接着广告模型初探(一),这篇主要介绍一下广告预估模型目前的几大派系,主要分为LR派系、FM派系、DNN派系。
(0)LR派系
a.大师兄:LR模型
废话不多说,先上公式

,其中
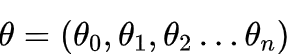
,这里我们定义一下:

,那么整个公式可以写成:
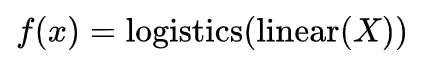
优点:模型简单、可以处理离散化特征、容易实现分布式的计算
缺点:特征与特征之间在模型中是相对独立的,对于一些存在交叉可能性的特征(比如: 衣服类型与性别,这两个特征交叉很有意义),需要进行大量的人工特征工程进行交叉。虽然模型很简单,但是人工的工作却繁重了很多。而且LR需要将特征进行离散化,归一化,在离散化过程中也可能出现边界问题。
b.二师兄:GBDT模型
公式如下:

优点:能够处理连续值特征,比如用户历史点击率,用户历史浏览次数等连续值特征;而且由于树的分裂算法,它具有一定的组合特征的能力,模型的表达能力要比LR强。GBDT对特征的数值线性变化不敏感,它会按照目标函数,自动选择最优的分裂特征和该特征的最优分裂点,而且根据特征的分裂次数,还可以得到一个特征的重要性排序。所以,使用GBDT能够减少人工特征工程的工作量和进行特征筛选。
缺点:GBDT善于处理连续值特征,但是在广告场景中,出现的都是大规模离散化特征,如果我们需要使用GBDT的话,则需要将很多特征统计成连续值特征(或者embedding),这里可能需要耗费比较多的时间。同时,因为GBDT模型特点,它具有很强的记忆行为,不利于挖掘长尾特征,而且GBDT虽然具备一定的组合特征的能力,但是组合的能力十分有限,远不能与后续介绍的DNN相比
(1)FM派系
a.大师姐:FM模型
具体公式如下:
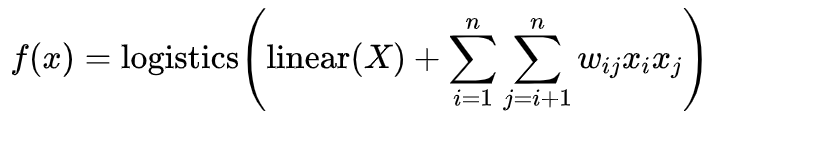
对照前面的LR模型的公式我们可以发现,FM模型主要多了一个二次交叉项,这刚好弥补了LR模型无法处理大量交叉特征的问题。从公式中我们可以发现FM需要一个二维权重矩阵wij,对于大规模离散特征来说,这个二维权重矩阵的维度会很大,为了解决这个问题,FM的作者利用矩阵分解将wij分解为了wij=<vi,vj>,所以FM的公式又可以写成
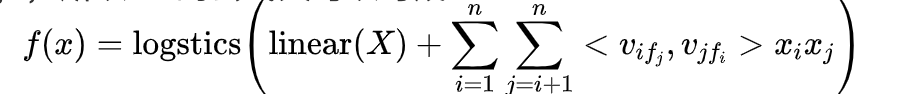
优点:可以处理二次交叉特征、可以实现线性的时间复杂度、模型训练速度快
缺点:对于不同的特征组合,采用的是同样的向量做内积,会带来一定的信息损失,因此也就引出了 “二师姐” FFM模型。
b.二师姐:FFM模型
FFM是在FM的基础上引入了“场”的概念而形成的新模型。在FM中计算特征xi与其他特征的交叉影响时,使用的都是同一个隐向量Vi。而FFM模型则事先将特征按照一定的规则分为多个场。特征xi属于某个特定的场f,每个特征将被映射为多个隐向量vi1...vif 。当两个特征xi,xj组合在一起时,用对方对应的场对应的隐向量做内积:
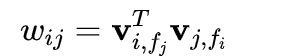
优点:FFM 由于引入了场,使得每两组特征交叉的隐向量都是独立的,可以取得更好的组合效果, FM 可以看做只有一个场的 FFM。
缺点:参数量巨大,在训练时极易过拟合。
今天先说到这儿,下一篇我们再接着介绍目前广告预估模型的集大成者DNN派系吧,后会有期!
欢迎关注微信公众号:计算广告那些事儿

不定期分享算法工程师相关面经和计算广告相关的文章

