limlog
作一篇文章记录实现,驱动优化迭代。 Github
很久之前就想写一个日志库了,受限制于自己水平这个想法一直没有完成。在上次写一个 TCPServer 的时候,写了一个错误的日志库,在多线程的情况对速度影响非常大,并且最重要的正确性也没有保证。
近期又有了点时间,决定重新实现,对其 特点期望:
- 正确性,这个是最重要也是最基本的,包括
- 全部写入.
- 多个线程间的日志不穿插干扰.
- 日志线程不能干扰主程序的运行逻辑.
- 易读性
- 每条日志记录占用一行空间,便于 awk 等工具的时候方便查找.
- 日志信息包含必要的信息,包括日期时间、线程id、日志等级、日志发生的文件和行数.
- 易用性
- 在类 printf 和 std::cout 的用法中选择类 std::cout 用法.
- 根据时间和日志文件大小自动滚动文件.
- 代码行数不超过 2000 行
- 速度
- 速度的重要性放在最后,线程增加(不超过CPU数量)的情况下,对速度的影响在30%内,每条日志达到耗时在 1us 左右基本可以满足要求.
日志格式和日志文件格式期望如下:
- 日志文件的格式为:文件名.日期.时间.日志文件滚动的索引.log
test_log_file.20191224.160354.7.log - 日志行的格式为 时间(精确到微秒)线程id 日志等级 日志信息 - 文件名:调用函数:行
20191224 16:04:05.125049 2970 ERROR 5266030 chello, world - LogTest.cpp:thr_1():20
之前看的两个日志库,恰好都叫做 NanoLog:
- Iyengar111/NanoLog, 跨平台、C++11、实现简单(不超过1000行),每个日志行对应一个流对象、速度较快。
- PlatformLab/NanoLog, 斯坦福一个实验室的项目,Linux 平台、C++17、日志行异步写入,每个线程有一个局部的循环字节缓冲区,速度恐怖,是见过最快的日志库了,实现也非常细腻,优化的地方非常多,部分固定的日志信息直接编译期确定下来。
前一个日志库学到了用户接口宏的定义方式,后一个 nanolog 则是吸收了其后端的设计部分,尤其是 thread_local 的使用,但我觉得它的精华在于前端部分,充斥着大量的模板。嗯,没太看懂。
实现
前后端分离实现
- 后端负责日志信息的落地处理,是整个日志系统的重心。
- 前端负责组织日志信息的格式。
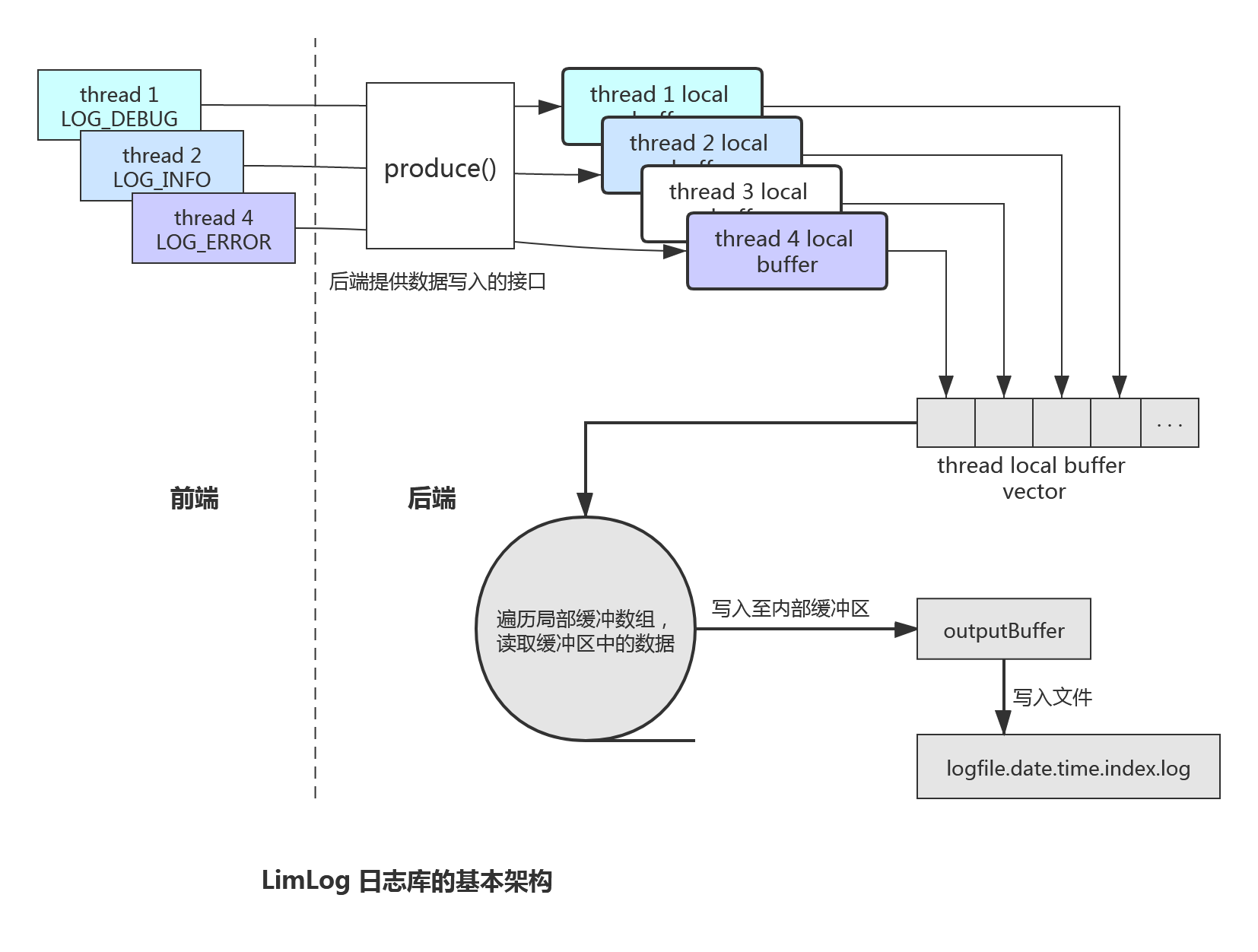
后端实现
采用单例模式,全局只有一个 LimLog 对象,在这个对象构造时也创建一个后台线程,通过无限循环扫描是否有数据可以写入至文件中。通过条件变量控制该循环的终止及 LimLog 对象的销毁。
使用 C++ 11 的关键字 thread_local 为每个线程都创建一个线程局部缓冲区,这样我们的前端的日志写入就可以不用加锁(虽然不用加锁,但是有另外的处理,后说明),每次都写入到各自线程的缓冲区中。然后在上面的循环中扫描这些缓冲区,将其中的日志数据读取至内部的输出缓冲区中,再将其写入到文件中。
每个缓冲区内存只创建一次使用,避免每次使用创建带来不必要的申请消耗。每个线程局部缓冲区的大小为 1M(1 << 20 bytes), LimLog 对象内的输出缓冲区大小为 16M(1 << 24 bytes), 这个大小非常充足,实际测试 大概每个线程的内存使用为 30k(1M) 和 60-150k(16M) 左右,这个地方需要IO压测一下。
后端日志类的成员变量如下,
class LimLog{
···
private:
LogSink logSink_;
bool threadSync_; // 前后端同步的标示
bool threadExit_; // 后台线程标示
bool outputFull_; // 输出缓冲区满的标示
LogLevel level_;
uint32_t bufferSize_; // 输出缓冲区的大小
uint32_t sinkCount_; // 写入文件的次数
uint32_t perConsumeBytes_; // 每轮循环读取的字节数
uint64_t totalConsumeBytes_; // 总读取的字节数
char *outputBuffer_; // first internal buffer.
char *doubleBuffer_; // second internal buffer, unused.
std::vector<BlockingBuffer *> threadBuffers_;
std::thread sinkThread_;
std::mutex bufferMutex_; // internel buffer mutex.
std::mutex condMutex_;
std::condition_variable proceedCond_; // 后台线程是否继续运行的标条件变量
std::condition_variable hitEmptyCond_; // 前端缓冲区为空的条件变量
static LimLog singletonLog;
static thread_local BlockingBuffer *blockingBuffer_; // 线程局部缓冲区
};对 LimLog 对象的析构和后台线程的退出需要十分的谨慎,这里程序出问题的重灾区,前一个日志库就是这个地方没有处理好,导致有的时候日志还没有写完程序就退出了。为了保证这个逻辑的正确运行,采用了两个条件变量 proceedCond_ 和 hitEmptyCond_。在执行对象的析构函数时,需要等待无可读数据的条件变量 hitEmptyCond_, 保证这个时候线程局部缓冲区的数据都已经读取完成,然后在析构函数中设置后台线程循环退出的条件,并且使用 proceedCond_ 通知后台线程运行。
以上逻辑在析构函数中的逻辑如下:
LimLog::~LimLog() {
{
// notify background thread befor the object detoryed.
std::unique_lock<std::mutex> lock(singletonLog.condMutex_);
singletonLog.threadSync_ = true;
singletonLog.proceedCond_.notify_all();
singletonLog.hitEmptyCond_.wait(lock);
}
{
// stop sink thread.
std::lock_guard<std::mutex> lock(condMutex_);
singletonLog.threadExit_ = true;
singletonLog.proceedCond_.notify_all();
}
···
}之后就转入到后台线程的循环处理中,以下是所有后台线程处理的逻辑:
// Sink log info to file with async.
void LimLog::sinkThreadFunc() {
// \fixed me, it will enter infinity if compile with -O3 .
while (!threadExit_) {
// move front-end data to internal buffer.
{
std::lock_guard<std::mutex> lock(bufferMutex_);
uint32_t bbufferIdx = 0;
// while (!threadExit_ && !outputFull_ && !threadBuffers_.empty()) {
while (!threadExit_ && !outputFull_ &&
(bbufferIdx < threadBuffers_.size())) {
BlockingBuffer *bbuffer = threadBuffers_[bbufferIdx];
uint32_t consumableBytes = bbuffer->consumable(); // 如果这个地方使用 used() 代替,就会出现日志行截断的现象
if (bufferSize_ - perConsumeBytes_ < consumableBytes) {
outputFull_ = true;
break;
}
if (consumableBytes > 0) {
uint32_t n = bbuffer->consume(
outputBuffer_ + perConsumeBytes_, consumableBytes);
perConsumeBytes_ += n;
} else {
// threadBuffers_.erase(threadBuffers_.begin() +
// bbufferIdx);
}
bbufferIdx++;
}
}
// not data to sink, go to sleep, 50us.
if (perConsumeBytes_ == 0) {
std::unique_lock<std::mutex> lock(condMutex_);
// if front-end generated sync operation, consume again.
if (threadSync_) {
threadSync_ = false;
continue;
}
hitEmptyCond_.notify_one();
proceedCond_.wait_for(lock, std::chrono::microseconds(50));
} else {
logSink_.sink(outputBuffer_, perConsumeBytes_);
sinkCount_++;
totalConsumeBytes_ += perConsumeBytes_;
perConsumeBytes_ = 0;
outputFull_ = false;
}
}
}当扫描发现无数据可取时,这个时候我们再循环读取一下,防止析构函数在扫描数据和判断 threadSync_ 执行的时间差之内又有日志产生,在又一轮循环后,确保所有的数据都已经读取,通知析构函数继续执行,然后退出循环,该后台线程函数退出,线程销毁。 wait_for 是节约系统资源,出现无数据时当前线程就直接休眠 50us 避免不必要的循环消耗.
以上是对后台线程的处理,对数据的处理其实还是比较简单的,后端提供了一个写入数据的接口,该接口将前端产生的数据统一写入至线程局部缓冲区中。
void LimLog::produce(const char *data, size_t n) {
if (!blockingBuffer_) {
std::lock_guard<std::mutex> lock(bufferMutex_);
blockingBuffer_ =
static_cast<BlockingBuffer *>(malloc(sizeof(BlockingBuffer)));
threadBuffers_.push_back(blockingBuffer_); // 添加到后端的缓冲区数组中
}
blockingBuffer_->produce(data, n); // 将数据添加到线程局部缓冲区中
}后台写入线程这个时候,遍历缓冲数组,读取数据至内部的输出缓冲区中,当出现可读取的数据大于缓冲区时,直接写入文件,剩余的数据下一路再读取;当无可读取的数据时,判断是对象析构了还只是简单的没有数据读取,并且休眠 50us;有数据可读则写入至文件,重置相关数据。
线程局部缓冲区为一个阻塞环形生产者消费者队列,设计为阻塞态的原因为缓冲区的大小足够大了,如果改为非阻塞态,当缓冲区的满了的时候重新分配内存,还要管理一次内存的释放操作。虽然线程内的操作不需要使用锁来同步,在后台线程的循环范围内,每次都要获取数据的可读大小,这里可能就涉及多个线程对数据的访问了。最初的版本测试在没有同步并且开启优化的情况下,有一定概率在 consume() 操作陷入死循环,原因是该线程的 cache 的变量未及时得到更新。现在使用内存屏障来解决这个问题,避免编译器优化。
对于后台线程读取各线程内的数据有一个随机性的问题,如果使用 BlockingBuffer::unsed()获取已读数据长度,可能会出现日志行只被读取了一半,然后立刻被另外的一个线程的日志截断的情况,这不是我们期望的。为了解决这个问题,我们又提供了一个接口 BlockingBuffer::incConsumablePos() 来移动可以读取的位置,该接口每次递增的长度为一条日志行的长度,在一日志行数据写入到局部缓冲区后调用该接口来移动可以读取到的位置。而又提供接口 BlockingBuffer::consumable() 来获取可以读取的长度,这样就避免了一条日志行被截断的情况。
前端实现
一条日志信息在内存中的布局如下:
+------+-----------+-------+------+------+----------+------+
| time | thread id | level | logs | file | function | line |
+------+-----------+-------+------+------+----------+------+
20191224 16:04:05.125044 2970 ERROR 5266025chello, world - LogTest.cpp:thr_1():20
20191224 16:04:05.125044 2970 ERROR 5266026chello, world - LogTest.cpp:thr_1():20
20191224 16:04:05.125045 2970 ERROR 5266027chello, world - LogTest.cpp:thr_1():20前端实现虽然简单,但是优化的空间很大,使用 perf 做性能分析,性能热点集中在参数格式化为字符串和时间的处理上面。
我们用 LogLine 来表示一个日志行,这个类非常简单,重载了多个参数类型的操作符 <<, 及保存一些日志行相关信息,包括 文件名称,函数,行和最重要的写入字节数。
LogLine 不包含缓冲区,直接调用后端提供的接口 LimLog::produce() 将数据写入到局部缓冲区内。
在 limlog 中,多次使用到了 thread_local 关键字,在前端实现部分也是如此。
time 的处理
在 Linux 中使用 gettimeofday(2) 来获取当前的时间戳,其他平台使用 std::chrono 来获取时间戳,用 localtime() 和 strftime() 获取本地的格式化时间 %Y%m%d %H:%M:%S, 合并微秒 timestamp % 1000000 组成 time.
这里利用 thread_local 做一个优化,格式化时间的函数调用次数。定义一个线程局部变量来存储时间戳对应的秒数 t_second 和 字符数组来存储格式化时间 t_datetime[24],当秒数未发生改变时,直接取线程局部字符数组而不用再调用格式化函数。
在 x86-64 体系下,gettimeofday(2) 在 vdso 机制下已经不是系统调用了,经测试发现直接调用 gettimeofday(2) 比 std::chrono 的高精度时钟快 15% 左右,虽然不是系统调用但是耗时还是大头,一个调用大概需要 600ns 左右的时间。
thread id 的获取
在 Linux 下,使用 gettid() 而不是 pthread_self() 来获取线程id,windows 暂时未支持,这个 std::this_thread::get_id() 取出里面的整形id需要hack一下。
这里继续使用 thread_local 来对线程id优化,每个线程的id调用一次线程id获取函数。创建一个线程局部线程id变量,判断线程id存在时,就不再调用 gettid() 了。
日志行的其他项
日志等级、文件、函数和行数是简单的字符串写入操作了。
用法
#define LOG(level) \
if (limlog::getLogLevel() <= level) \
LogLine(level, __FILE__, __FUNCTION__, __LINE__)
#define LOG_TRACE LOG(limlog::LogLevel::TRACE)
#define LOG_DEBUG LOG(limlog::LogLevel::DEBUG)
#define LOG_INFO LOG(limlog::LogLevel::INFO)
#define LOG_WARN LOG(limlog::LogLevel::WARN)
#define LOG_ERROR LOG(limlog::LogLevel::ERROR)
#define LOG_FATAL LOG(limlog::LogLevel::FATAL)如上所示,定义了一些宏给调用者使用,每一条日志都会创建一个 LogLine 对象,这个对象非常小,用完就销毁,几乎没有开销。用法同 std::cout
std::string str("std::string");
LOG_DEBUG << 'c' << 1 << 1.3 << "c string" << str;TODO
- 支持跨平台
- 支持线程id的获取
- 文件的自动滚动
- 根据时间(每天)自动滚动文件
- 速度
- 对
LogLine::operator<<()参数转字符串做优化 - 日志行的时间戳获取优化,这里的时间占去60%左右的开销
- 对
- 测试
- 速度
- 正确性
参考
- Iyengar111/NanoLog, Low Latency C++11 Logging Library.
- PlatformLab/NanoLog, Nanolog is an extremely performant nanosecond scale logging system for C++ that exposes a simple printf-like API.
- kfifo, 环形生产者消费者队列.
- memory barries, 内核的内存屏障.

