推荐中的个性化重排--Personalized Re-ranking for Recommendation
这篇文章是阿里在ResSys'19发表的,主要贡献是在重排序阶段,引入了用户的相关信息,很符合实际场景。
- PRM的提出
重排主要是对排序后结果的优化,也可以用于二次推荐。考虑到性能原因,典型的排序技术是基于pointwise的,给定一个query,系统对每个物品进行打分,按照打分结果进行排序。pointwise不考虑排序列表中物品之间的相关性,为了解决这个问题,有两种主流做法:
pairwise和listwise:pairwise和listwise考虑列表中物品间的相关性
建模物品之间的相互作用:基于RNN的方法是目前的SOTA,输入初始列表,输出编码后的列表[2].RNN存在两个问题,一是距离限制,二是无法有效的对列表中物品进行交互。
直观上来说,用户的行为信息也应该被加入到重排,因为不同用户的倾向性不同。假如用户更关注价格,重排时价格就需要更多关注。文章提出基于Transformer的个性化重排,
- 假如用户和列表中物品的交互,更加合理
- Transformer的self-attention机制有效捕捉特征间的交互,改善了基于RNN方法的缺点
- 模型细节
先看图

个性化重排的个性化就体现在加入了用户个性化向量\(pv\),可以建模用户个性和物品之间的相互关系。
输入层
输入层由三部分组成:原始特征、个性化特征、位置特征
给定初始列表\(\mathcal{S}=\left[i_{1}, i_{2}, \ldots, i_{n}\right]\),原始特征矩阵\(X \in \mathbb{R}^{n \times d_{\text {feature }}}\),\(X\)的每行\(x_i\)对应\(i \in S\)的特征向量。\(P V \in \mathbb{R}^{n \times d_{\mathrm{pv}}}\)是个性化矩阵,由预训练得到。\(PE \in \mathbb{R}^{\boldsymbol{n} \times\left(d_{\text {feature }}+d_{p v}\right)}\)表示位置编码,初始列表中物品的位置.
\[
E^{\prime \prime}=\left[\begin{array}{c}
{x_{i_{1}} ; p v_{i_{1}}} \\
{x_{i_{2}} ; p v_{i_{2}}} \\
{\cdots} \\
{x_{i_{n}} ; p v_{i_{n}}}
\end{array}\right]+\left[\begin{array}{c}
{p e_{i_{1}}} \\
{p e_{i_{2}}} \\
{\cdots} \\
{p e_{i_{n}}}
\end{array}\right]
\]
其中\(E^{\prime \prime} \in \mathbb{R}^{n \times\left(d_{\text {feature }}+d_{p v}\right)}\),为了将\(E^{''}\)转化\(d\)维的\(E\),使用前馈神经网络转化下:
\[
E=E W^{E}+b^{E}
\]
此处有一个疑问,为什么需要做这一步降维?直接将拼接后的向量送入编码层不可以吗?
编码层
编码层目标在于整合对列表中物品的相互影响,以及用户行为和列表中物品的相互影响。这里使用了Transformer的编码部分,可以看图(a).
输出层
输出层使用\(softmax\)输出一个分数列表,根据分数就可以实现重排。具体来说,
\[
\text { Score }(i)=P\left(y_{i} | X, P V ; \hat{\theta}\right)=\operatorname{softmax}\left(F^{\left(N_{x}\right)} W^{F}+b^{F}\right), i \in \mathcal{S}_{r}
\]
其中\(F^{\left(N_{x}\right)}\)是Transformer部分的输出。对应的损失函数为
\[
\mathcal{L}=-\sum_{r \in \mathcal{R}} \sum_{i \in S_{r}} y_{i} \log \left(P\left(y_{i} | X, P V ; \hat{\theta}\right)\right.
\]
其中\(\mathcal{R}\)是所有用户的请求的集合。即保证重排后的列表尽可能的符合每个用户
预训练个性化向量
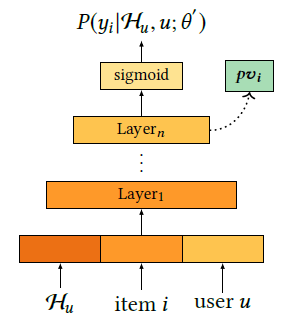
预训练网络将点击率作为目标,利用网络的隐层向量作为个性化向量。就是预训练模型的经典操作。对应的损失函数
\[
\begin{aligned}\mathcal{L}=\sum_{i \in \mathcal{D}}\left(y_{i} \log \left(P\left(y_{i} | \mathcal{H}_{u}, u ; \theta^{\prime}\right)\right)\right.+\left(1-y_{i}\right) \log \left(1-P\left(y_{i} | \mathcal{H}_{u}, u ; \theta^{\prime}\right)\right)\end{aligned}
\]
其中\(\mathcal H _u\)表示用户的历史行为信息,item表示物品信息,user表示人口统计学信息。可以看出个性化向量的预训练网络就是一个CTR预估网络,因此经典的Wide&Depp,DeepFM等网络都可以用来做预训练。
- 讨论
- 文章的创新主要是重排阶段引入了用户的相关特征。个人认为可以用于二次推荐,应该有帮助
- 输入层最后那个操作没有太搞明白,有理解不到位的地方欢迎讨论。
references:
Personalized Re-ranking for Recommendation.https://arxiv.org/pdf/1904.06813.pdf

