复杂神经网络模型的实现离不开"融合"操作。常见融合操作如下:
# 求和 layers.Add(inputs) # 求差 layers.Subtract(inputs)
inputs: 一个输入张量的列表(列表大小至少为 2),列表的shape必须一样才能进行求和(求差)操作。
例子:
input1 = keras.layers.Input(shape=(16,)) x1 = keras.layers.Dense(8, activation='relu')(input1) input2 = keras.layers.Input(shape=(32,)) x2 = keras.layers.Dense(8, activation='relu')(input2) added = keras.layers.add([x1, x2]) out = keras.layers.Dense(4)(added) model = keras.models.Model(inputs=[input1, input2], outputs=out)
# 输入张量的逐元素乘积(对应位置元素相乘,输入维度必须相同) layers.multiply(inputs) # 输入张量样本之间的点积 layers.dot(inputs, axes, normalize=False)
dot即矩阵乘法,例子1:
x = np.arange(10).reshape(1, 5, 2) y = np.arange(10, 20).reshape(1, 2, 5) # 三维的输入做dot通常像这样指定axes,表示矩阵的第一维度和第二维度参与矩阵乘法,第0维度是batchsize tf.keras.layers.Dot(axes=(1, 2))([x, y]) # 输出如下: <tf.Tensor: shape=(1, 2, 2), dtype=int64, numpy= array([[[260, 360], [320, 445]]])>
例子2:
x1 = tf.keras.layers.Dense(8)(np.arange(10).reshape(5, 2)) x2 = tf.keras.layers.Dense(8)(np.arange(10, 20).reshape(5, 2)) dotted = tf.keras.layers.Dot(axes=1)([x1, x2]) dotted.shape TensorShape([5, 1])
# 所有输入张量通过 axis 轴串联起来的输出张量。 layers.add(inputs,axis=-1)
例子:
x1 = tf.keras.layers.Dense(8)(np.arange(10).reshape(5, 2)) x2 = tf.keras.layers.Dense(8)(np.arange(10, 20).reshape(5, 2)) concatted = tf.keras.layers.Concatenate()([x1, x2]) concatted.shape TensorShape([5, 16])
求均值layers.Average()
input1 = tf.keras.layers.Input(shape=(16,)) x1 = tf.keras.layers.Dense(8, activation='relu')(input1) input2 = tf.keras.layers.Input(shape=(32,)) x2 = tf.keras.layers.Dense(8, activation='relu')(input2) avg = tf.keras.layers.Average()([x1, x2]) # x_1 x_2 的均值作为输出 print(avg) # <tf.Tensor 'average/Identity:0' shape=(None, 8) dtype=float32> out = tf.keras.layers.Dense(4)(avg) model = tf.keras.models.Model(inputs=[input1, input2], outputs=out)
layers.Maximum()用法相同。
假设要构造这样一个模型:
工单标题(文本输入),工单的文本正文(文本输入),以及用户添加的任何标签(分类输入)
模型大概长这样:
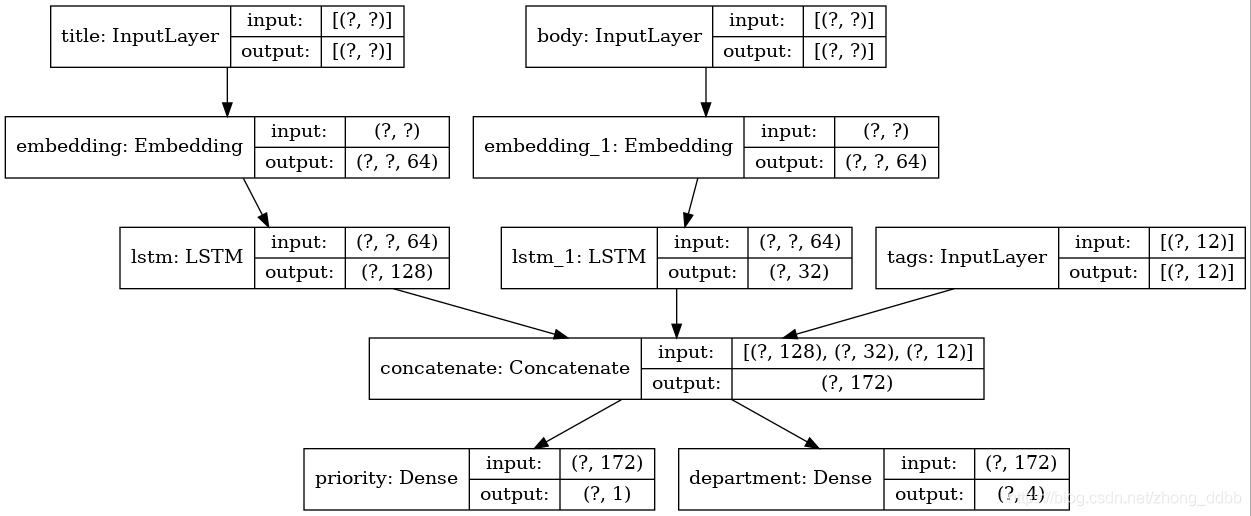
接下来开始创建这个模型。
(1)模型的输入
num_tags = 12 num_words = 10000 num_departments = 4 title_input = keras.Input(shape=(None,), name="title") # Variable-length sequence of ints body_input = keras.Input(shape=(None,), name="body") # Variable-length sequence of ints tags_input = keras.Input(shape=(num_tags,), name="tags") # Binary vectors of size `num_tags`
(2)将输入的每一个词进行嵌入成64-dimensional vector
title_features = layers.Embedding(num_words,64)(title_input) body_features = layers.Embedding(num_words,64)(body_input)
(3)处理结果输入LSTM模型,得到 128-dimensional vector
title_features = layers.LSTM(128)(title_features) body_features = layers.LSTM(32)(body_features)
(4)concatenate融合所有的特征
x = layers.concatenate([title_features, body_features, tags_input])
(5)模型的输出
# 输出1,回归问题 priority_pred = layers.Dense(1,name="priority")(x) # 输出2,分类问题 department_pred = layers.Dense(num_departments,name="department")(x)
(6)定义模型
model = keras.Model( inputs=[title_input, body_input, tags_input], outputs=[priority_pred, department_pred], )
(7)模型编译
编译此模型时,可以为每个输出分配不同的损失。甚至可以为每个损失分配不同的权重,以调整其对总训练损失的贡献。
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={
"priority": keras.losses.BinaryCrossentropy(from_logits=True),
"department": keras.losses.CategoricalCrossentropy(from_logits=True),
},
loss_weights=[1.0, 0.2],
)
(8)模型的训练
# Dummy input data
title_data = np.random.randint(num_words, size=(1280, 10))
body_data = np.random.randint(num_words, size=(1280, 100))
tags_data = np.random.randint(2, size=(1280, num_tags)).astype("float32")
# Dummy target data
priority_targets = np.random.random(size=(1280, 1))
dept_targets = np.random.randint(2, size=(1280, num_departments))
# 通过字典的形式将数据fit到模型
model.fit(
{"title": title_data, "body": body_data, "tags": tags_data},
{"priority": priority_targets, "department": dept_targets},
epochs=2,
batch_size=32,
)
通过add来实现融合操作,模型的基本结构如下:
# 实现第一个块 _input = keras.Input(shape=(32,32,3)) x = layers.Conv2D(32,3,activation='relu')(_input) x = layers.Conv2D(64,3,activation='relu')(x) block1_output = layers.MaxPooling2D(3)(x) # 实现第二个块 x = layers.Conv2D(64,3,padding='same',activation='relu')(block1_output) x = layers.Conv2D(64,3,padding='same',activation='relu')(x) block2_output = layers.add([x,block1_output]) # 实现第三个块 x = layers.Conv2D(64, 3, activation="relu", padding="same")(block2_output) x = layers.Conv2D(64, 3, activation="relu", padding="same")(x) block_3_output = layers.add([x, block2_output]) # 进入全连接层 x = layers.Conv2D(64,3,activation='relu')(block_3_output) x = layers.GlobalAveragePooling2D()(x) x = layers.Dense(256, activation="relu")(x) x = layers.Dropout(0.5)(x) outputs = layers.Dense(10)(x)
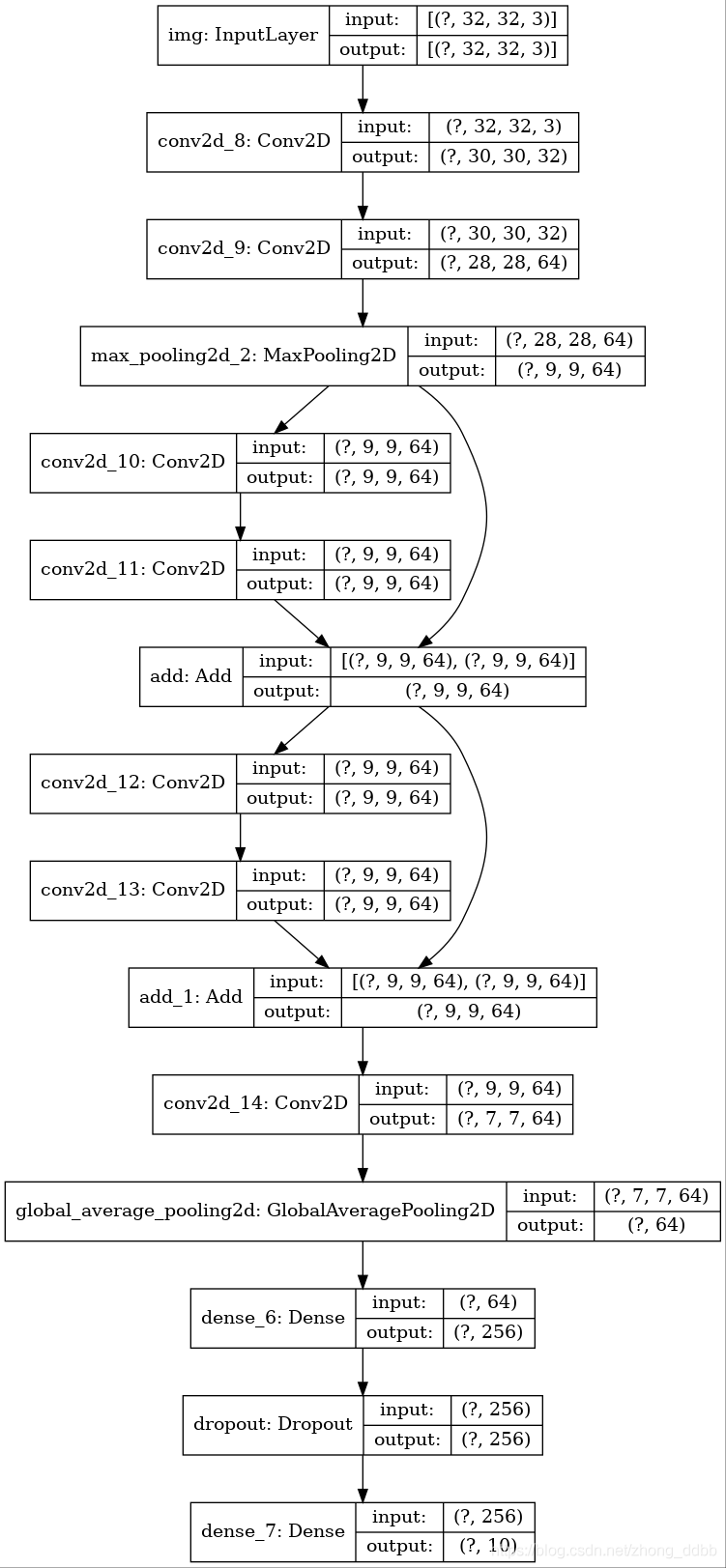
模型的定义与编译:
model = keras.Model(_input,outputs,name='resnet') model.compile( optimizer=keras.optimizers.RMSprop(1e-3), loss='sparse_categorical_crossentropy', metrics=["acc"], )
模型的训练
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# 归一化
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
model.fit(tf.expand_dims(x_train,-1), y_train, batch_size=64, epochs=1, validation_split=0.2)
注:当loss = =keras.losses.CategoricalCrossentropy(from_logits=True)时,需对标签进行one-hot:
y_train = keras.utils.to_categorical(y_train, 10)

