假定在程序效率和关键过程相当且不计入缓存等措施的条件下,读写任何类型的数据都没有直接操作文件来的快,不论MSYQL过程如何,最后都要到磁盘上去读这个“文件”(记录存储区等效),所以当然这一切的前提是只读 内容,无关任何排序或查找操作。
动态网站一般都是用数据库来存储信息,如果信息的及时性要求不高 可以加入缓存来减少频繁读写数据库。
两种方式一般都支持,但是绕过操作系统直接操作磁盘的性能较高,而且安全性也较高,数据库系中的磁盘性能一直都是瓶颈,大型数据库一般基于unix系统,当然win下也有,不常用应为win的不可靠性,unix下,用的是裸设备raw设备,就是没有加工过的设备(unix下的磁盘分区属于特殊设备,以文件形式统一管理),由dbms直接管理,不通过操作系统,效率很高,可靠性也高,因为磁盘,cache和内存都是自己管理的,大型数据库系统db2,oracal,informix(不太流行了),mssql算不上大型数据库系统。
1、直接读文件相比数据库查询效率更胜一筹,而且文中还没算上连接和断开的时间。
2、一次读取的内容越大,直接读文件的优势会越明显(读文件时间都是小幅增长,这跟文件存储的连续性和簇大小等有关系),这个结果恰恰跟书生预料的相反,说明MYSQL对更大文件读取可能又附加了某些操作(两次时间增长了近30%),如果只是单纯的赋值转换应该是差异偏小才对。
3、写文件和INSERT几乎不用测试就可以推测出,数据库效率只会更差。
4、很小的配置文件如果不需要使用到数据库特性,更加适合放到独立文件里存取,无需单独创建数据表或记录,很大的文件比如图片、音乐等采用文件存储更为方便,只把路径或缩略图等索引信息放到数据库里更合理一些。
5、PHP上如果只是读文件,file_get_contents比fopen、fclose更有效率,不包括判断存在这个函数时间会少3秒左右。
6、fetch_row和fetch_object应该是从fetch_array转换而来的,书生没看过PHP的源码,单从执行上就可以说明fetch_array效率更高,这跟网上的说法似乎相反。
磁盘读写与数据库的关系:
一 磁盘物理结构
(1) 盘片:硬盘的盘体由多个盘片叠在一起构成。
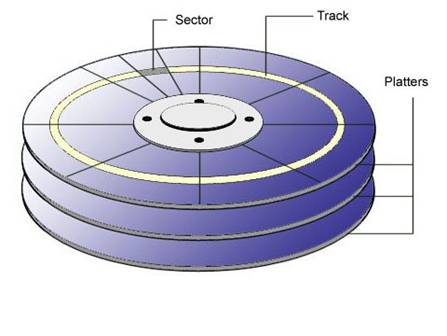
在硬盘出厂时,由硬盘生产商完成了低级格式化(物理格式化),作用是将空白的盘片(Platter)划分为一个个同圆心、不同半径的磁道(Track),还将磁道划分为若干个扇区(Sector),每个扇区可存储128×2的N次方(N=0.1.2.3)字节信息,默认每个扇区的大小为512字节。通常使用者无需再进行低级格式化操作。
(2) 磁头:每张盘片的正反两面各有一个磁头。
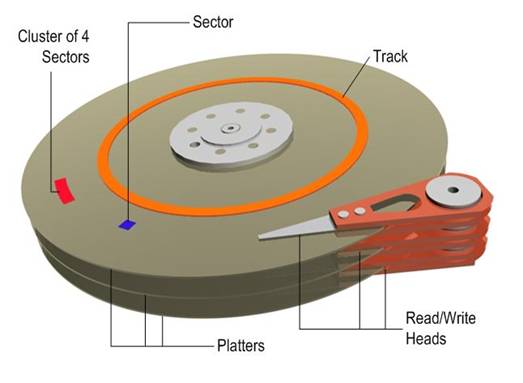
(3) 主轴:所有磁片都由主轴电机带动旋转。

(4) 控制集成电路板:复杂!上面还有ROM(内有软件系统)、Cache等。

二 磁盘如何完成单次IO操作
(1) 寻道
当控制器对磁盘发出一个IO操作命令的时候,磁盘的驱动臂(Actuator Arm)带动磁头(Head)离开着陆区(Landing Zone,位于内圈没有数据的区域),移动到要操作的初始数据块所在的磁道(Track)的正上方,这个过程被称为寻道(Seeking),对应消耗的时间被称为寻道时间(Seek Time);
(2) 旋转延迟
找到对应磁道还不能马上读取数据,这时候磁头要等到磁盘盘片(Platter)旋转到初始数据块所在的扇区(Sector)落在读写磁头正下方之后才能开始读取数据,在这个等待盘片旋转到可操作扇区的过程中消耗的时间称为旋转延时(Rotational Delay);
(3) 数据传送
接下来就随着盘片的旋转,磁头不断的读/写相应的数据块,直到完成这次IO所需要操作的全部数据,这个过程称为数据传送(Data Transfer),对应的时间称为传送时间(Transfer Time)。完成这三个步骤之后单次IO操作也就完成了。
根据磁盘单次IO操作的过程,可以发现:
单次IO时间 = 寻道时间 + 旋转延迟 + 传送时间
进而推算IOPS(IO per second)的公式为:
IOPS = 1000ms/单次IO时间
三 磁盘IOPS计算
不同磁盘,它的寻道时间,旋转延迟,数据传送所需的时间各是多少?
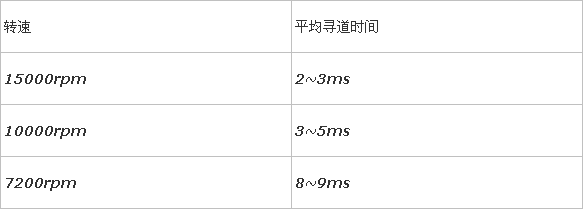
1. 寻道时间
考虑到被读写的数据可能在磁盘的任意一个磁道,既有可能在磁盘的最内圈(寻道时间最短),也可能在磁盘的最外圈(寻道时间最长),所以在计算中我们只考虑平均寻道时间。
在购买磁盘时,该参数都有标明,目前的SATA/SAS磁盘,按转速不同,寻道时间不同,不过通常都在10ms以下:
3. 传送时间2. 旋转延时
和寻道一样,当磁头定位到磁道之后有可能正好在要读写扇区之上,这时候是不需要额外的延时就可以立刻读写到数据,但是最坏的情况确实要磁盘旋转整整一圈之后磁头才能读取到数据,所以这里也考虑的是平均旋转延时,对于15000rpm的磁盘就是(60s/15000)*(1/2) = 2ms。
(1) 磁盘传输速率
磁盘传输速率分两种:内部传输速率(Internal Transfer Rate),外部传输速率(External Transfer Rate)。
内部传输速率(Internal Transfer Rate),是指磁头与硬盘缓存之间的数据传输速率,简单的说就是硬盘磁头将数据从盘片上读取出来,然后存储在缓存内的速度。
理想的内部传输速率不存在寻道,旋转延时,就一直在同一个磁道上读数据并传到缓存,显然这是不可能的,因为单个磁道的存储空间是有限的;
实际的内部传输速率包含了寻道和旋转延时,目前家用磁盘,稳定的内部传输速率一般在30MB/s到45MB/s之间(服务器磁盘,应该会更高)。
外部传输速率(External Transfer Rate),是指硬盘缓存和系统总线之间的数据传输速率,也就是计算机通过硬盘接口从缓存中将数据读出交给相应的硬盘控制器的速率。
硬盘厂商在硬盘参数中,通常也会给出一个最大传输速率,比如现在SATA3.0的6Gbit/s,换算一下就是6*1024/8,768MB/s,通常指的是硬盘接口对外的最大传输速率,当然实际使用中是达不到这个值的。
这里计算IOPS,保守选择实际内部传输速率,以40M/s为例。
(2) 单次IO操作的大小
有了传送速率,还要知道单次IO操作的大小(IO Chunk Size),才可以算出单次IO的传送时间。那么磁盘单次IO的大小是多少?答案是:不确定。
操作系统为了提高 IO的性能而引入了文件系统缓存(File System Cache),系统会根据请求数据的情况将多个来自IO的请求先放在缓存里面,然后再一次性的提交给磁盘,也就是说对于数据库发出的多个8K数据块的读操作有可能放在一个磁盘读IO里就处理了。
还有,有些存储系统也是提供了缓存(Cache),接收到操作系统的IO请求之后也是会将多个操作系统的 IO请求合并成一个来处理。
不管是操作系统层面的缓存还是磁盘控制器层面的缓存,目的都只有一个,提高数据读写的效率。因此每次单独的IO操作大小都是不一样的,它主要取决于系统对于数据读写效率的判断。这里以SQL Server数据库的数据页大小为例:8K。
(3) 传送时间
传送时间 = IO Chunk Size/Internal Transfer Rate = 8k/40M/s = 0.2ms
可以发现:
(3.1) 如果IO Chunk Size大的话,传送时间会变大,从而导致IOPS变小;
(3.2) 机械磁盘的主要读写成本,都花在了寻址时间上,即:寻道时间 + 旋转延迟,也就是磁盘臂的摆动,和磁盘的旋转延迟。
(3.3) 如果粗略的计算IOPS,可以忽略传送时间,1000ms/(寻道时间 + 旋转延迟)即可。
4. IOPS计算示例
以15000rpm为例:
(1) 单次IO时间
单次IO时间 = 寻道时间 + 旋转延迟 + 传送时间 = 3ms + 2ms + 0.2 ms = 5.2 ms
(2) IOPS
IOPS = 1000ms/单次IO时间 = 1000ms/5.2ms = 192 (次)
这里计算的是单块磁盘的随机访问IOPS。
考虑一种极端的情况,如果磁盘全部为顺序访问,那么就可以忽略:寻道时间 + 旋转延迟 的时长,IOPS的计算公式就变为:IOPS = 1000ms/传送时间
IOPS = 1000ms/传送时间= 1000ms/0.2ms = 5000 (次)
显然这种极端的情况太过理想,毕竟每个磁道的空间是有限的,寻道时间 + 旋转延迟 时长确实可以减少,不过是无法完全避免的。
四 数据库中的磁盘读写
1. 随机访问和连续访问
(1) 随机访问(Random Access)
指的是本次IO所给出的扇区地址和上次IO给出扇区地址相差比较大,这样的话磁头在两次IO操作之间需要作比较大的移动动作才能重新开始读/写数据。
(2) 连续访问(Sequential Access)
相反的,如果当次IO给出的扇区地址与上次IO结束的扇区地址一致或者是接近的话,那磁头就能很快的开始这次IO操作,这样的多个IO操作称为连续访问。
(3) 以SQL Server数据库为例
数据文件,SQL Server统一区上的对象,是以extent(8*8k)为单位进行空间分配的,数据存放是很随机的,哪个数据页有空间,就写在哪里,除非通过文件组给每个表预分配足够大的、单独使用的文件,否则不能保证数据的连续性,通常为随机访问。
另外哪怕聚集索引表,也只是逻辑上的连续,并不是物理上。
日志文件,由于有VLF的存在,日志的读写理论上为连续访问,但如果日志文件设置为自动增长,且增量不大,VLF就会很多很小,那么就也并不是严格的连续访问了。
2. 顺序IO和并发IO
(1) 顺序IO模式(Queue Mode)
磁盘控制器可能会一次对磁盘组发出一连串的IO命令,如果磁盘组一次只能执行一个IO命令,称为顺序IO;
(2) 并发IO模式(Burst Mode)
当磁盘组能同时执行多个IO命令时,称为并发IO。并发IO只能发生在由多个磁盘组成的磁盘组上,单块磁盘只能一次处理一个IO命令。
(3) 以SQL Server数据库为例
有的时候,尽管磁盘的IOPS(Disk Transfers/sec)还没有太大,但是发现数据库出现IO等待,为什么?通常是因为有了磁盘请求队列,有过多的IO请求堆积。
磁盘的请求队列和繁忙程度,通过以下性能计数器查看:
LogicalDisk/Avg.Disk Queue Length
LogicalDisk/Current Disk Queue Length
LogicalDisk/%Disk Time
这种情况下,可以做的是:
(1) 简化业务逻辑,减少IO请求数;
(2) 同一个实例下,多个数据库迁移的不同实例下;
(3) 同一个数据库的日志,数据文件分离到不同的存储单元;
(4) 借助HA策略,做读写操作的分离。
3. IOPS和吞吐量(throughput)
(1) IOPS
IOPS即每秒进行读写(I/O)操作的次数。在计算传送时间时,有提到,如果IO Chunk Size大的话,那么IOPS会变小,假设以100M为单位读写数据,那么IOPS就会很小。
(2) 吞吐量(throughput)
吞吐量指每秒可以读写的字节数。同样假设以100M为单位读写数据,尽管IOPS很小,但是每秒读写了N*100M的数据,吞吐量并不小。
(3) 以SQL Server数据库为例
对于OLTP的系统,经常读写小块数据,多为随机访问,用IOPS来衡量读写性能;
对于数据仓库,日志文件,经常读写大块数据,多为顺序访问,用吞吐量来衡量读写性能。
磁盘当前的IOPS,通过以下性能计数器查看:
LogicalDisk/Disk Transfers/sec
LogicalDisk/Disk Reads/sec
LogicalDisk/Disk Writes/sec
磁盘当前的吞吐量,通过以下性能计数器查看:
LogicalDisk/Disk Bytes/sec
LogicalDisk/Disk Read Bytes/sec
LogicalDisk/Disk Write Bytes/sec

