Scrapy批量运行爬虫文件的两种方法:
1、使用CrawProcess实现
https://doc.scrapy.org/en/latest/topics/practices.html
2、修改craw源码+自定义命令的方式实现
(1)我们打开scrapy.commands.crawl.py 文件可以看到:
def run(self, args, opts):
if len(args) < 1:
raise UsageError()
elif len(args) > 1:
raise UsageError("running 'scrapy crawl' with more than one spider is no longer supported")
spname = args[0]
self.crawler_process.crawl(spname, **opts.spargs)
self.crawler_process.start()
这是crawl.py 文件中的run() 方法,在此可以指定运行哪个爬虫,要运行所有的爬虫,则需要更改这个方法。
run() 方法中通过crawler_process.crawl(spname, **opts.spargs) 实现了爬虫文件的运行,spname代表爬虫名。要运行多个爬虫文件,首先要获取所有的爬虫文件,可以通过crawler_process.spider_loader.list() 实现。
(2)实现过程:
a、在spider目录的同级目录下创建存放源代码的文件夹mycmd,并在该目录下创建文件mycrawl.py;
b、将crawl.py 中的代码复制到mycrawl.py 文件中,然后进行修改:
#修改后的run() 方法
def run(self, args, opts):
#获取爬虫列表
spd_loader_list = self.crawler_process.spider_loader.list()
#遍历各爬虫
for spname in spd_loader_list or args:
self.crawler_process.crawl(spname, **opts.spargs)
print("此时启动的爬虫:"+spname)
self.crawler_process.start()
同时可以修改:
def short_desc(self):
return "Run all spider"
c、在mycmd文件夹下添加一个初始化文件__init__.py,在项目配置文件(setting.py)中添加格式为“COMMANDS_MODULES='项目核心目录.自定义命令源码目录'”的配置;
例如:COMMANDS_MODULE = 'firstpjt.mycmd'
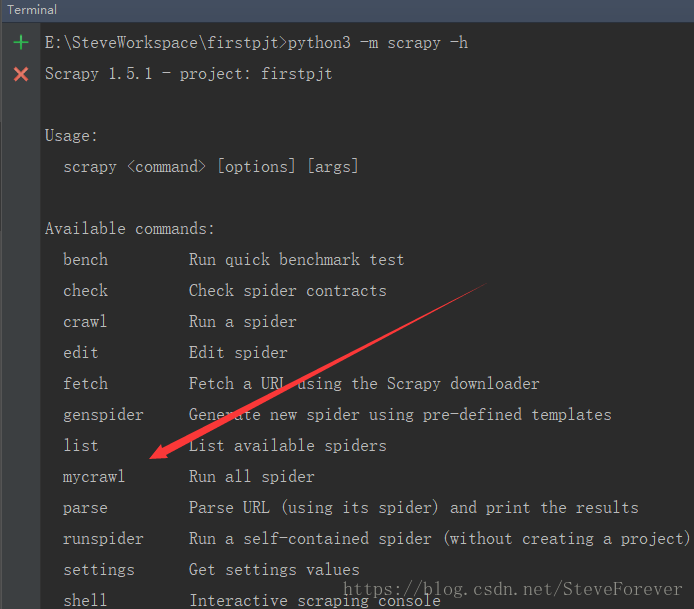
随后通过命令“scrapy -h”,可以查看到我们添加的命令mycrawl
这样,我们就可以同时启动多个爬虫文件了,使用命令:
scrapy mycrawl --nolog