这几天学习了Mybatis相关内容,在此整理一下这几天的笔记。
# 第一天
* mybatis入门
* mybatis的概述
* mybatis的环境搭建
* mybatis的入门案例
* 自定义mybatis框架
## 1 什么是框架
他是我们软件开发中的一套解决方案,不同的框架解决的是不同的问题。
使用框架的好处:框架封装了很多的细节,使开发者可以使用极简的方式实现功能。大大提高开发效率。
## 2 三层架构
表现层:用于展示数据的
业务层:处理业务需求
持久层:和数据库交互的
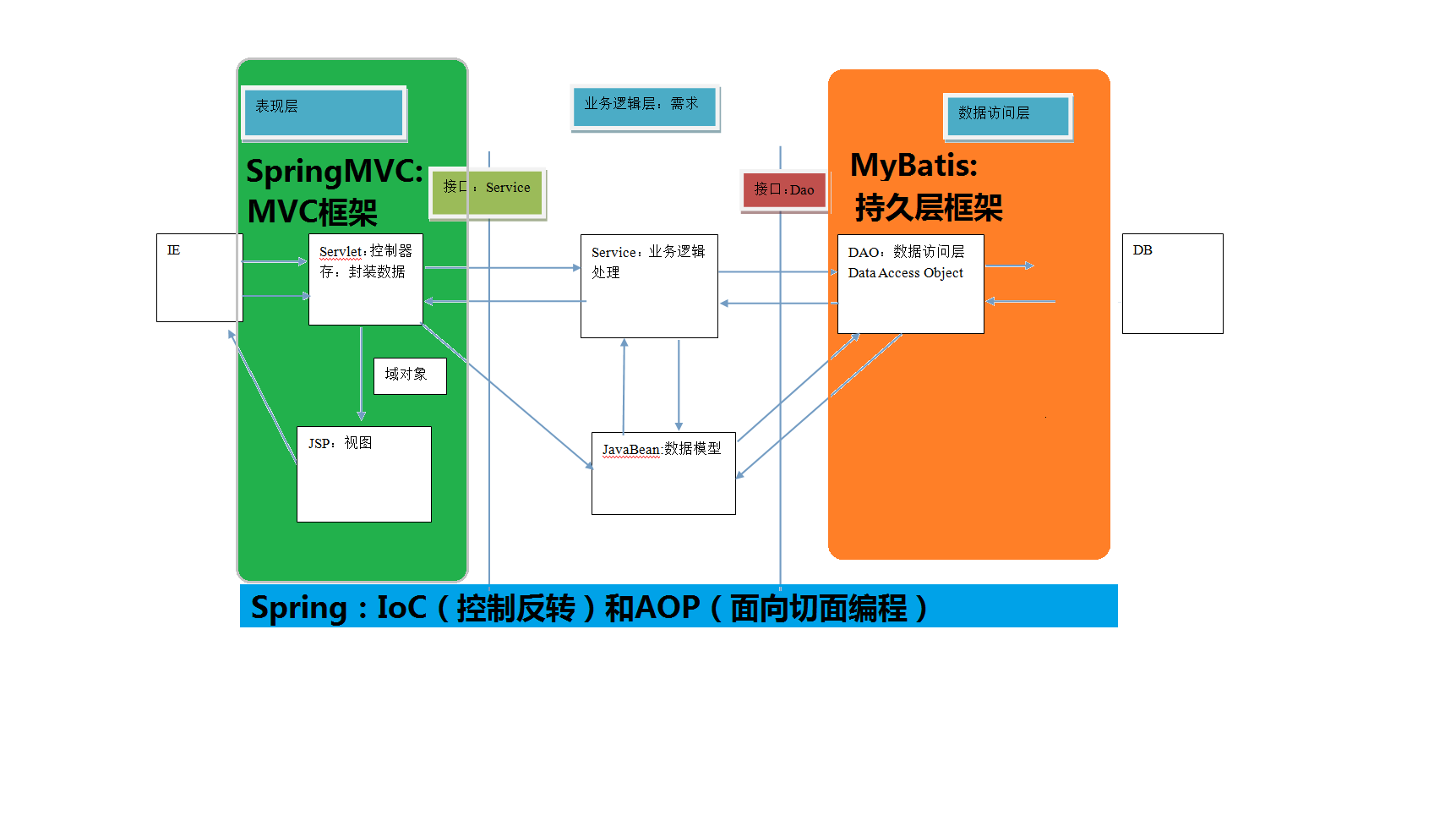
## 3 持久层技术解决方案
* jdbc技术:
* Connection
* PreparedStatement
* ResultSet
* Spring的JdbcTemplate:Spring中对Jdbc的简单封装
* Apache的DBUtils:它和Spring的JdbcTemplate很像,也是对jdbc的简单封装
以上这些都不是框架:
jdbc是规范
Spring的JdbcTemplate和Apache的DBUtils都只是工具类
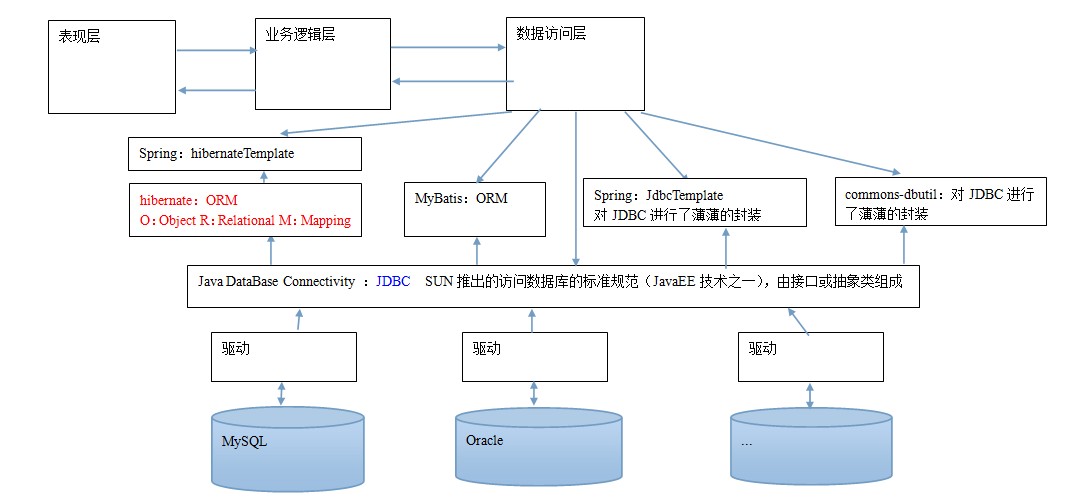
* jdbc问题分析
* 1、数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库链接池可解决此问题。
* 2、Sql 语句在代码中硬编码,造成代码不易维护,实际应用 sql 变化的可能较大,sql 变动需要改变 java 代码。
* 3、使用 preparedStatement 向占有位符号传参数存在硬编码,因为 sql 语句的 where 条件不一定,可能多也可能少,修改 sql 还要修改代码,系统不易维护。
* 4、对结果集解析存在硬编码(查询列名),sql 变化导致解析代码变化,系统不易维护,如果能将数据库记录封装成 pojo 对象解析比较方便。
## 4 mybatis框架概述
mybatis是一个优秀的基于 java 的持久层框架,它内部封装了 jdbc,使开发者只需要关注 sql语句本身,而不需要花费精力去处理加载驱动、创建连接、创建 statement 等繁杂的过程。
mybatis通过xml 或注解的方式将要执行的各种statement配置起来,并通过java对象和statement 中 sql 的动态参数进行映射生成最终执行的 sql 语句,最后由 mybatis 框架执行 sql 并将结果映射为 java 对象并返回。
采用 ORM 思想解决了实体和数据库映射的问题,对 jdbc进行了封装,屏蔽了 jdbc api 底层访问细节,使我们不用与 jdbc api 打交道,就可以完成对数据库的持久化操作。
* ORM:Object Relational Mapping 对象关系映射
> 简单地说:就是把数据库和实体类及实体类的属性对应起来,让我们可以通过操作实体类实现操作数据库表
## 5 mybatis入门
* mybatis的环境搭建
* 第一步:创建maven工程并导入坐标
* 第二步:创建实体类和dao接口
* 第三步:创建mybatis的主配置文件SqlMapConfig.xml
* 第四步:创建映射配置文件IUserDao.xml
* 搭建环境的注意事项
* 一:创建IUserDao.xml和IUserDao.java是名称是为了和之前的只是保持一致。在mybatis中它把持久层的操作接口名称和映射文件也叫做:Mapper,所以IUserDao和IUserMapper是一样的
* 二:在idea中创建目录的时候,它和包是不一样的。包在创建时:com.itheima.dao是三级结构;目录在创建时:com.itheima.dao是一级目录
* 三:mybatis的映射配置文件位置必须和dao接口的包结构相同
* 四:映射配置文件的mapper标签namespace属性的取值必须是dao接口的全限定类名
* 五:映射配置文件的操作配置(select),id属性的取值必须是dao接口的方法名
当我们遵从了三四五点之后,我们在开发中就无须在写dao的实现类。
* mybatis的入门案例
* 第一步:读取配置文件
* 第二步:创建SQLSessionFactory工厂
* 第三步:创建SQLSession
* 第四步:创建代理Dao接口的代理对象
* 第五步:执行dao中的方法
* 第六步:释放资源
> tips:不要忘记在映射配置文件中告知mybatis要封装到哪个实体类中,配置的方式:指定实体类的全限定类名

* mybatis基于注解的入门案例
把IUserDao.xml移除,在dao接口的方法上使用@select注解,并且指定SQL语句。同时需要在SqlMapConfig.xml中的mapper配置时,使用class属性指定dao接口的全限定类名。
> tips:我们在实际开发中都是越简便越好,所以不管使用XML还是注解配置都是采用不写dao实现类的方式。但是mybatis还是支持写dao实现类的。
## 6 自定义mybatis
分析:
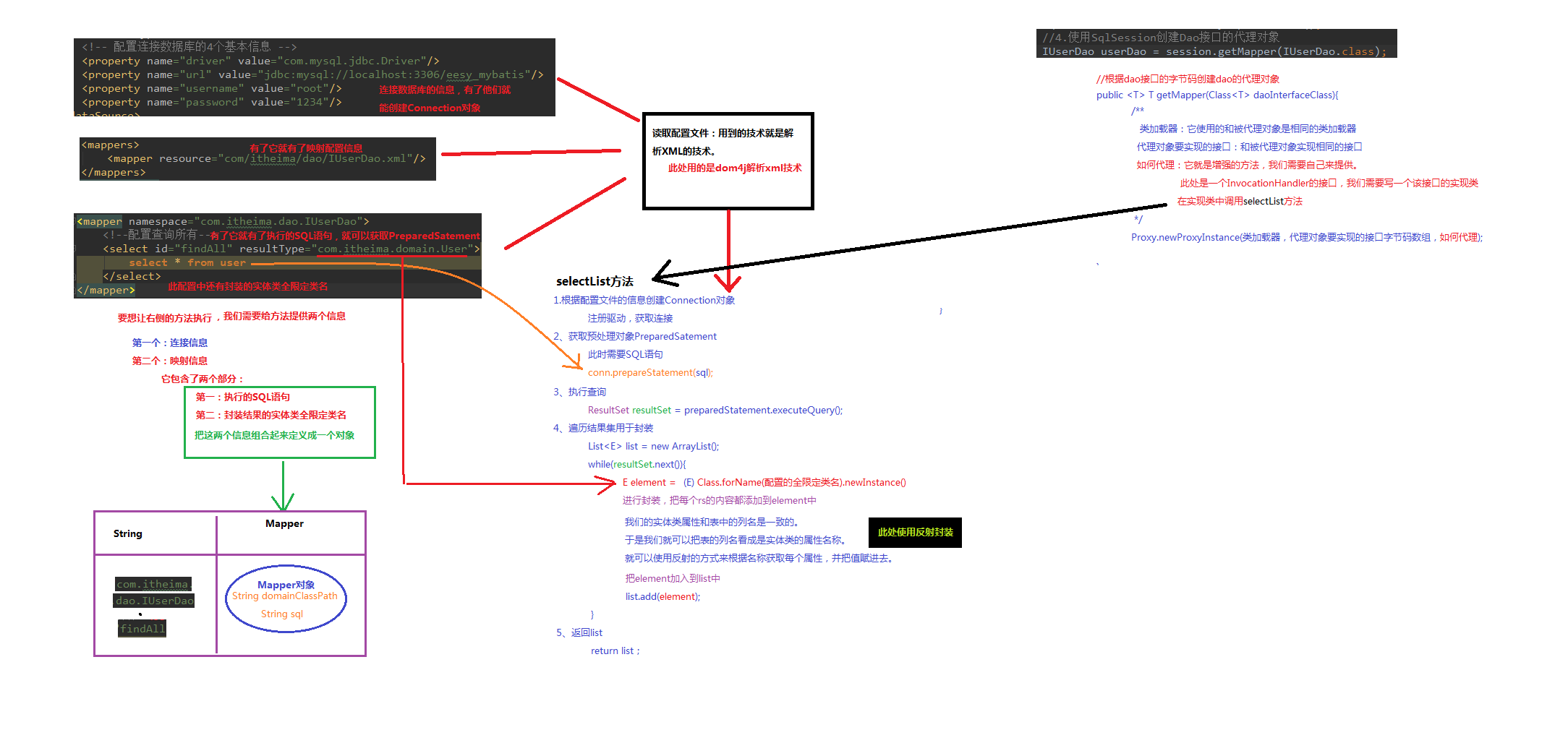
mybatis在使用代理dao的方式实现增删改查时做了什么?
1. 创建代理对象
2. 在代理对象中调用selectList
自定义mybatis通过入门案例看到类
class Resource
class SqlSqssionFactoryBuilder
Interface SqlSessionFactory
interface SqlSession
实现代码省略...
自定义mybatis开发流程图:

# 第二天
* mybatis基本使用
* mybatis的单表CRUD操作
* mybatis的参数和返回值
* mybatis的dao编写
* mybatis配置的细节
> 几个标签的使用
## 1 基于代理dao实现CRUD操作
> 使用要求:
>
1、持久层接口和持久层接口的映射配置必须在相同的包下
>
2、持久层映射配置中mapper标签的namespace属性取值必须是持久层接口的全限定类名
>
3、SQL语句的配置标签`
细节:
resultType 属性:
用于指定结果集的类型。
parameterType 属性:
用于指定传入参数的类型。
sql 语句中使用#{}字符:
它代表占位符,相当于原来 jdbc 部分所学的?,都是用于执行语句时替换实际的数据。
具体的数据是由#{}里面的内容决定的。
#{}中内容的写法:
由于数据类型是基本类型,所以此处可以随意写。
### 1.2 保存操作
在持久层接口中添加新增方法
/**
* 保存用户
* @param user
* @return 影响数据库记录的行数
*/
int saveUser(User user);
在用户的映射配置文件中配置
insert into user(username,birthday,sex,address)
values(#{username},#{birthday},#{sex},#{address})
细节:
patameterType属性:
代表参数的类型,因为我们要传入的是一个类的对象,所以类型就写类的全名称。
SQL语句中使用#{}字符:
它代表占位符,相当于原来jdbc部分所学的?,都是用于执行语句是替换实际的数据。具体的数据是由#{}里面的内容决定的。
#{}中内容的写法:
由于我们保存方法的参数是一个User对象,此处要写User对象中的属性名称,他用的是OGNL表达式。
OGNL表达式:
是Apache提供的一种表达式语言,全称是:Object Graphic Navigation Language 对象导航语言
它是按照一定的语法格式来获取数据的。语法格式就是使用 #{对象.对象}的方式。
#{user.username}它会先去找 user 对象,然后在 user 对象中找到 username 属性,并调用
getUsername()方法把值取出来。但是我们在 parameterType 属性上指定了实体类名称,所以可以省略 user,而直接写 username。
> tips:在实现增删改时一定要去控制事务的提交,那么在 mybatis 中如何控制事务提交呢?
可以使用 session.commit() 来实现事务提交。
新增用户ID的返回值
新增用户后,同时还要返回当前新增用户的 id 值,因为 id 是由数据库的自动增长来实现的,所以就相当于我们要在新增后将自动增长 auto_increment 的值返回。
insert into user(username,birthday,sex,address)
values(#{username},#{birthday},#{sex},#{address})
### 1.3 用户更新
在持久层接口中添加更新方法
/**
* 更新用户
* @param user
* @return 影响数据库记录的行数
*/
int updateUser(User user);
在用户的映射配置文件中配置
update user set username=#{username},birthday=#{birthday},sex=#{sex},address=#{address} where id=#{id}
### 1.4 用户删除
在持久层接口中添加删除方法
/**
* 根据id删除用户
* @param userId
* @return
*/
int deleteUser(Integer userId);
在用户的映射配置文件中配置
delete from user where id = #{uid}
### 1.5 用户模糊查询
在持久层接口中添加模糊查询方法
/**
* 根据名称模糊查询
* @param username
* @return
*/
List findByName(String username);
在用户的映射配置文件中配置
>
我们在配置文件中没有加入%来作为模糊查询的条件,所以在传入字符串实参时,就需要给定模糊查询的标识%。
配置文件中的#{username}也只是一个占位符,所以SQL语句会显示为“?”。
模糊查询的另一种配置方式
>
我们在上面将原来的#{}占位符改成了${value}。如果用模糊查询的这种写法,那么${value}的写法就是固定的,不能写成其他名字
#### 1.5.1 `#{}`和`${}`的区别
**#{}表示一个占位符号**
通过#{}可以实现preparedStatement向占位符中设置值,自动进行java类型和jdbc类型转换,#{}可以有效防止SQL注入。#{}可以接受简单类型值或pojo属性值。如果parameterType传输单个简单类型值,#{}扩号中可以是value或其他名称。
**${}表示拼接 sql 串**
通过`${}`可以将 parameterType 传入的内容拼接在 sql中且不进行 jdbc 类型转换, `${}`可以接收简单类型值或 pojo 属性值,如果 parameterType 传输单个简单类型值,`${}`括号中只能是 value。
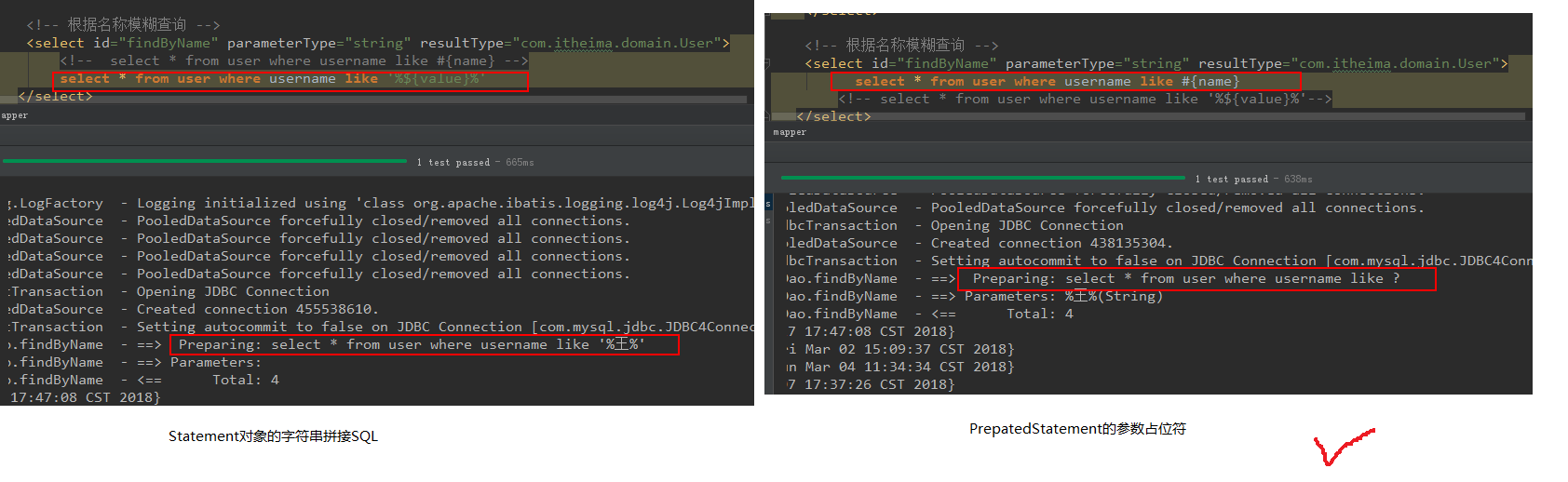
#### 1.5.2 模糊查询的${value}源码分析

这就说明了源码中指定了读取的key的名字就是“value”,所以我们在绑定参数时就只能叫value。
### 1.6 查询使用聚合函数
在持久层接口中添加聚合函数查询方法
/**
* 查询总记录条数
* @return
*/
int findTotal();
在用户的映射配置文件中配置
### 1.7 Mybatis与jdbc编程的比较
1、数据可连接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库连接池可解决此问题。
解决:在SqlMapConfig.xml中配置数据库连接池,使用连接池管理数据库连接。
2、SQL语句写在代码中造成代码不易维护,实际应用SQL变化的可能较大,SQL变动须要改变java代码。
解决:将SQL语句配置在xxxmapper.xml文件中与java代码分离
3、向SQL语句传参数麻烦,因为SQL语句的where条件不一定,可能多也可能少,占位符需要和参数对应。
解决:mybatis自动将java映射至SQL语句,通过statement中的parameterType定义输入参数的类型
4、对结果集解析麻烦,SQL变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便
解决:mybatis自动将SQL执行结果映射至java对象,通过statement中的resultType定义输出结果的类型
## 2 Mybatis的参数深入
### 2.1 parameterType 配置参数
**使用说明**
我们在上一章节中已经介绍了 SQL 语句传参,使用标签的 parameterType 属性来设定。该属性的取值可以是基本类型,引用类型(例如:String 类型),还可以是实体类类型(POJO 类)。同时也可以使用实体类的包装类,本章节将介绍如何使用实体类的包装类作为参数传递。
**注意事项**
基本类型和 String 我们可以直接写类型名称 ,也可以使用 包名.类名 的方式,例如 : `java.lang.String` 。实体类类型目前我们只能使用全限定类名,究其原因是因为 mybaits 在加载时已经把常用的数据类型注册了别名,从而我们在使用时可以不写包名,而我们的是实体类并没有注册别名,所以必须写全限定类名。接下来将讲解如何注册实体类的别名。
### 2.2 传递poji包装对象
开发中通过 pojo 传递查询条件 ,查询条件是综合的查询条件,不仅包括用户查询条件还包括其它的查询条件(比如将用户购买商品信息也作为查询条件),这时可以使用包装对象传递输入参数。Pojo 类中包含 pojo。
需求:根据用户名查询用户信息,查询条件放到 QueryVo 的 user 属性中。
编写QueryVo
public class QueryVo implements Serializable {
private User user;
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
}
编写持久层接口
public interface IUserDao {
/**
* 根据 QueryVo 中的条件查询用户
* @param vo
* @return
*/
List findByVo(QueryVo vo);
}
持久层接口的映射文件
## 3 Mybatis的输出结果封装
### 3.1 resultType配置结果类型
> resultType 属性可以指定结果集的类型,它支持基本类型和实体类类型。
需要注意的是,它和 parameterType 一样,如果注册过类型别名的,可以直接使用别名。没有注册过的必须使用全限定类名。
例如:我们的实体类此时必须是全限定类名。同时,当是实体类名称是,还要求实体类中的属性名称必须和查询语句中的列名保持一致,否则无法实现封装。
### 3.2 resultMap结果类型
> resultMap 标签可以建立查询的列名和实体类的属性名称不一致时建立对应关系,从而实现封装。
在 select 标签中使用 resultMap 属性指定引用即可。同时 resultMap 可以实现将查询结果映射为复杂类
型的 pojo,比如在查询结果映射对象中包括 pojo 和 list 实现一对一查询和一对多查询。
#### 3.2.1 定义resultMap
id 标签:用于指定主键字段
result 标签:用于指定非主键字段
column 属性:用于指定数据库列名
property 属性:用于指定实体类属性名称
#### 3.2.2 映射配置
## 4 SqlMapConfig.xml配置文件
### 4.1 配置内容
SqlMapConfig.xml 中配置的内容和顺序
-properties(属性)
--property
-settings(全局配置参数)
--setting
-typeAliases(类型别名)
--typeAliase
--package
-typeHandlers(类型处理器)
-objectFactory(对象工厂)
-plugins(插件)
-environments(环境集合属性对象)
--environment(环境子属性对象)
---transactionManager(事务管理)
---dataSource(数据源)
-mappers(映射器)
--mapper
--package
### 4.2 properties(属性)
在使用 properties 标签配置时,我们可以采用两种方式指定属性配置
**第一种**
**第二种**
在 classpath 下定义 db.properties 文件
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/eesy
jdbc.username=root
jdbc.password=root
properties 标签配置
### 4.3 typeAliases(类型别名)
在前面我们讲的 Mybatis 支持的默认别名,我们也可以采用自定义别名方式来开发。
自定义别名:
### 4.3 mappers(映射器)
`< mapper resource=" " />`
> 使用相对于类路径的资源
>
如:< mapper resource=“com/itheimahttps://img.qb5200.com/download-x/dao/IUserDao.xml” />
` < mapper class=" " />`
> 使用 mapper 接口类路径
>
如:< mapper class=“com.itheima.dao.UserDao”/>
>
注意:此种方法要求 mapper 接口名称和 mapper 映射文件名称相同,且放在同一个目录中。
` < package name=""/>`
> 注册指定包下的所有 mapper 接口
>
如:< package name=“cn.itcast.mybatis.mapper”/>
>
注意:此种方法要求 mapper 接口名称和 mapper 映射文件名称相同,且放在同一个目录中。
## 编写dao实现类Mybatis的执行过程

## 代理dao的执行过程

# 第三天
* mybatis的深入和多表
* mybatis的连接池
* mybatis的事务控制及设计的方法
* mybatis的多表查询
> 一对多(多对一)
> 多对多
## 1 Mybatis连接池与事务深入
### 1.1 Mybatis的连接池技术
Mybatis 中的连接池技术,它采用的是自己的连接池技术。在 Mybatis 的 SqlMapConfig.xml 配置文件中,通过< dataSource type=”pooled”>来实现 Mybatis 中连接池的配置。
#### 1.1.1 Mybatis连接池的分类
Mybatis 将它自己的数据源分为三类:
|
-|-
UNPOOLED |不使用连接池的数据源
POOLED | 使用连接池的数据源
JNDI | 使用 JNDI 实现的数据源
具体结构如下:

相应地,MyBatis 内部分别定义了实现了 java.sql.DataSource 接口的 UnpooledDataSource,PooledDataSource 类来表示 UNPOOLED、POOLED 类型的数据源。
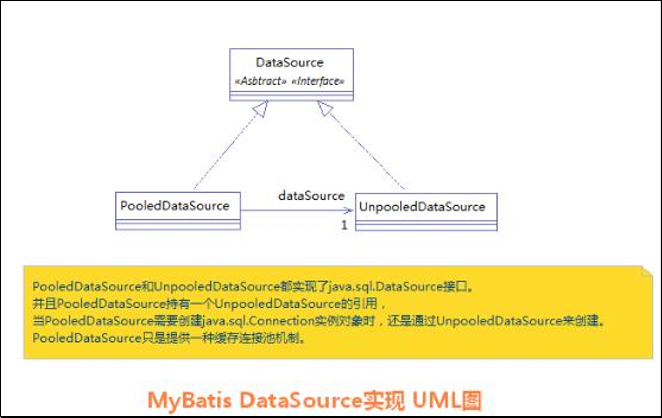
在这三种数据源中,我们一般采用的是 POOLED 数据源(很多时候我们所说的数据源就是为了更好的管理数据库连接,也就是我们所说的连接池技术)。
#### 1.1.2 Mybatis中数据源的配置
我们的数据源配置就是在 SqlMapConfig.xml 文件中,具体配置如下:
MyBatis 在初始化时,根据的 type 属性来创建相应类型的的数据源 DataSource,即:
* type=”POOLED”:MyBatis 会创建 PooledDataSource 实例
* type=”UNPOOLED” : MyBatis 会创建 UnpooledDataSource 实例
* type=”JNDI”:MyBatis 会从 JNDI 服务上查找 DataSource 实例,然后返回使用
#### 1.1.3 Mybatis中DataSource的存取
MyBatis 是通过工厂模式来创建数据源 DataSource 对象的, MyBatis 定义了抽象的工厂口:org.apache.ibatis.datasource.DataSourceFactory,通过其 getDataSource()方法返回数据源DataSource。
下面是 **DataSourceFactory** 源码,具体如下:
package org.apache.ibatis.datasource;
import java.util.Properties;
import javax.sql.DataSource;
/**
@author Clinton Begin
*/
public interface DataSourceFactory {
void setProperties(Properties props);
DataSource getDataSource();
}
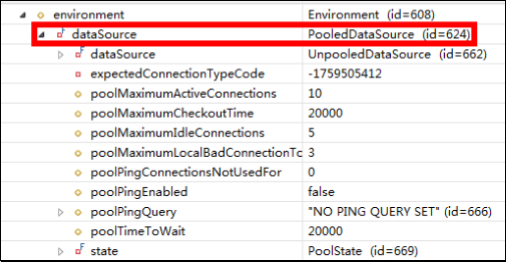
MyBatis 创建了 DataSource 实例后,会将其放到 Configuration 对象内的 Environment 对象中, 供以后使用。
具体分析过程如下:
1.先进入 XMLConfigBuilder 类中,可以找到如下代码:
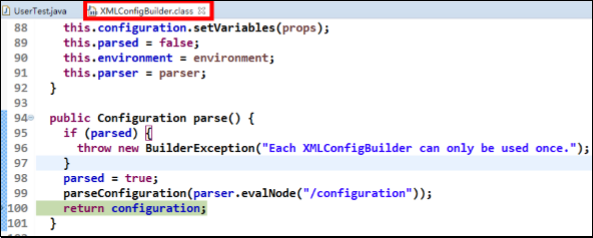
2.分析 configuration 对象的 environment 属性,结果如下:
#### 1.1.4 Mybatis中连接的获取过程分析
当我们需要创建 SqlSession 对象并需要执行 SQL 语句时,这时候 MyBatis 才会去调用 dataSource 对象来创建java.sql.Connection对象。也就是说,java.sql.Connection对象的创建一直延迟到执行SQL语句的时候。
@Test
public void testSql() throws Exception {
InputStream in = Resources.getResourceAsStream("SqlMapConfig.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(in);
SqlSession sqlSession = factory.openSession();
List list = sqlSession.selectList("findUserById",41); System.out.println(list.size());
}
只有当第 4句sqlSession.selectList("findUserById"),才会触发MyBatis 在底层执行下面这个方法来创建 java.sql.Connection 对象。
如何证明它的加载过程呢?
我们可以通过断点调试,在 PooledDataSource 中找到如下 popConnection()方法,如下所示:
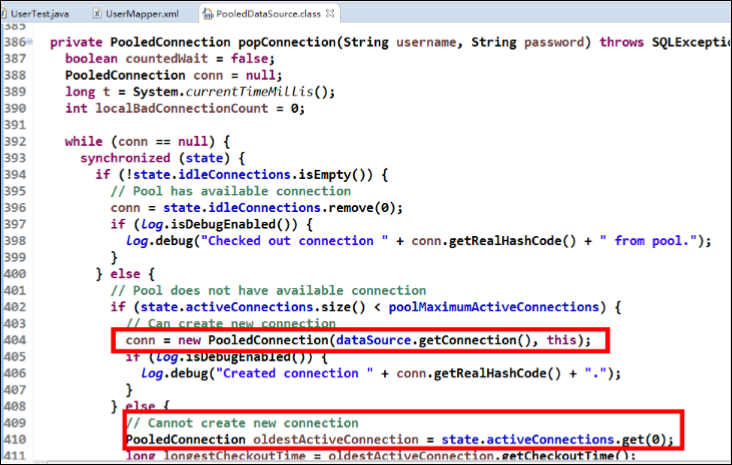
分析源代码,得出 PooledDataSource 工作原理如下:
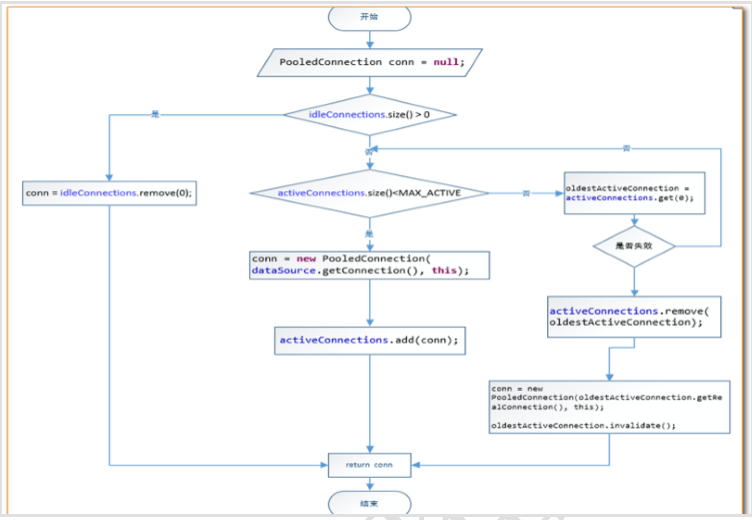
下面是连接获取的源代码:

最后我们可以发现,真正连接打开的时间点,只是在我们执行SQL语句时,才会进行。其实这样做我们也可以进一步发现,数据库连接是我们最为宝贵的资源,只有在要用到的时候,才去获取并打开连接,当我们用完了就再立即将数据库连接归还到连接池中。
### 1.2 Mybatis的事务控制
#### 1.2.1 JDBC中事务的回顾
在 JDBC 中我们可以通过手动方式将事务的提交改为手动方式,通过 setAutoCommit()方法就可以调整。
Mybatis 框架因为是对 JDBC 的封装,所以 Mybatis 框架的事务控制方式,本身也是用 JDBC 的setAutoCommit()方法来设置事务提交方式的。
#### 1.2.2 Mybatis中事务提交方式
Mybatis 中事务的提交方式,本质上就是调用 JDBC 的 setAutoCommit()来实现事务控制。
运行下面测试代码:
@Test
public void testSaveUser() throws Exception {
User user = new User();
user.setUsername("mybatis user09");
//6.执行操作
int res = userDao.saveUser(user);
System.out.println(res);
System.out.println(user.getId());
}
@Before//在测试方法执行之前执行
public void init()throws Exception {
//1.读取配置文件
in = Resources.getResourceAsStream("SqlMapConfig.xml");
//2.创建构建者对象
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
//3.创建 SqlSession 工厂对象
factory = builder.build(in);
//4.创建 SqlSession 对象
session = factory.openSession();
//5.创建 Dao 的代理对象
userDao = session.getMapper(IUserDao.class);
}
@After//在测试方法执行完成之后执行
public void destroy() throws Exception{
//7.提交事务
session.commit();
//8.释放资源
session.close();
in.close();
}
观察控制台输出的结果:

这是我们的 Connection 的整个变化过程,通过分析我们能够发现之前的 CUD 操作过程中,我们都要手动进行事务的提交,原因是 setAutoCommit()方法,在执行时它的值被设置为 false 了,所以我们在 CUD 操作中,必须通过 sqlSession.commit()方法来执行提交操作。
#### 1.2.3 Mybatis自动提交事务的设置
通过上面的研究和分析,为什么 CUD 过程中必须使用 sqlSession.commit()提交事务?主要原因就是在连接池中取出的连接,都会将调用 connection.setAutoCommit(false)方法,这样我们就必须使用 sqlSession.commit()方法,相当于使用了 JDBC 中的 connection.commit()方法实现事务提交。
明白这一点后,我们现在一起尝试不进行手动提交,一样实现 CUD 操作。
//4.创建 SqlSession 对象
session = factory.openSession(true);
此时事务就设置为自动提交了,同样可以实现CUD操作时记录的保存。虽然这也是一种方式,但就编程而言,设置为自动提交方式为 false 再根据情况决定是否进行提交,这种方式更常用。因为我们可以根据业务情况来决定提交是否进行提交。
## 2 Mybatis的动态SQL语句
Mybatis 的映射文件中,前面我们的 SQL 都是比较简单的,有些时候业务逻辑复杂时,我们的 SQL 是动态变化的,此时在前面的学习中我们的 SQL 就不能满足要求了。
参考的官方文档描述如下:

### 2.1 动态 SQL 之``标签
我们根据实体类的不同取值,使用不同的 SQL 语句来进行查询。比如在 id 如果不为空时可以根据 id 查询,如果 username 也不为空时还要加入用户名作为条件。这种情况在我们的多条件组合查询中经常会碰到。
#### 2.1.1 持久层 Dao 接口
/**
* 根据用户信息,查询用户列表
* @param user
* @return
*/
List findByUser(User user);
#### 2.1.2 持久层 Dao 映射配置
>
注意:标签的 test 属性中写的是对象的属性名,如果是包装类的对象要使用 OGNL 表达式的写法。
另外要注意 where 1=1 的作用~!
### 2.2 动态 SQL 之``标签
为了简化上面 where 1=1 的条件拼装,我们可以采用标签来简化开发。
#### 2.2.1 持久层 Dao 映射配置
### 2.3 动态标签之``标签
#### 2.3.1 需求
传入多个 id 查询用户信息,用下边两个 sql 实现:
`SELECT * FROM USERS WHERE username LIKE '%张%' AND (id =10 OR id =89 OR id=16) `
`SELECT * FROM USERS WHERE username LIKE '%张%' AND id IN (10,89,16) `
这样我们在进行范围查询时,就要将一个集合中的值,作为参数动态添加进来。 这样我们将如何进行参数的传递?
##### 2.3.1.1 在 QueryVo 中加入一个 List 集合用于封装参数
public class QueryVo implements Serializable {
private List ids;
public List getIds() {
return ids;
}
public void setIds(List ids) {
this.ids = ids;
}
}
#### 2.3.2 持久层 Dao 接口
/**
* 根据 id 集合查询用户
* @param vo
* @return
*/
List findInIds(QueryVo vo);
#### 2.3.3 持久层 Dao 映射配置
SQL 语句:
`select 字段 from user where id in (?)`
标签用于遍历集合,它的属性:
* collection:代表要遍历的集合元素,注意编写时不要写#{}
* open:代表语句的开始部分
* close:代表结束部分
* item:代表遍历集合的每个元素,生成的变量名
* sperator:代表分隔符
### 2.4 Mybatis 中简化编写的 SQL 片段
Sql 中可将重复的 sql 提取出来,使用时用 include 引用即可,最终达到 sql 重用的目的。
#### 2.4.1 定义代码片段
select * from user
#### 2.4.2 引用代码片段
## 3 Mybatis 多表查询之一对多
本次案例主要以最为简单的用户和账户的模型来分析Mybatis多表关系。用户为User 表,账户为Account 表。一个用户(User)可以有多个账户(Account)。具体关系如下:
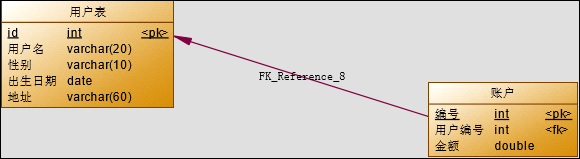
### 3.1 一对一查询(多对一)
需求
查询所有账户信息,关联查询下单用户信息。
注意:
因为一个账户信息只能供某个用户使用,所以从查询账户信息出发关联查询用户信息为一对一查询。如果从用户信息出发查询用户下的账户信息则为一对多查询,因为一个用户可以有多个账户。
#### 3.1.1 方式一
##### 3.1.1.1 定义账户信息的实体类
public class Account implements Serializable {
private Integer id;
private Integer uid;
private Double money;
...//省略getter/setter/tostring
}
##### 3.1.1.2 编写 Sql 语句
实现查询账户信息时,也要查询账户所对应的用户信息。
SELECT
account.*,
user.username,
user.address
FROM
account,
user
WHERE account.uid = user.id
##### 3.1.1.3 定义 AccountUser 类
为了能够封装上面SQL语句查询结果,定义了AccountCustomer类中要包含账户信息同时还要包含用户信息,所以我们要在定义AccountUser类是可以继承User类。
public class AccountUser extends Account implements Serializable {
private String username;
private String address;
...getter/setter
@Override
public String toString() {
return super.toString() + " AccountUser [username=" + username + ",
address=" + address + "]";
}
}
##### 3.1.1.4 定义账户的持久层 Dao 接口
public interface IAccountDao {
/**
* 查询所有账户,同时获取账户的所属用户名称以及它的地址信息
* @return
*/
List findAll();
}
##### 3.1.1.5 定义 AccountDao.xml 文件中的查询配置信息
>
注意:因为上面查询的结果中包含了账户信息同时还包含了用户信息,所以我们的返回值类型 returnType的值设置为 AccountUser 类型,这样就可以接收账户信息和用户信息了。
小结:定义专门的 pojo 类作为输出类型,其中定义了 sql 查询结果集所有的字段。此方法较为简单,企业中使用普遍。
#### 3.1.2 方式二
使用 resultMap,定义专门的 resultMap 用于映射一对一查询结果。通过面向对象的(has a)关系可以得知,我们可以在 Account 类中加入一个 User 类的对象来代表这个账户是哪个用户的。
##### 3.1.2.1 修改 Account 类
在 Account 类中加入 User 类的对象作为 Account 类的一个属性。
public class Account implements Serializable {
private Integer id;
private Integer uid;
private Double money;
private User user;
...getter/setter/tostring
}
##### 3.1.2.2 修改 AccountDao 接口中的方法
public interface IAccountDao {
/**
* 查询所有账户,同时获取账户的所属用户名称以及它的地址信息
* @return
*/
List findAll();
}
>
注意:第二种方式,将返回值改 为了 Account 类型。
因为 Account 类中包含了一个 User 类的对象,它可以封装账户所对应的用户信息。
##### 3.1.2.3 重新定义 AccountDao.xml 文件
### 3.2 一对多查询
需求:
查询所有用户信息及用户关联的账户信息。
分析:
用户信息和他的账户信息为一对多关系,并且查询过程中如果用户没有账户信息,此时也要将用户信息查询出来,我们想到了左外连接查询比较合适。
#### 3.2.1 编写 SQL 语句
SELECT
u.*, acc.id id,
acc.uid,
acc.money
FROM
user u
LEFT JOIN account acc ON u.id = acc.uid
#### 3.2.2 User 类加入 List< Account >
public class User implements Serializable {
private Integer id;
private String username;
private Date birthday;
private String sex;
private String address;
private List accounts;
//...getter/setter/tostring
}
#### 3.2.4 用户持久层 Dao 映射文件配置
collection:
部分定义了用户关联的账户信息。表示关联查询结果集
property="accList":
关联查询的结果集存储在 User 对象的上哪个属性。
ofType="account":
指定关联查询的结果集中的对象类型即List中的对象类型。此处可以使用别名,也可以使用全限定名。
## 4 Mybatis 多表查询之多对多
### 4.1 实现 Role 到 User 多对多
多对多关系其实我们看成是双向的一对多关系。
#### 4.1.1 用户与角色的关系模型

#### 4.1.2 业务要求及实现 SQL
需求:
实现查询所有对象并且加载它所分配的用户信息。
分析:
查询角色我们需要用到Role表,但角色分配的用户的信息我们并不能直接找到用户信息,而是要通过中间表(USER_ROLE 表)才能关联到用户信息。
下面是实现的 SQL 语句:
SELECT
r.*,u.id uid,
u.username username,
u.birthday birthday,
u.sex sex,
u.address address
FROM
ROLE r
INNER JOIN
USER_ROLE ur
ON ( r.id = ur.rid)
INNER JOIN
USER u
ON (ur.uid = u.id);
#### 4.1.3 编写Role实体类
public class Role implements Serializable {
private Integer roleId;
private String roleName;
private String roleDesc;
//多对多的关系映射:一个角色可以赋予多个用户
private List users;
//...getter/setter/tostring
}
#### 4.1.4 编写 Role 持久层接口
public interface IRoleDao {
/**
* 查询所有角色
* @return
*/
List findAll();
}
#### 4.1.5 编写映射文件
### 4.2 实现 User 到 Role 的多对多
从 User 出发,我们也可以发现一个用户可以具有多个角色,这样用户到角色的关系也还是一对多关系。这样我们就可以认为 User 与 Role 的多对多关系,可以被拆解成两个一对多关系来实现。
User到Role的多对多和Role到User的多对多实现差别不大。
在User中添加 List的属性,修改映射文件内容以及sql语句即可。
select u.*,r.id as rid,r.role_name,r.role_desc from user u
left outer join user_role ur on u.id = ur.uid
left outer join role r on r.id = ur.rid
# 第四天
* mybatis中的延迟加载
* mybatis的缓存
* mybatis中的一级缓存和二级缓存
* mybatis的注解开发
## 1 Mybatis中的延迟加载
### 1.1 何为延迟加载?
延迟加载:
> 就是在需要用到数据时才进行加载,不需要用到数据时就不加载数据。延迟加载也称懒加载。
好处:
先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表要比关联查询多张表速度要快。
坏处:
因为只有当需要用到数据时,才会进行数据库查询,这样在大批量数据查询时,因为查询工作也要消耗时间,所以可能造成用户等待时间变长,造成用户体验下降。
### 1.2 实现需求
查询账户(Account)信息并且关联查询用户(User)信息。如果先查询账户(Account)信息即可满足要求,当我们需要查询用户(User)信息时再查询用户(User)信息。把对用户(User)信息的按需去查询就是延迟加载。
mybatis第三天实现多表操作时,我们使用了resultMap来实现一对一,一对多,多对多关系的操作。主要是通过 association、collection 实现一对一及一对多映射。association、collection 具备延迟加载功能。
### 1.3 使用 assocation 实现一对一的延迟加载
IAccountDao.xml
<?xml version="1.0" encoding="UTF-8"?>
SqlMapConfig.xml
<?xml version="1.0" encoding="UTF-8"?>
### 1.4 使用Collection实现一对多的延迟加载
IUserDao.xml
* 标签:
* 主要用来加载关联的集合对象
* select属性:
* 用来指定查询account列表的sql语句,所以填写的是该sql映射的id
* column属性:
* 用于指定select属性的sql语句的参数来源,上面的参数来自于user的id列,所以就写成id这一个字段名了
IAccountDao.xml
## 2 Mybatis的缓存
什么是缓存
> 存在于内存中的临时数据。
为什么使用缓存
>减少和数据库的交互次数,提高执行效率。
什么样的数据能使用缓存,什么样的数据不能使用
适用于缓存:
* 经常查询并且不经常改变的。
* 数据的正确与否对最终结果影响不大的。
不适用于缓存:
* 经常改变的数据
* 数据的正确与否对最终结果影响很大的。
* 例如:商品的库存,银行的汇率,股市的牌价。
Mybatis中的缓存分为一级缓存、二级缓存

### 2.1 Mybatis的一级缓存
它指的是Mybatis中SqlSession对象的缓存。
当我们执行查询之后,查询的结果会同时存入到SqlSession为我们提供一块区域中。
该区域的结构是一个Map。当我们再次查询同样的数据,Mybatis会先去SqlSession中查询是否有,有的话直接拿出来用。
当SqlSession对象消失时,Mybatis的一级缓存也就消失了。
分析:
一级缓存是 SqlSession 范围的缓存,当调用 SqlSession 的修改,添加,删除,commit(),close()等方法时,就会清空一级缓存。
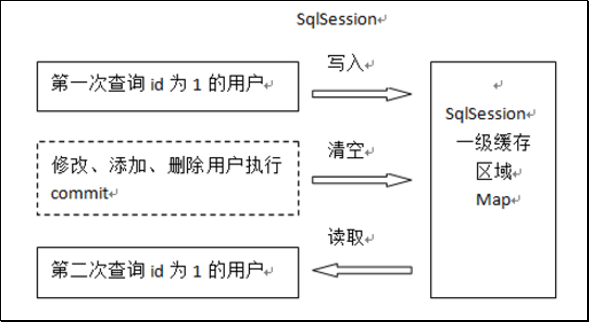
第一次发起查询用户 id 为 1 的用户信息,先去找缓存中是否有 id 为 1 的用户信息,如果没有,从数据库查询用户信息。
得到用户信息,将用户信息存储到一级缓存中。
如果 sqlSession 去执行 commit 操作(执行插入、更新、删除),清空 SqlSession 中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
第二次发起查询用户 id 为 1 的用户信息,先去找缓存中是否有 id 为 1 的用户信息,缓存中有,直接从缓存中获取用户信息。
### 2.2 Mybatis的二级缓存
二级缓存:
它指的是Mybatis中SqlSessionFactory对象的缓存。
由同一个SqlSessionFactory对象创建的SqlSession共享其缓存。
#### 2.2.1 二级缓存结构图

首先开启 mybatis 的二级缓存。
sqlSession1 去查询用户信息,查询到用户信息会将查询数据存储到二级缓存中。
如果 SqlSession3 去执行相同 mapper 映射下 sql,执行 commit 提交,将会清空该 mapper 映射下的二级缓存区域的数据。
sqlSession2 去查询与 sqlSession1 相同的用户信息,首先会去缓存中找是否存在数据,如果存在直接从缓存中取出数据。
#### 2.2.2 二级缓存的使用
二级缓存的使用步骤:
第一步:让Mybatis框架支持二级缓存(在SqlMapConfig.xml中配置)
第二步:让当前的映射文件支持二级缓存(在IUserDao.xml中配置/通过注解配置)
第三步:让当前的操作支持二级缓存(在select标签中配置)
##### 2.2.2.1 第一步:在 SqlMapConfig.xml 文件开启二级缓存
因为cacheEnabled的取值默认就为true,所以这一步可以省略不配置,为true代表开启二级缓存;为false代表不开启二级缓存。
##### 2.2.2.2 第二步:配置相关的 Mapper 映射文件
标签表示当前这个mapper映射将使用二级映射,区分的标准就看mapper的namespace值
<?xml version="1.0" encoding="UTF-8"?>
##### 2.2.2.3 第三步:配置 statement 上面的 useCache 属性
将UserDao.xml映射文件中的`
