日常生活中,我们经常会遇到需要编辑PDF文件的情况,鉴于PDF格式的特殊性,必须使用专业软件才能编辑。如果不想这么麻烦,大家可以提取PDF文件并保存为Word,即可直接进行修改处理,怎样提取识别PDF文字内容?请看文章说明。
首先下载安装风云OCR文字识别软件,打开软件,进入界面,这里有多种功能,选择【PDF文档识别】,
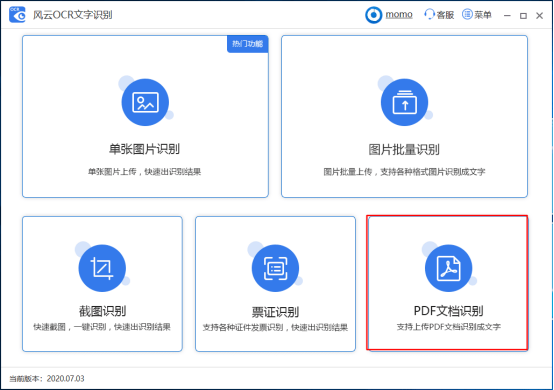
跳转界面,导入需要识别的PDF文件,点击【添加文件】,直接导入PDF文件,当然了,你也可以选中PDF文件,将其拖拽到指定区域
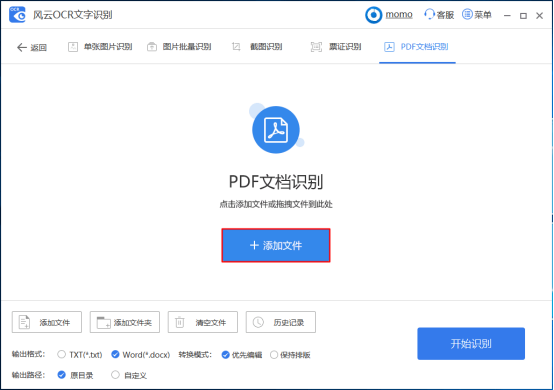
PDF文件添加成功,点击【输出格式】,你可以将PDF文件输出为Word或者TXT文本格式;点击【转换模式】,选择【优先编辑】或者【保持排版】,最后选择输出路径,设置完成,然后点击【开始识别】,

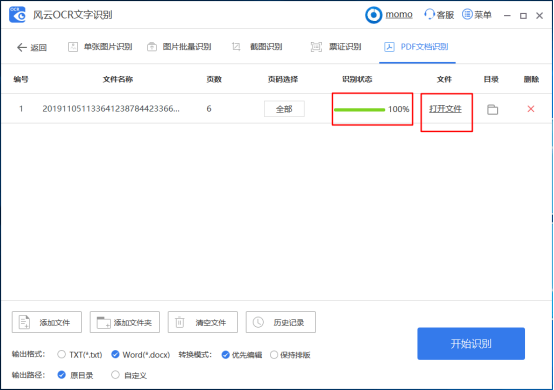
软件开始自动识别PDF文件,稍等一会儿,等待状态显示为100%,识别成功,点击【打开文件】,查看识别出来的内容,
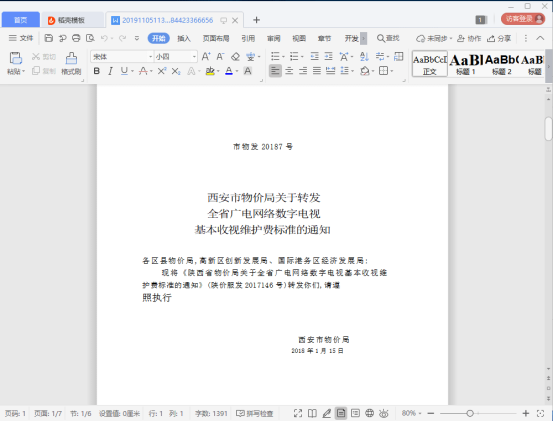
如图,PDF文件内容已经被识别保存为Word文档了,如果想要修改文字,大家可以直接进行编辑。
了解更多精彩教程资讯,关注www.softyun.net/it.html。

