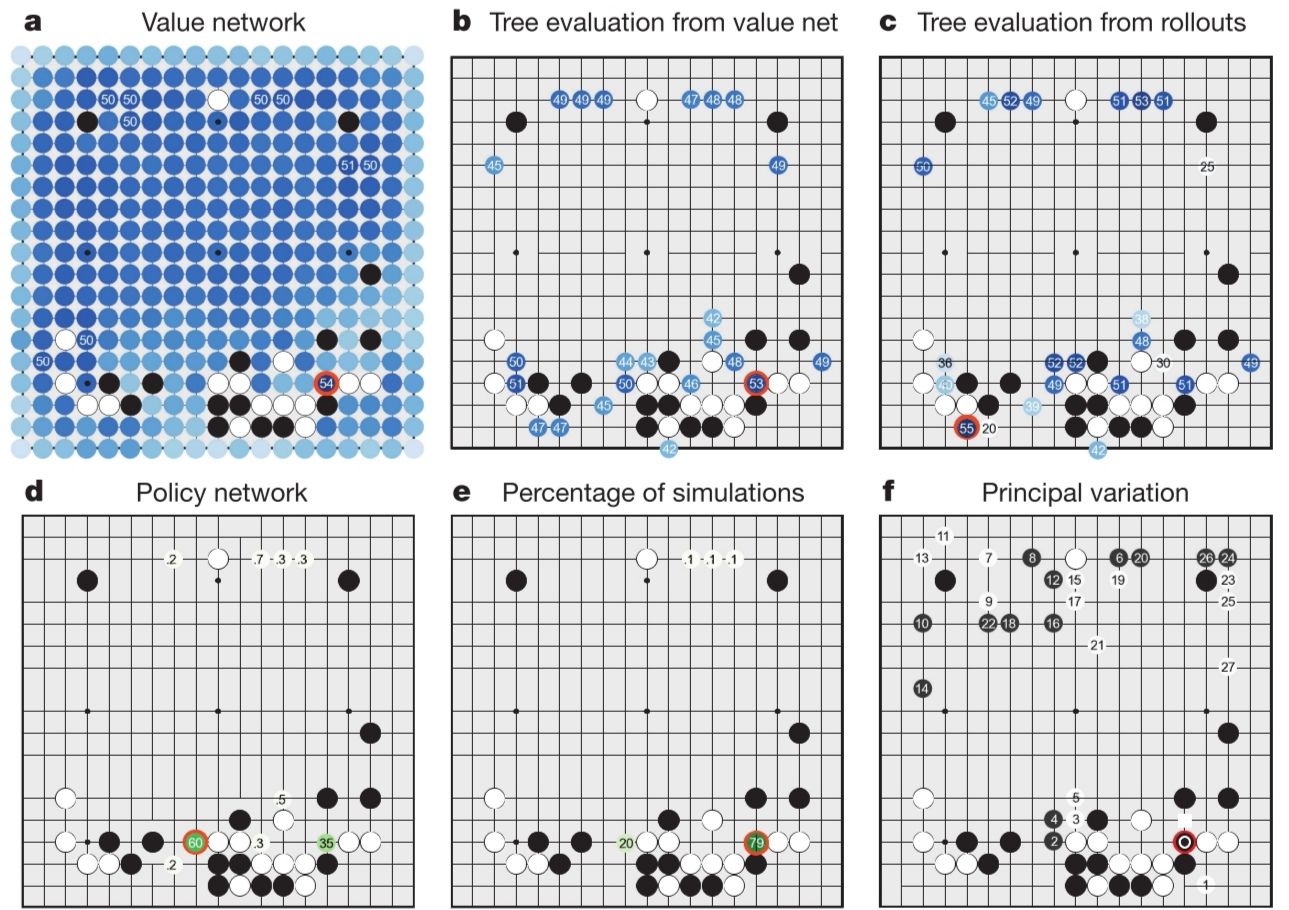
我们先从最基础的policy approximator引入。supervised learning of policy network 是一个由CNN+rectifier_nonlinearities+softmax组成的十三层的神经网络,输入the board state representation也就是当前的棋盘图像(用s表示),输出a probability distribution over all legal moves也就是选择所有符合规则的下一步走法中每一种的可能性(用a表示)。训练数据集来自KGS GO Sever即库存的人类大师对局,采用随机梯度上升法(SGA)进行训练优化————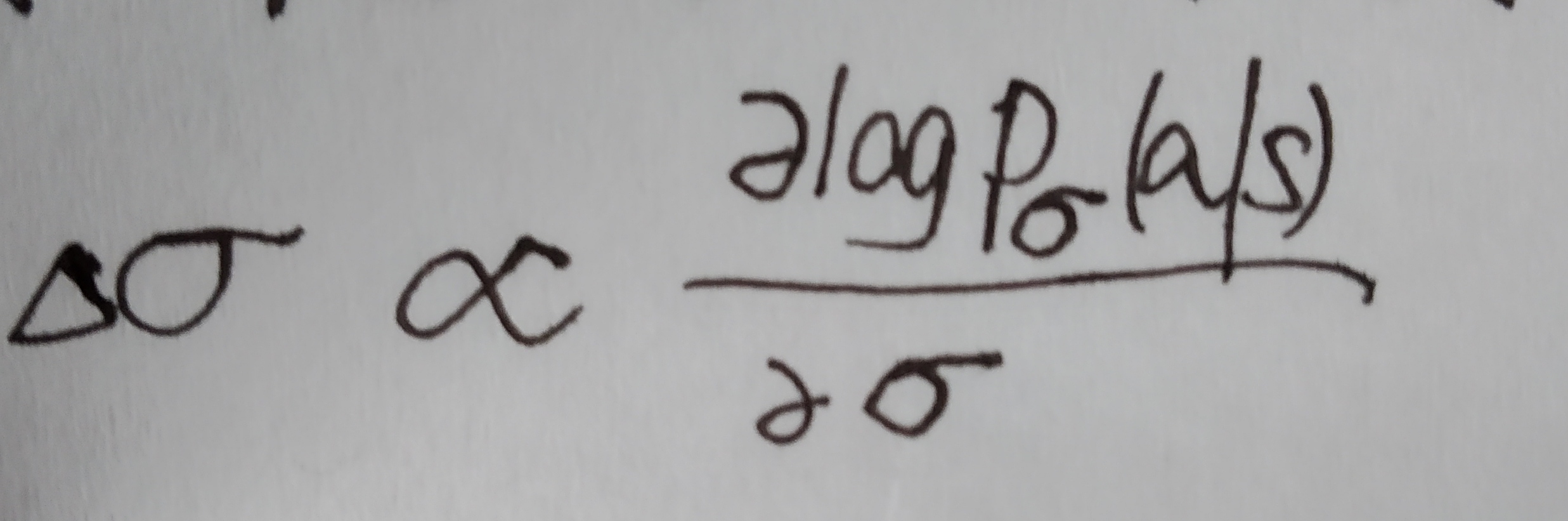 。
。
因为对SLpolicynetwork太笨重不满意,deepmind又训练了rollout policy,a linear softmax of small pattern features with weight pai,它极度快速,延时只有2μs,而policy network需要3ms。
有了第一阶段的尝试,我们把policy gradient拿来用,进入第二阶段。用pρ 表示我们的RL policy network,其结构与pσ 相同,参数初始化为ρ=σ,训练数据通过self play产生。wew play games between the current pρ and a random selected previous iteration of pρ ,也就是说通过当前迭代版本的pρ 和随机选择的先前迭代版本的pρ 之间对局产生训练数据,然后用SGA方法优化pρ ——————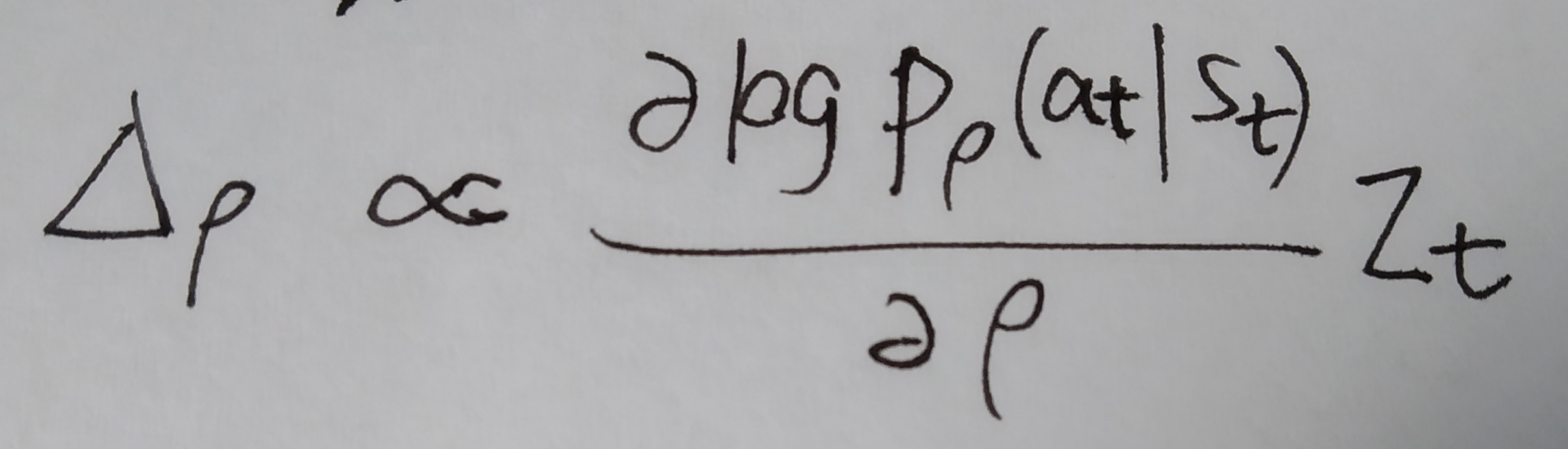 。
。
接下来进入training pipeline的最后阶段,以position evaluation为核心。在此之前我们已经把policy network做好了,也就是准备好了"策略",然后需要有一套对当前棋局的评估器,来评估从当前棋局出发依照策略p最后结果输还是赢。estimating a value function vp(s) that predicts the outcome from position s of game played by using policy p for both players。vp(s) = E[zt|st=s,at...T ~p] 。
We approximate the value function using a value network vθ(s) with weight θ , vθ(s) ≈ vpρ(s) ≈ v*(s) 。vθ(s) 结构和pρ (s)大致相似,只是输出为一个单纯的回归。训练时以state-outcome pairs (s,z)的regression作数据集,通过SGD最小化vθ(s)和corresponding outcome z之间的MSE来优化参数——————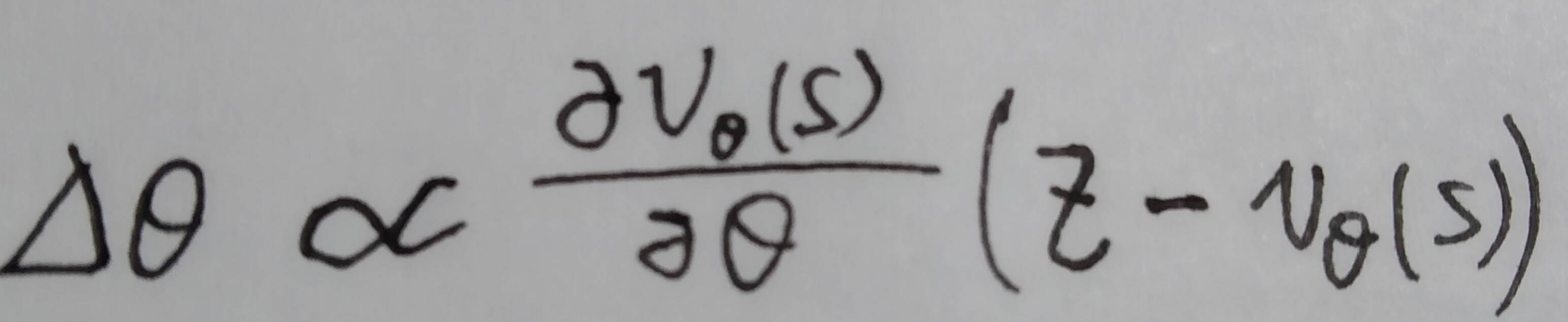 。
。
到现在准备好了策略policy和价值评估器value network,是时候借助蒙特卡洛树搜索(MCTS)对全局建模了。
AlphaGO 用MCTS将policy network 和value network结合到一起,通过MCTS的前向搜索选择下一步的行为(就是下一步棋落到哪)。"MCTS with policy and value networks"包含四个核心操作,分别是select,expansion,evaluation,backup。
搜索树的每条边(s,a)存储着action value Q(s,a),visit count N(s,a)和prior probability P(s,a),每个节点是棋局的state。从树根state开始,通过simulation即模拟对局(没有备份操作的完整对局episode)遍历这棵树。对于任意simulation的每个时间步,基于at = argmax( Q(st,a) + u(st,a) )选择action,其中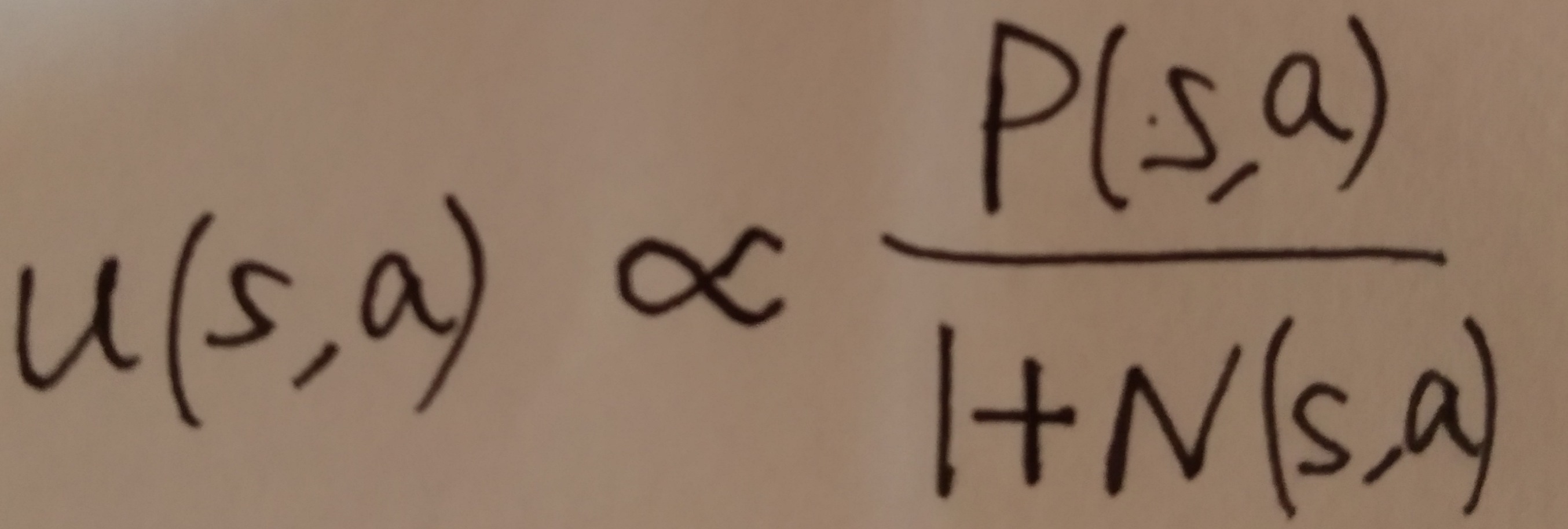 。对于每一场simulation————遍历走到叶子节点sL时如果还没到simulation的END便进行expansion操作向下扩展。P(s,a)=pσ(a|s)。到达当前simulation的END时,通过V(sL)来评估叶子节点——V(sL) = (1- λ )vθ(sL) + λzL 。vθ(sL)用了value network,zL 是基于rollout policy pπ 一直下到结束的outcome。回看,backup,更新这一场simulation所走过的所有边。每条边的visit count和mean evaluation对从它这儿走过的所有simulations进行累加,si L 表示第i次simulation(总共做了n次simulations)的叶子节点,1(s,a,i)表示第i次simulation的时候(s,a)这条边是否被走过。
。对于每一场simulation————遍历走到叶子节点sL时如果还没到simulation的END便进行expansion操作向下扩展。P(s,a)=pσ(a|s)。到达当前simulation的END时,通过V(sL)来评估叶子节点——V(sL) = (1- λ )vθ(sL) + λzL 。vθ(sL)用了value network,zL 是基于rollout policy pπ 一直下到结束的outcome。回看,backup,更新这一场simulation所走过的所有边。每条边的visit count和mean evaluation对从它这儿走过的所有simulations进行累加,si L 表示第i次simulation(总共做了n次simulations)的叶子节点,1(s,a,i)表示第i次simulation的时候(s,a)这条边是否被走过。 
search做完之后,从根结点位置选择访问次数最多的move。至此我们的AlphaGO就正式出道了,这时我仿佛听到上天对它说了句——开始你牛逼闪闪发光的一年吧!
另外deepmind还提到了他们在研究中发现的一个有意思现象:SL policy network比RL policy network表现好,而RL value network 比SL policy network 表现好,作者说“persumably because humans select a diverse beam of promising moves,whereas RL optimizes for the single best move”哈哈哈。
为了培(xun)养(lian)AlphaGO,他的父亲(deepmind)不惜砸重金,采用异步MCTS,40个搜索线程在48个CPU上做simulations,用8个并行计算GPU训练神经网络。另外deepmind也尝试了分布式MCTS,使用了40个搜索线程,1202个CPU,176个GPU。

“evaluating the playing strength of AlphaGO”这一小段我不想说了,王婆卖瓜自卖自夸,谁爱看自己去看吧。
注:对于具体method我没做太多分享,但以后想写了可能还会补充一些,我觉得alphaGO的突破之处在于成功用MCTS把policy network和value network结合到了一起。再厉害它也是在前人的基础上做的,并不是自己另辟新路,技术的发展一贯如此。至于本文为啥中英文混体,是因为我思前想后拿不定主意一些地方该怎么用纯中文来表达,这些地方英文来表达是最能传达本意的,所以直接从论文上撸下来了,莫怪莫怪。最后建议自己读一下《mastering the game of go with deep neural network and tree search》的原文。链接:https://www.nature.com/articles/nature16961.pdf