RDD(Resiliennt Distributed Datasets)抽象弹性分布式数据集对于Spark来说的弹性计算到底提现在什么地方?
自动进行内存和磁盘数据这两种存储方式的切换
Spark 可以使用 persist 和 cache 方法将任意 RDD 缓存到内存或者磁盘文件系统中。数据会优先存储到内存中,当内存不足以存放RDD中的数据的时候,就会持久化到磁盘上。这样,就可以最大化的利益内存以达到最高的计算效率;同时又有磁盘作为兜底存储方案以确保计算结果的正确性。
基于Linage的高效容错机制
Linage是用于记录RDD的父子依赖关系,子RDD会记录父RDD,且各个分片之间的数据互不影响。当出现错误的时候,只需要恢复单个Split的特定部分即可。常规容错方式有两种:第一种是数据Check Poin检查点;第二个是记录数据的更新。一般意义上CheckPoin的基本工作方式是通过数据中心的网络链接到不同的机器上,然后每次操作的时候都要复制数据集。相当于每个更新都对应一个记录且同步到分布式集群中的各个节点上。由此集群间网络和磁盘资源耗损比较大。但是Spark的RDD只有在Action操作的时候才会真正触发计算,而Transform操作是惰性的,所以期间只有在Action操作的时候才会记录到CheckPoint中。
Task失败自动重试
缺省情况下,会自动重试4次。也可以在spark-submit的时候指定spark.task.maxFailures参数来修改缺省值
private[spark] class TaskSchedulerImpl(
val sc: SparkContext,
val maxTaskFailures: Int,
isLocal: Boolean = false)
extends TaskScheduler with Logging {
import TaskSchedulerImpl._
def this(sc: SparkContext) = {
this(sc, sc.conf.get(config.TASK_MAX_FAILURES))
}
...
源码:https://github.com/apache/spark/blob/e1ea806b3075d279b5f08a29fe4c1ad6d3c4191a/core/src/main/scala/org/apache/spark/scheduler/TaskSchedulerImpl.scala
而其中的config.TASK_MAX_FAILURES来自:https://github.com/apache/spark/blob/e1ea806b3075d279b5f08a29fe4c1ad6d3c4191a/core/src/main/scala/org/apache/spark/internal/config/package.scala
private[spark] val TASK_MAX_FAILURES =
ConfigBuilder("spark.task.maxFailures")
.intConf
.createWithDefault(4)
TaskScheduler从每一个Stage的DAGScheduler中获取TaskSet,运行并校验是否存在故障。如果存在故障则会重试指定测试
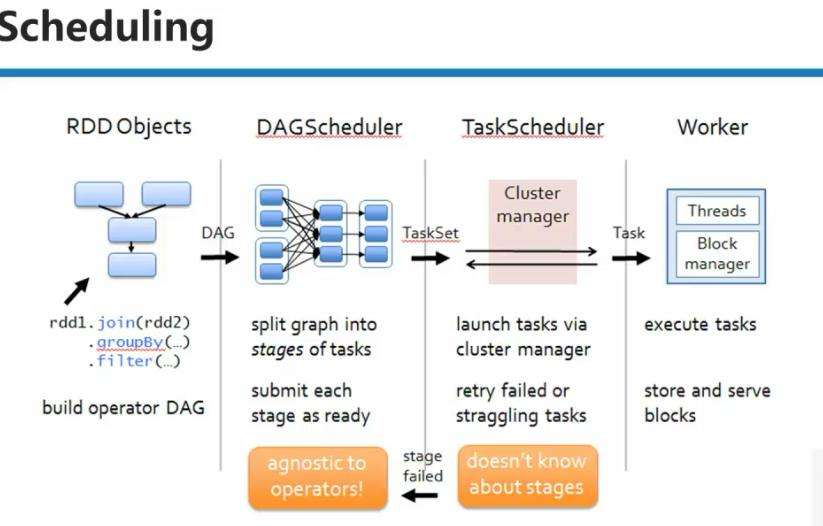
Stage失败自动重试
Stage对象可以记录并跟踪多个StageInfo,缺省的重试次数也是4次。且可以直接运行计算失败的阶段,值计算失败的数据分片。 Stage是Spark Job运行时均有相同逻辑功能和并行计算任务的一个基本单元。其中的所有任务都依赖同样的Shuffle,每个DAG任务都是通过DAGScheduler在Stage的边界处发生Shuffle形成Stage,然后DAGScheduler按照这些拓扑结构执行
/**
* Number of consecutive stage attempts allowed before a stage is aborted.
*/
private[scheduler] val maxConsecutiveStageAttempts =
sc.getConf.getInt("spark.stage.maxConsecutiveAttempts",
DAGScheduler.DEFAULT_MAX_CONSECUTIVE_STAGE_ATTEMPTS)
源码:https://github.com/apache/spark/blob/094563384478a402c36415edf04ee7b884a34fc9/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala

Checkpoint和Persist
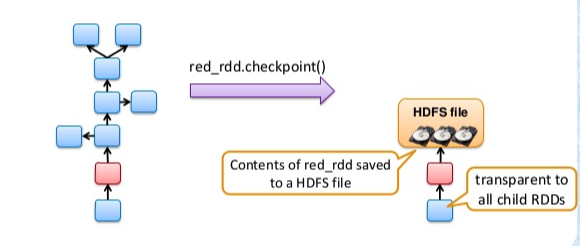
Checkpoin和Persist都可以由我们自己来调用。checkpoint是对RDD进行标记,并且产生对应的一系列文件,且所有父依赖都会被删除,是整个Linage的终点。persist工作的主体RDD会把计算的分片结果保存在内存或磁盘上,以确保下次针对同一个RDD的调用可以重用。 两种的区别如下:
- Persist将RDD缓存之后,其Linage关系任然存在,在节点宕机或RDD部分缓存丢失的时候,RDD任然可以根据Linage关系来重新运算;而Checkpoin将RDD写入到文件系统之后,将不再维护Linage
- rdd.persist即使调用的是DISK_ONLY操作,也就是只写入文件系统,该写入rdd是由BlockManager管理,executor程序停止后BlockManager也就停止了,所以其持久化到磁盘中的数据也会被清理掉;而checkpoint持久化到文件系统(HDFS文件或者是本地文件系统),不会被删除,还可以供其他程序调用。
数据调度弹性
上面所提到的DAGScheduler和TaskScheduler和资源无关。Spark将执行模型抽象为DAG,可以让多个Stage任务串联或者并行执行,而无需将中间结果写入到HDFS中。这样当某个节点故障的时候,可以由其他节点来执行出错的任务。
数据分片coalesce
Spark进行数据分片的时候,默认将数据存放在内存中,当内存不够的时候,会将一部分存放到磁盘上。如经过分片后,某个Partition非常小,就可以合并多个小的partition来计算,而不用每个partition都起一个线程。这样就提高了效率,也不会因为大量的线程而导致OOM