基本环境配置
相关模块pip安装即可
目标网页
请求网页
import requests
url = 'https://www.tukuppt.com/peiyue/zonghe_0_0_0_0_0_0_1.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
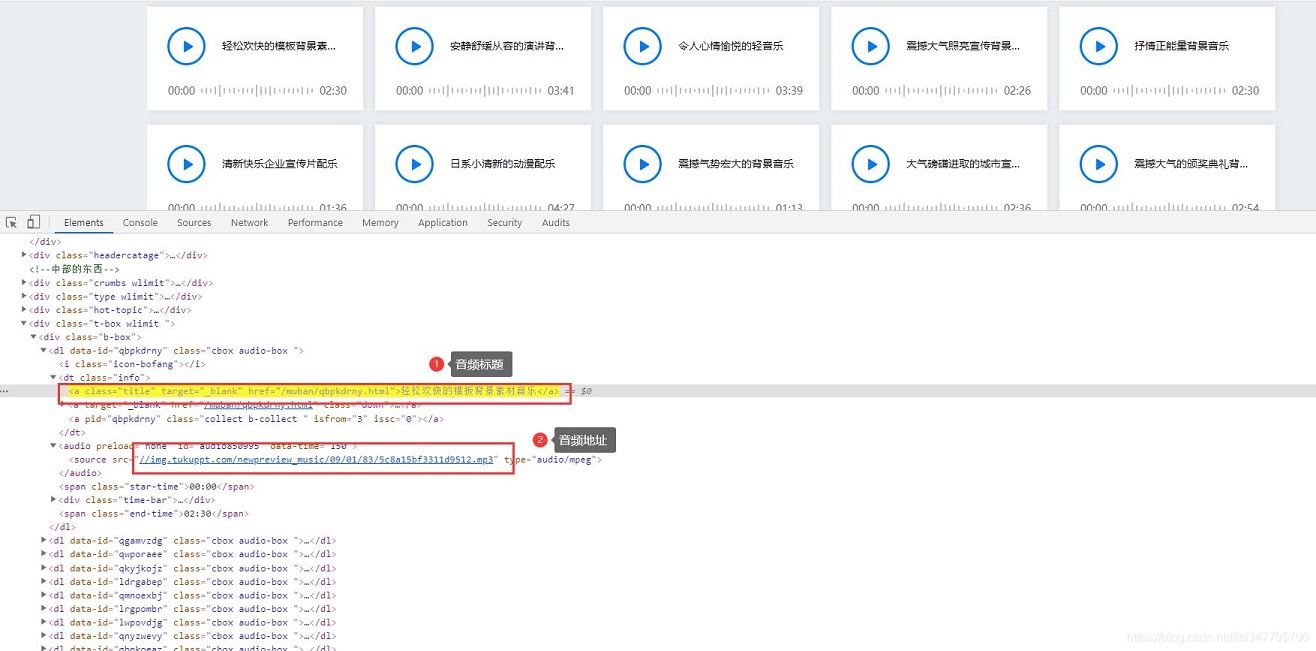
解析网页,提取数据
import parsel
selector = parsel.Selector(response.text)
urls = selector.css('#audio850995 source::attr(src)').getall()
titles = selector.css('.b-box .info .title::text').getall()
data = zip(urls, titles)
for i in data:
mp3_url = 'https:' + i[0]
title = i[1]
保存数据
def download(url, title):
response = requests.get(url=url, headers=headers)
path = 'D:\\python\\demo\\熊猫办公素材\\背景音乐\\' + title + '.mp3'
with open(path, mode='wb') as f:
f.write(response.content)



