为什么我们要爬取数据
在大数据时代,我们要获取更多数据,就要进行数据的挖掘、分析、筛选,比如当我们做一个项目的时候,需要大量真实的数据的时候,就需要去某些网站进行爬取,有些网站的数据爬取后保存到数据库还不能够直接使用,需要进行清洗、过滤后才能使用,我们知道有些数据是非常真贵的。
分析豆瓣电影网站
我们使用Chrome浏览器去访问豆瓣的网站如
https://movie.douban.com/explore
在Chrome浏览器的network中会得到如下的数据

可以看到地址栏上的参数type=movie&tag=热门&sort=recommend&page_limit=20&page_start=0
其中type是电影tag是标签,sort是按照热门进行排序的,page_limit是每页20条数据,page_start是从第几页开始查询。
但是这不是我们想要的,我们需要去找豆瓣电影数据的总入口地址是下面这个https://movie.douban.com/tag/
我们再次的去访问请求终于拿到了豆瓣的电影数据如下图所示
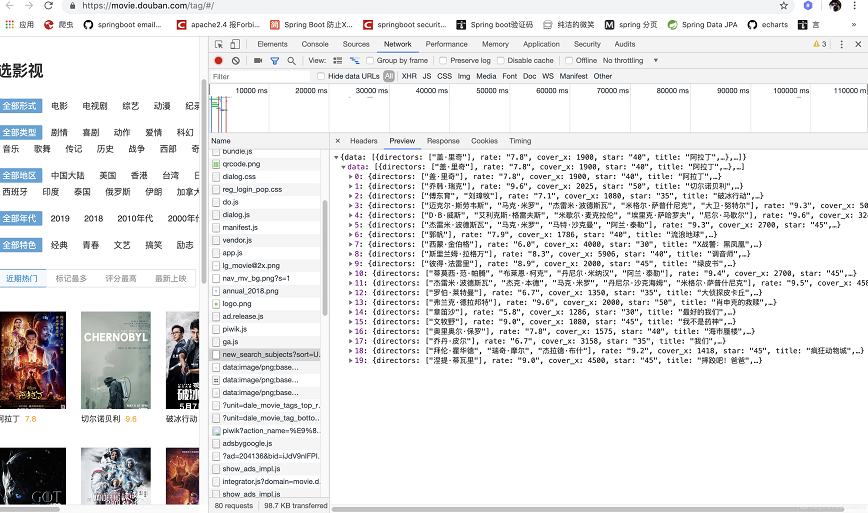
在看下请求头信息
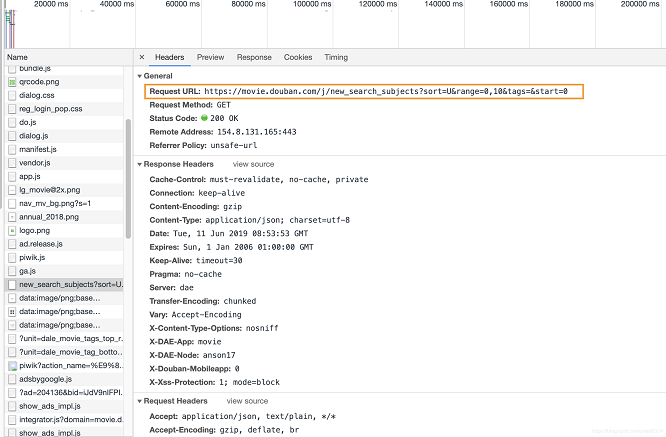

最后我们确认了爬取的入口为:https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=0
创建Maven项目开始爬取
我们创建一个maven工程,如下图所示
maven工程的依赖,这里只是爬取数据,所以没有必要使用Spring,这里使用的数据持久层框架是mybatis 数据库用的是mysql,下面是maven的依赖
<dependencies> <dependency> <groupId>org.json</groupId> <artifactId>json</artifactId> <version>20160810</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.47</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version> </dependency> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.5.1</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> </dependencies>
创建好之后,结构如下所示
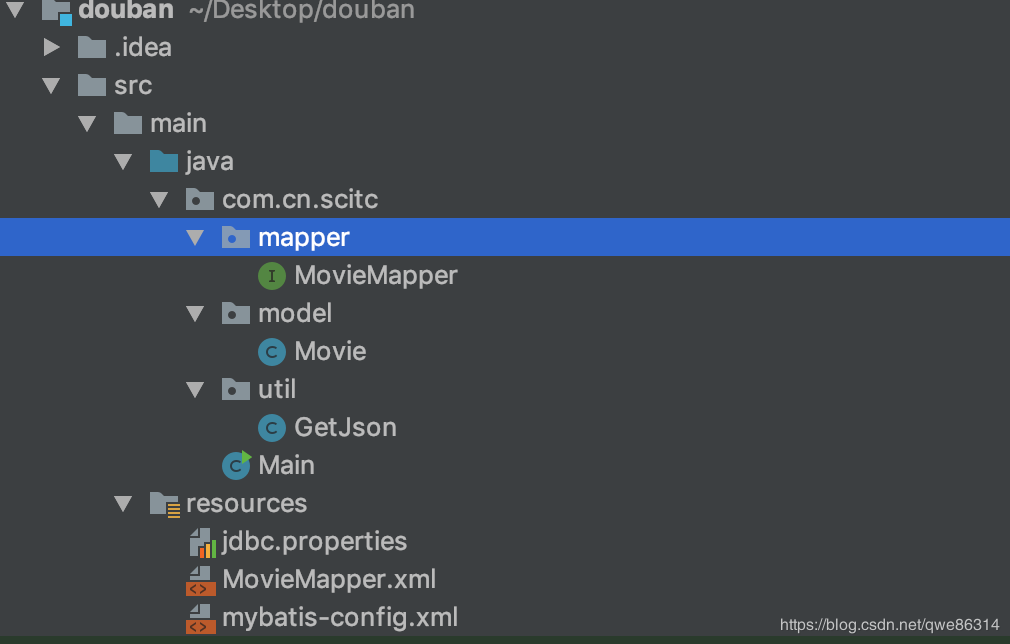
首先我们在model包中建立实体对象,字段和豆瓣电影的字段一样,就是请求豆瓣电影的json对象里面的字段

Movie实体类
public class Movie {
private String id; //电影的id
private String directors;//导演
private String title;//标题
private String cover;//封面
private String rate;//评分
private String casts;//演员
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getDirectors() {
return directors;
}
public void setDirectors(String directors) {
this.directors = directors;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getCover() {
return cover;
}
public void setCover(String cover) {
this.cover = cover;
}
public String getRate() {
return rate;
}
public void setRate(String rate) {
this.rate = rate;
}
public String getCasts() {
return casts;
}
public void setCasts(String casts) {
this.casts = casts;
}
}
这里注意的是导演和演员是多个人我没有直接处理。这里应该是一个数组对象。
创建mapper接口
public interface MovieMapper {
void insert(Movie movie);
List<Movie> findAll();
}
在resources下创建数据连接配置文件jdbc.properties
driver=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3306/huadi username=root password=root
创建mybatis配置文件 mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties resource="jdbc.properties"></properties>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="MovieMapper.xml"/>
</mappers>
</configuration>
创建mapper.xml映射文件
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.cn.scitc.mapper.MovieMapper">
<resultMap id="MovieMapperMap" type="com.cn.scitc.model.Movie">
<id column="id" property="id" jdbcType="VARCHAR"/>
<id column="title" property="title" jdbcType="VARCHAR"/>
<id column="cover" property="cover" jdbcType="VARCHAR"/>
<id column="rate" property="rate" jdbcType="VARCHAR"/>
<id column="casts" property="casts" jdbcType="VARCHAR"/>
<id column="directors" property="directors" jdbcType="VARCHAR"/>
</resultMap>
<insert id="insert" keyProperty="id" parameterType="com.cn.scitc.model.Movie">
INSERT INTO movie(id,title,cover,rate,casts,directors)
VALUES
(#{id},#{title},#{cover},#{rate},#{casts},#{directors})
</insert>
<select id="findAll" resultMap="MovieMapperMap">
SELECT * FROM movie
</select>
</mapper>
由于这里没有用任何的第三方爬虫框架,用的是原生Java的Http协议进行爬取的,所以我写了一个工具类
public class GetJson {
public JSONObject getHttpJson(String url, int comefrom) throws Exception {
try {
URL realUrl = new URL(url);
HttpURLConnection connection = (HttpURLConnection) realUrl.openConnection();
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
//请求成功
if (connection.getResponseCode() == 200) {
InputStream is = connection.getInputStream();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
//10MB的缓存
byte[] buffer = new byte[10485760];
int len = 0;
while ((len = is.read(buffer)) != -1) {
baos.write(buffer, 0, len);
}
String jsonString = baos.toString();
baos.close();
is.close();
//转换成json数据处理
// getHttpJson函数的后面的参数1,表示返回的是json数据,2表示http接口的数据在一个()中的数据
JSONObject jsonArray = getJsonString(jsonString, comefrom);
return jsonArray;
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException ex) {
ex.printStackTrace();
}
return null;
}
public JSONObject getJsonString(String str, int comefrom) throws Exception{
JSONObject jo = null;
if(comefrom==1){
return new JSONObject(str);
}else if(comefrom==2){
int indexStart = 0;
//字符处理
for(int i=0;i<str.length();i++){
if(str.charAt(i)=='('){
indexStart = i;
break;
}
}
String strNew = "";
//分割字符串
for(int i=indexStart+1;i<str.length()-1;i++){
strNew += str.charAt(i);
}
return new JSONObject(strNew);
}
return jo;
}
}
爬取豆瓣电影的启动类
public class Main {
public static void main(String [] args) {
String resource = "mybatis-config.xml"; 定义配置文件路径
InputStream inputStream = null;
try {
inputStream = Resources.getResourceAsStream(resource);//读取配置文件
} catch (IOException e) {
e.printStackTrace();
}
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);//注册mybatis 工厂
SqlSession sqlSession = sqlSessionFactory.openSession();//得到连接对象
MovieMapper movieMapper = sqlSession.getMapper(MovieMapper.class);//从mybatis中得到dao对象
int start;//每页多少条
int total = 0;//记录数
int end = 9979;//总共9979条数据
for (start = 0; start <= end; start += 20) {
try {
String address = "https://Movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=" + start;
JSONObject dayLine = new GetJson().getHttpJson(address, 1);
System.out.println("start:" + start);
JSONArray json = dayLine.getJSONArray("data");
List<Movie> list = JSON.parseArray(json.toString(), Movie.class);
if (start <= end){
System.out.println("已经爬取到底了");
sqlSession.close();
}
for (Movie movie : list) {
movieMapper.insert(movie);
sqlSession.commit();
}
total += list.size();
System.out.println("正在爬取中---共抓取:" + total + "条数据");
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
最后我们运行将所有的数据插入到数据库中。

项目地址
总结
爬取豆瓣网站非常的轻松,每页任何的难度,需要注意的是就是start是每页多少条我们发现规则当start=0的时候是20条数据是从0到19条,就这样每次加20条直到爬取完。

