[TOC]
>在k8s中所有的对象都叫做资源,例如:pod,service等
#Pod 资源
pod是在k8s中最小单元,前面有提到,k8s支持自愈,弹性扩容等高级特性,那么如果单纯的在k8s节点中跑业务docker是没有办法支持这些高级特性,必须要有定制化的容器,那么,pod就是这个官方已经定制化好的支持高级特性的容器,当启动一个pod时,至少会有两个容器,`pod容器``和业务容器`,多个业务容器会共享一个pod容器(一组容器的集合),那么一个Pod中的容器共享网络命名空间,
**Pod容器分类**
* Infrastructure Container:基础容器,维护整个Pod网络空间
* InitContainers:初始化容器,先于业务容器开始执行
* Containers:业务容器,并行启动
**Pod存在的意义:为亲密性应用而存在**
* 两个应用之间发生文件交互
* 两个应用需要通过127.0.0.1或socker通信
* 两个应用需要发生频繁的调用
**镜像拉取策略**
```js
imagePullPolicy
1、ifNotPresent:默认值,镜像在宿主机上不存在时才拉取
2、Always:每次创建Pod都会重新拉取一次镜像
3、Never:Pod永远不会主动拉取这个镜像
```
**1.pod基本操作**
```bash
// 指定yaml文件创建pod
kubectl create -f [yaml文件路径]
// 查看pod基本信息
kubectl get pods
// 查看pod详细信息
kubectl describe pod [pod名]
// 更新pod(修改了yaml内容)
kubectl apply -f [yaml文件路径]
// 删除指定pod
kubectl delete pod [pod名]
// 强制删除指定pod
kubectl delete pod [pod名] --foce --grace-period=0
```
**2.pod yaml配置文件**
```yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx01
labels:
app: web
spec:
containers:
- name: nginx01
image: reg.betensh.comhttps://img.qb5200.com/download-x/docker_case/nginx:1.13
ports:
- containerPort: 80
```
**Pod与controllers的关系**
* controllers:在集群上管理和运行容器的对象
* 通过`label-selector`相关联
* Pod通过控制器实现应用的运维,如伸缩,滚动升级等。
#RC 副本控制器
Replication Controller 副本控制器,应用托管在Kubernetes之后,Kubernetes需要保证应用能够持续运行,这是RC的工作内容,它会确保任何时间Kubernetes中都有指定数量的Pod正在运行。在此基础上,RC还提供了一些高级的特性,比如滚动升级、升级回滚等。
>在新版本的 Kubernetes 中建议使用 ReplicaSet(简称为RS )来取代 ReplicationController
**1.创建一个rc**
```yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: myweb
spec:
replicas: 2
selector:
app: myweb
template:
metadata:
labels:
app: myweb
spec:
containers:
- name: nginx01
image: reg.betensh.comhttps://img.qb5200.com/download-x/docker_case/nginx:1.13
ports:
- containerPort: 80
```
默认情况下`pod名`会以`rc名+随机值`组成,如下:
```bash
[root@k8s-master01 rc]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myweb-0lp57 1/1 Running 0 45s
myweb-zgfcf 1/1 Running 0 45s
```
RC通过标签选择器(labels)来控制pod,RC名称必须要和标签选择器名称一致
```bash
[root@k8s-master01 rc]# kubectl get rc -o wide
NAME DESIRED CURRENT READY AGE CONTAINER(S) IMAGE(S) SELECTOR
myweb 2 2 2 12m nginx01 reg.betensh.comhttps://img.qb5200.com/download-x/docker_case/nginx:1.13 app=myweb
```
**2.RC滚动升级**
前面我们已经创建一个v1版本的http-server的pod在k8s环境中,如果我们想要做一次版本升级该怎么办呢?难道把原来的pod停掉,再使用新的镜像拉起来一个新的pod吗,这样做明显是不合适的。
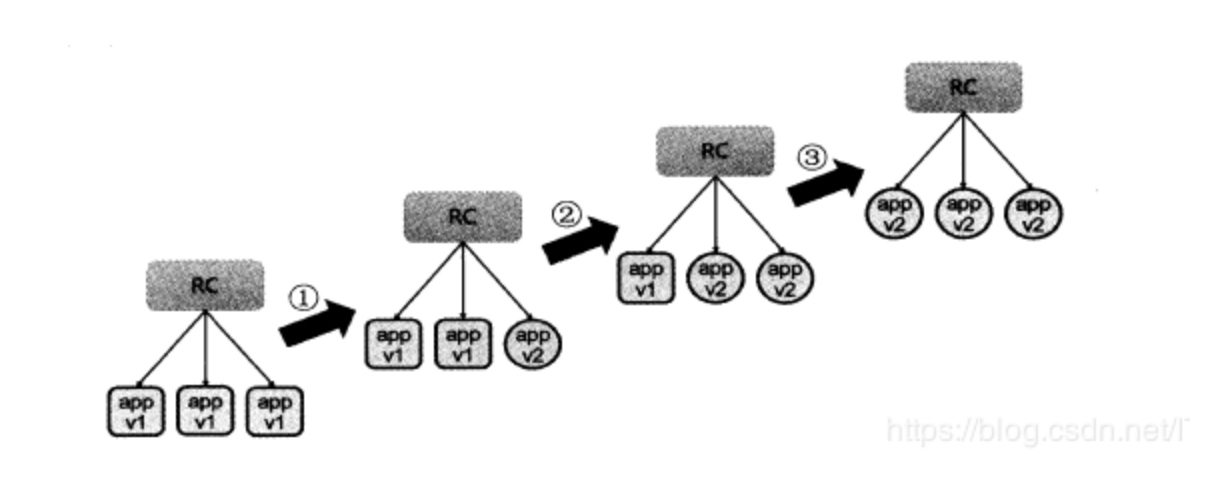
```bash
kubectl rolling-update myweb -f nginx_rc_v2.yaml --update-period=30s
```
**3.RC滚动回退**
假设现在myweb升级到myweb2,出现了bug,那么先强制中断升级
```bash
kubectl rolling-update myweb -f nginx_rc_v2.yaml --update-period=50s
```
然后将myweb2的版本回滚到myweb
```bash
kubectl rolling-update myweb myweb2 --rollback
```
#deployment 资源
deployment也是保证pod高可用的一种方式,明明有RC为何还要引入deployment呢?
因为deployment解决了RC的一个痛点,当使用RC升级容器版本后,标签会发生变化,那么svc的标签还是原来的,这样就需要手动修改svc配置文件。
Deployment 为`Pod`和`ReplicaSet`之上,提供了一个声明式定义(declarative)方法,用来替代以前的`ReplicationController`来方便的管理应用。
你只需要在`Deployment`中描述您想要的`目标状态`是什么,`Deployment controller `就会帮您将`Pod`和`ReplicaSet`的实际状态改变到您的`目标状态`。您可以定义一个全新的`Deployment`来,创建`ReplicaSet`或者删除已有的 `Deployment`并创建一个新的来替换。也就是说`Deployment`是可以`管理多个ReplicaSet`的,如下图:
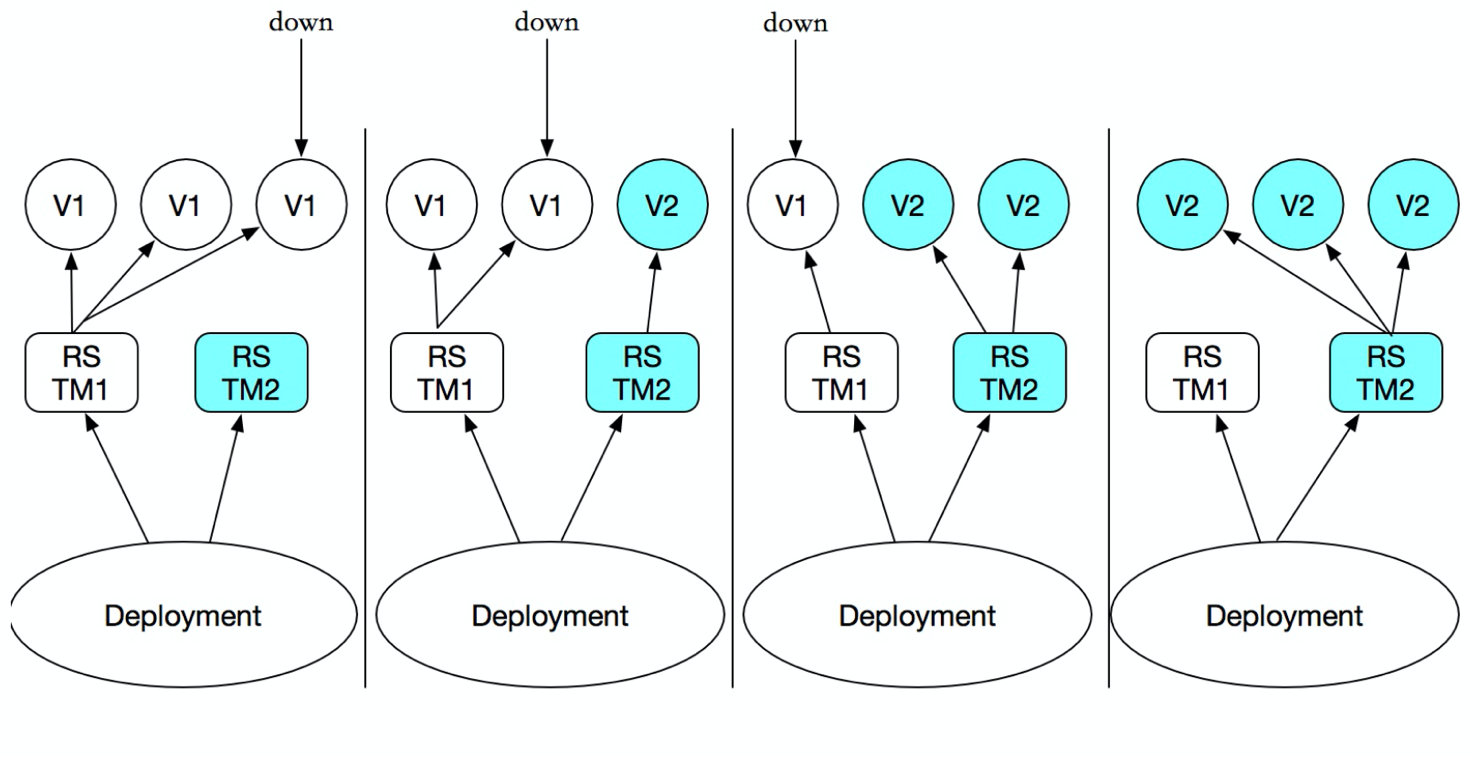
>虽然也 ReplicaSet 可以独立使用,但建议使用 Deployment 来自动管理 ReplicaSet,这样就无需担心跟其他机制的不兼容问题
**1.创建一个deployment**
```bash
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.13
ports:
- containerPort: 80
// 启动
[root@k8s-master01 deploy]# kubectl create -f nginx_deploy.yaml
```
查看deployment启动状态
>deployment会先启动一个rs,而后在启动pod
```bash
[root@k8s-master01 deploy]# kubectl get all
NAME READY STATUS RESTARTS AGE
pod/nginx-deployment-fcfcc984f-t2bk4 1/1 Running 0 33s
pod/nginx-deployment-fcfcc984f-vg7qt 1/1 Running 0 33s
pod/nginx-deployment-fcfcc984f-zhwxg 1/1 Running 0 33s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 443/TCP 16h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx-deployment 3/3 3 3 33s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-deployment-fcfcc984f 3 3 3 33s
```
**2.关联service**
```bash
kubectl expose deployment nginx-deployment --port=80 --type=NodePort
```
查看svc
```bash
[root@k8s-master01 deploy]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 16h
nginx-deployment NodePort 10.96.171.141 80:31873/TCP 25s
```
访问svc地址以及端口
```bash
[root@k8s-master01 deploy]# curl -I 10.0.0.33:31873
HTTP/1.1 200 OK
Server: nginx/1.13.12
Date: Thu, 14 Nov 2019 05:44:51 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Mon, 09 Apr 2018 16:01:09 GMT
Connection: keep-alive
ETag: "5acb8e45-264"
Accept-Ranges: bytes
```
**3.deployment升级**
```bash
// 直接编辑对应deployment,并修改镜像版本
kubectl edit deployment nginx-deployment
// 通过 set image 发布新的镜像
kubectl set image deploy nginx-deployment nginx-deployment=nginx:1.17
```
**4.deployment回滚**
```bash
// 回滚到上一级版本
kubectl rollout undo deployment nginx-deployment
// 回滚到指定版本
kubectl rollout undo deployment nginx-deployment --to-revision=1
// 查看当前deploy历史版本
kubectl rollout history deployment nginx-deployment
```
**5.命令行方式实现发布版本**
```bash
# kubectl run nginx --image=nginx:1.13 --replicas=3 --record
# kubectl rollout history deployment nginx
deployment.extensions/nginx
# kubectl set image deployment nginx nginx=nginx:1.15
```
#Headless Service
在K8S里,我们想要通过name来访问服务的方式就是在`Deployment`上面添加一层`Service`,这样我们就可以通过`Service name`来访问服务了,那其中的原理就是和`CoreDNS`有关,它将`Service name`解析成`Cluster IP`,这样我们访问`Cluster IP`的时候就通过Cluster IP作负载均衡,把流量分布到`各个POD`上面。我想的问题是`CoreDNS`是否会直接解析POD的name,在Service的服务里,是不可以的,因为Service有Cluster IP,直接被CoreDNS解析了,那怎么才能让它解析POD呢,有大牛提出了可以使用`Headless Service`,所以我们就来探究一下什么是`Headless Service`。
`Headless Service`也是一种`Service`,但不同的是会定义`spec:clusterIP: None`,也就是不需要`Cluster IP的Service`。
我们首先想想`Service的Cluster IP`的工作原理:一个`Service`可能对应多个`EndPoint(Pod)`,`client`访问的是`Cluster IP`,通过`iptables`规则转到`Real Server`,从而达到负载均衡的效果。具体操作如下所示:
1、web-demo.yaml
```yaml
#deploy
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: web-demo
namespace: dev
spec:
# 指定svc名称
serviceName: web-demo-svc
replicas: 3
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: 10.0.0.33/base_images/web-demo:v1.0
ports:
- containerPort: 8080
resources:
requests:
memory: 1024Mi
cpu: 500m
limits:
memory: 2048Mi
cpu: 2000m
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 3
successThreshold: 1
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /hello
port: 8080
scheme: HTTP
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 1
successThreshold: 1
timeoutSeconds: 5
---
#service
apiVersion: v1
kind: Service
metadata:
name: web-demo-svc
namespace: dev
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
clusterIP: None
selector:
app: web-demo
```
查看svc,发现`ClusterIP`为`None`
```
$ kubectl get svc -n dev | grep "web-demo-svc"
web-demo-svc ClusterIP None 80/TCP 12s
```
pod会按照顺序创建
```bash
$ kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
web-demo-0 1/1 Running 0 7m2s
web-demo-1 1/1 Running 0 6m39s
web-demo-2 1/1 Running 0 6m15s
```
登录到Cluster的内部pod
```bash
$ kubectl exec -it web-demo-0 sh -n dev
/ # nslookup web-demo-svc
Name: web-demo-svc
Address 1: 10.244.2.67 web-demo-0.web-demo-svc.dev.svc.cluster.local
Address 2: 10.244.3.12 web-demo-2.web-demo-svc.dev.svc.cluster.local
Address 3: 10.244.1.214 web-demo-1.web-demo-svc.dev.svc.cluster.local
```
>总结:通过dns访问,会返回后端pods的列表
#StatefulSet
首先`Deployment`只是用于无状态服务,无差别并且没有顺序的Pod,而StatefulSet支持多个Pod之间的顺序性,用于 每个Pod中有自己的编号,需要互相访问,以及持久存储区分
**Pod顺序性**
1、headless-service.yaml
```yaml
apiVersion: v1
kind: Service
metadata:
name: springboot-web-svc
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
clusterIP: None
selector:
app: springboot-web
```
2、statefulset.yaml
```yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: springboot-web
spec:
# serviceName 该字段是告诉statefulSet用那个headless server去保证每个的解析
serviceName: springboot-web-svc
replicas: 2
selector:
matchLabels:
app: springboot-web
template:
metadata:
labels:
app: springboot-web
spec:
containers:
- name: springboot-web
image: 10.0.0.33/base_images/web-demo:v1.0
ports:
- containerPort: 8080
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 3
successThreshold: 1
timeoutSeconds: 5
```
查看pod
```bash
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
springboot-web-0 1/1 Running 0 118s
springboot-web-1 1/1 Running 0 116s
```
进入一个pod,而通过pod name访问另外一个pod
```bash
$ kubectl exec -it springboot-web-0 sh
/ # ping springboot-web-1.springboot-web-svc
PING springboot-web-1.springboot-web-svc (10.244.2.68): 56 data bytes
64 bytes from 10.244.2.68: seq=0 ttl=62 time=1.114 ms
64 bytes from 10.244.2.68: seq=1 ttl=62 time=0.698 ms
```
**持久化存储**
自动根据pod创建pvc
```yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-demo
spec:
serviceName: springboot-web-svc
replicas: 2
selector:
matchLabels:
app: nginx-demo
template:
metadata:
labels:
app: springboot-web
spec:
containers:
- name: springboot-web
image: 10.0.0.33/base_images/nginx:1.13
ports:
- containerPort: 8080
volumeMounts:
- name: data
mountPath: /
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- ReadWriteOnce
storageClassName: glusterfs-storage-class
resources:
requests:
storage: 1Gi
```
#DaemonSet
DaemonSet是在Kubernetes1.2 版本新增的一种资源对象
`DaemonSet`能够让`所有(或者一些特定)的Node`节点`仅运行一份Pod`。当节点加入到kubernetes集群中,Pod会被(DaemonSet)调度到该节点上运行,当节点从kubernetes集群中被移除,被(DaemonSet)调度的Pod会被移除,如果删除DaemonSet,所有跟这个DaemonSet相关的pods都会被删除。
在使用kubernetes来运行应用时,很多时候我们需要在一个`区域(zone)`或者`所有Node`上运行`同一个守护进程(pod)`,例如如下场景:
* 每个Node上运行一个分布式存储的守护进程,例如glusterd,ceph
* 运行日志采集器在每个Node上,例如fluentd,logstash
* 运行监控的采集端在每个Node,例如prometheus node exporter,collectd等
DaemonSet的Pod调度策略与RC很类似,除了使用系统内置的调度算法在每个Node上进行调度,也可以在Pod定义中使用NodeSelector或NodeAffinity来指定满足条件的Node范围进行调度
DaemonSet 资源文件格式
```yaml
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
```
下面例子定义为在每个Node上都启动一个`filebeat`容器,其中挂载了宿主机目录"/var/log/messages"
```yaml
$ vi k8s-log-filebeat.yaml
apiVersion: v1
kind: ConfigMap # 定义一个config文件内容
metadata:
name: k8s-logs-filebeat-config
namespace: kube-system
data:
# 填写filebeat读取日志相关信息
filebeat.yml: |-
filebeat.prospectors:
- type: log
paths:
- /messages
fields:
app: k8s
type: module
fields_under_root: true
output.logstash:
# specified logstash port (by default 5044)
hosts: ['10.0.0.100:5044']
---
apiVersion: apps/v1
kind: DaemonSet # DaemonSet 对象,保证在每个node节点运行一个副本
metadata:
name: k8s-logs
namespace: kube-system
spec:
selector:
matchLabels:
project: k8s
app: filebeat
template:
metadata:
labels:
project: k8s
app: filebeat
spec:
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat:6.8.1
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 500Mi
securityContext:
runAsUser: 0
# 进行实际挂载操作
volumeMounts:
# 将configmap里的配置挂载到 /etc/filebeat.yml 文件中
- name: filebeat-config
mountPath: /etc/filebeat.yml
subPath: filebeat.yml
# 将宿主机 /var/log/messages 路径挂载到 /messages中
- name: k8s-logs
mountPath: /messages
# 定义卷
volumes:
- name: k8s-logs
hostPath:
path: /var/log/messages
type: File
- name: filebeat-config
configMap:
name: k8s-logs-filebeat-config
```
使用kubectl create 命令创建该DeamonSet
```bash
$ kubectl create -f k8s-log-filebeat.yaml
configmap/k8s-logs-filebeat-config created
daemonset.apps/k8s-logs created
```
查看创建好的DeamonSet和Pod,可以看到在每个Node上都创建了一个Pod
```bash
$ kubectl get ds -n kube-system | grep "k8s-logs"
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
k8s-logs 2 2 0 2 0 2m15s
$ kubectl get pods -n kube-system -o wide | grep "k8s-logs"
k8s-logs-gw4bs 0/1 Running 0 87s k8s-node01
k8s-logs-p6r6t 0/1 Running 0 87s k8s-node02
```
在kubernetes 1.6以后的版本中,DaemonSet也能执行滚动升级了,即在更新一个DaemonSet模板的时候,旧的Pod副本会被自动删除,同时新的Pod副本会被自动创建,此时DaemonSet的更新策略(updateStrategy)为RollingUpdate,如下:
```yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: k8s-logs
namespace: kube-system
spec:
updateStrategy:
type: RollingUpdate
```
>updateStrategy 的另外一个值是OnDelete,即只有当手工删除了DaemonSet创建的Pod副本,新的Pod副本才会被创建出来,如果不设置updateStrategy的值,则在kubernetes 1.6之后的版本中会被默认设置为RollingUpdate(滚动升级)。
#Service 资源
我们都知道在kubernetes中以Pod为最小调度单位,并且它的特性就是不确定性,即随时会被销毁和重新创建、不确定性会导致每个Pod会通过调度器将其部署到不同的N个Node节点,这样会导致Pod ip地址会发生变化;
举个例子,web场景,分为前端后端,前端需要去调用后端资源,如果后端的Pod天生的不确定性导致IP地址不同,那么前端肯定是无法做到自动切换连接后端的IP地址,所以需要通过Service去发现Pod并获取其IP地址。
**Pod与Service的关系**
* 防止Pod失联.,获取Pod信息(通过label-selector关联)
* 定义一组Pod的访问策略(负载均衡 TCP/UDP 4层)
* 支持ClusterIP,NodePort以及LoadBalancer 三种类型
* Server的底层实现主要有iptables和IPVS二种网络模式
>每个Service关联一个应用
**Service类型**
* ClusterIP:默认,分配一个集群内部可以访问的虚拟IP(vip)
* NodePort:在每个Node上分配一个端口作为外部访问入口
* LoadBalancer:工作在特定的Cloud Provider上,例如Google Cloud, AWS,OpenStack
**1.Cluster IP详解:**
>Cluster IP,也叫VIP,主要实现不同Pod之间互相访问
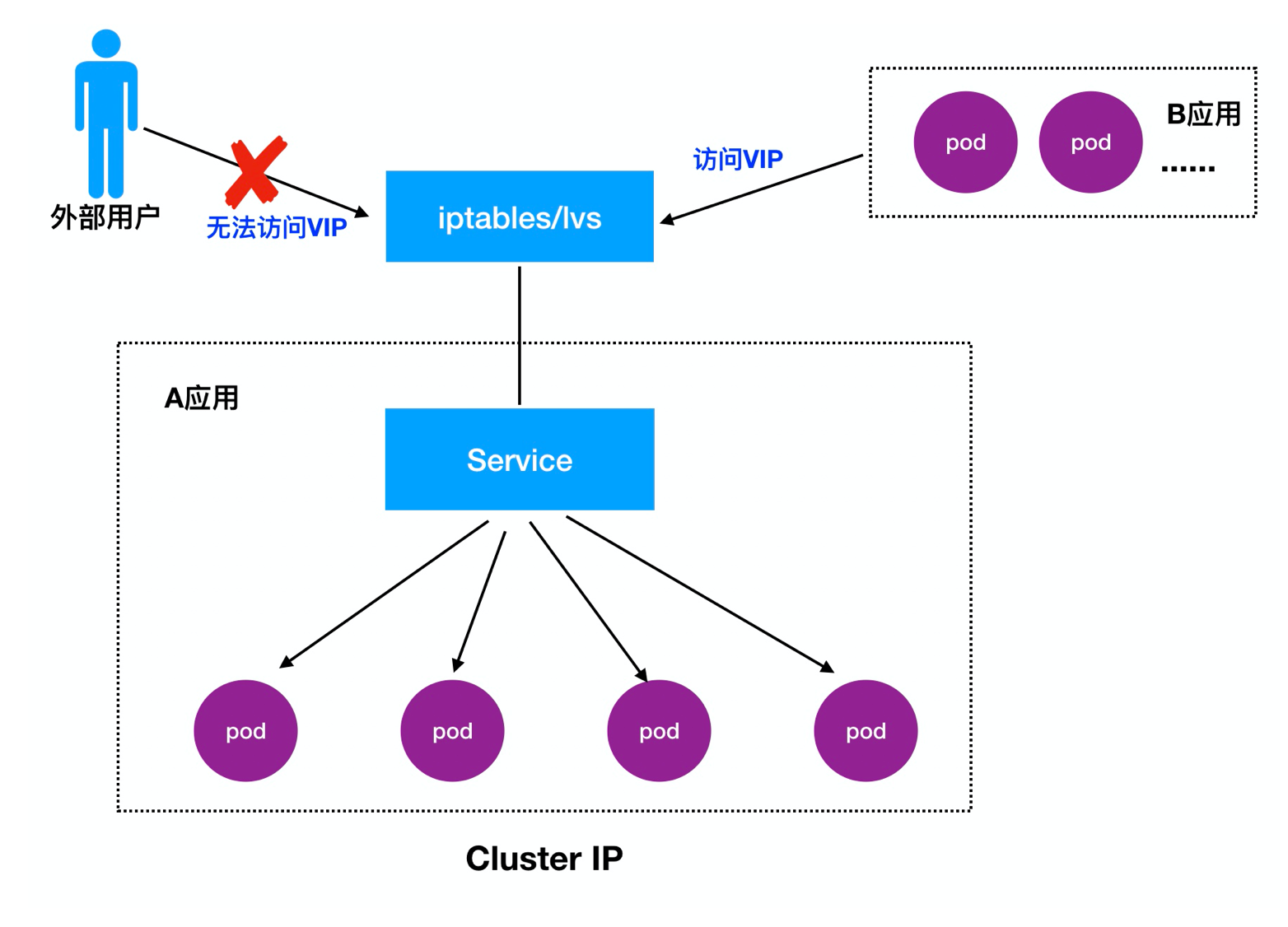
```yaml
type: NodePort
ports:
- port: 80
targetPort: 80
protocol: TCP
```
**开启proxy访问**
kubectl proxy 让外部网络访问K8S service的ClusterIP
```bash
kubectl proxy --address='0.0.0.0' --accept-hosts='^*$' --port=8009
http://[k8s-master]:8009/api/v1/namespaces/[namespace-name]/services/[service-name]/proxy
```
详细:https://blog.csdn.net/zwqjoy/articlehttps://img.qb5200.com/download-x/details/87865283
**2.Node Port详解:**
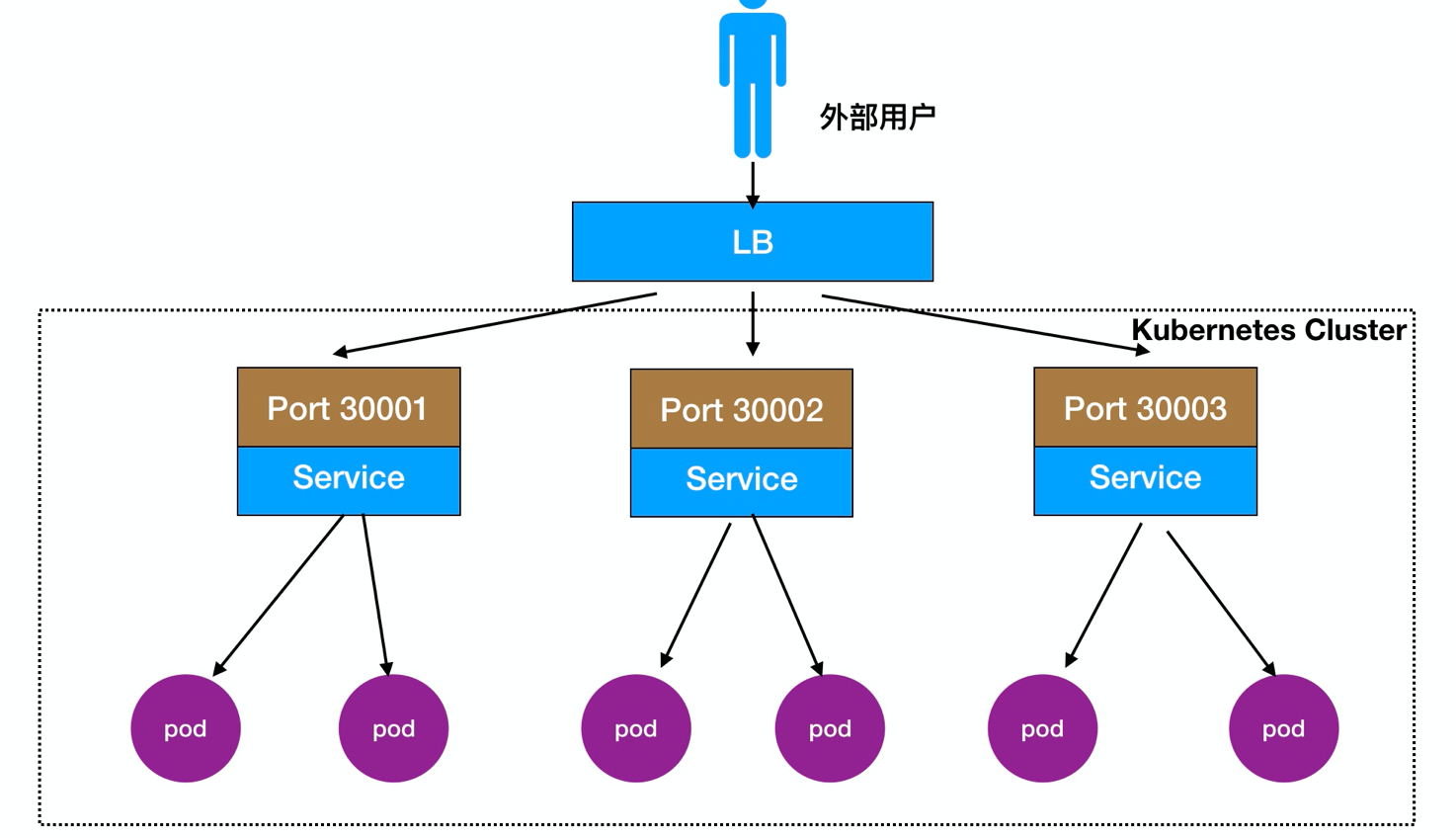
>实现外部用户可以访问节点Node,节点Node会将其流量转发到内部Pod
访问流程:用户 -> 域名 -> 负载均衡器 -> NodeIP:Port ->PodIP:Port
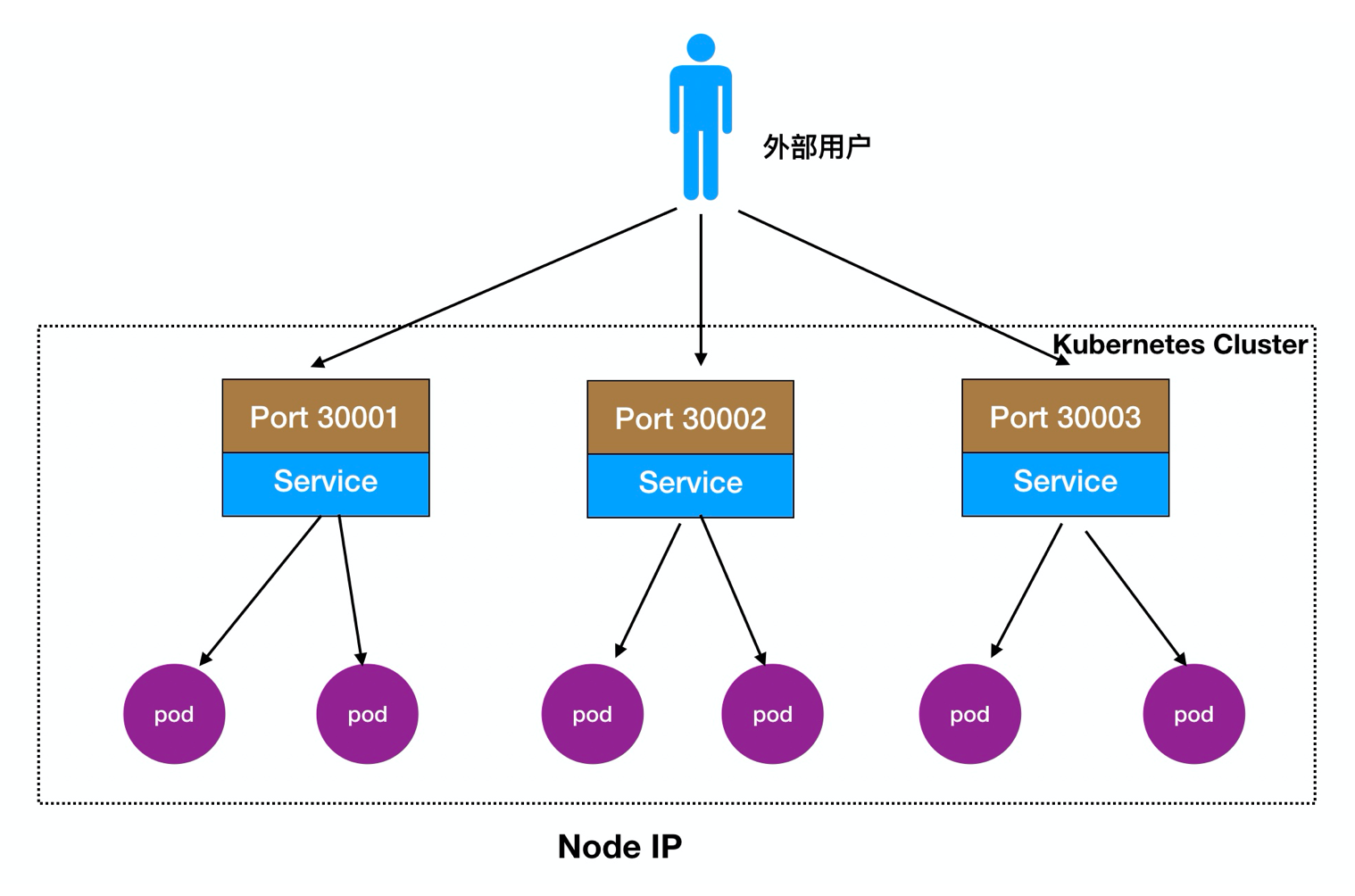
还可以直接在Node前面部署一个LB负载均衡,如图:
```yaml
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 30008
protocol: TCP
```
参数解释
```yaml
spec.ports.port:vip端口(cluster ip)
spec.ports.nodePort:映射到宿主机的端口,即提供外部访问的端口
spec.ports.targetPort:pod 端口
spec.selector: 标签选择器
```
>创建nodePort类型的时候也会分配一个Cluster IP,方便提供给Pod之间访问
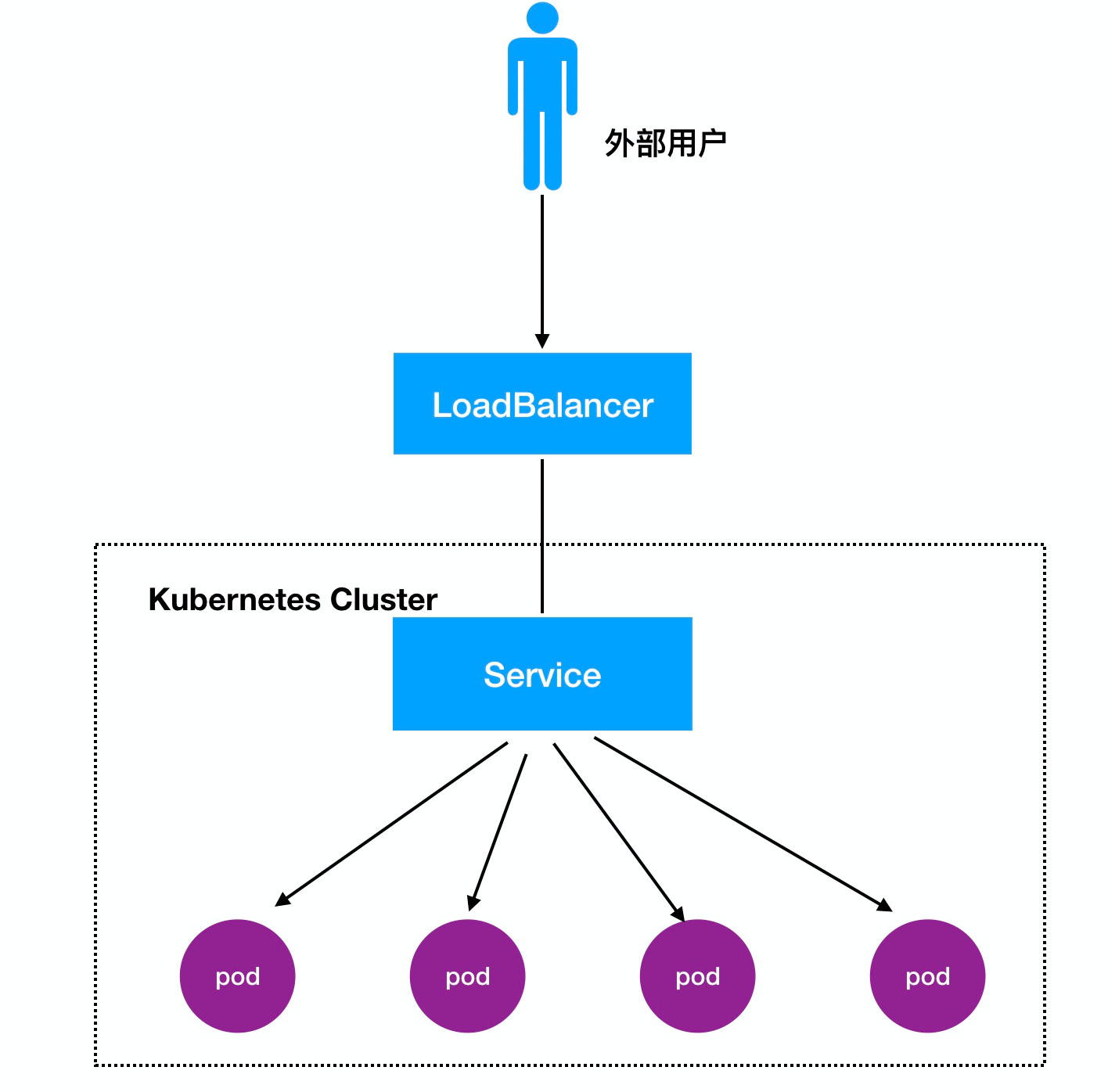
**3、LoadBalancer详解:**
访问流程:用户 -> 域名 -> 负载均衡器 -> NodeIP:Port ->PodIP:Port
**常规的docker映射场景:**
>访问 --> node IP:10.0.0.12 --> docker 容器: 172.16.48.2
如果当docker挂掉了后,在重新启动一个docker,容器IP地址就会发生变化,那么之前做的node和docker的映射就无效,就需要手动修改映射,这样就显得很麻烦
so,在k8s中新增了cluster IP,网段 10.254.0.0/16,series会自动创建这个cluster IP,也叫vip,当pod创建完成后会自动注册到service里,并且实现负载均衡(规则默认为rr),如果某个pod挂了后,会自动被剔除
>访问 --> node IP:10.0.0.13 --> cluster IP:10.254.0.0/16 (service) --> pod IP:172.16.48.2
**创建service**
```yaml
apiVersion: v1
kind: Service
metadata:
name: myweb
spec:
type: NodePort
ports:
- port: 80
nodePort: 30000
targetPort: 80
selector:
app: myweb
// 启动
kubectl create -f nginx-svc.yaml
```
查看Service是否正常接管pod网络服务:
```bash
[root@k8s-master01 svc]# kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 10.0.0.31:6443 2d
myweb 172.16.12.2:80,172.16.15.4:80 2m
```
#ipvs和iptables工作原理
service底层流量转发与负载均衡实现:
* iptables
* ipvs
1、一个service会创建很多的iptables规则(更新,非增量式)
2、iptables规则是从上到下逐条匹配(延时大)。
救世主:IPVS(内核态)
>LVS基于IPVS内核调度模块实现的负载均衡,如:阿里云SLB,基于LVS实现四层负载均衡。
**iptables:**
* 灵活,功能强大(可以在数据包不同阶段对包进行操作)
* 规则遍历匹配和更新,呈线性时延
**IPVS:**
* 工作在内核态,有更好的性能
* 调度算法丰富:rr,wrr,lc,wlc,ip hash ....

