上节回顾[深度学习与人类语言处理-语音识别(part2)](https://www.cnblogs.com/gongyanzh/p/12515971.html),这节课我们接着看seq2seq模型怎么做语音识别
---

上节课我们知道LAS做语音识别需要看完一个完整的序列才能输出,把我们希望语音识别模型可以在听到声音的时候就进行输出,一个直观的想法就是用单向的RNN,我们来看看CTC是怎么做的
### CTC
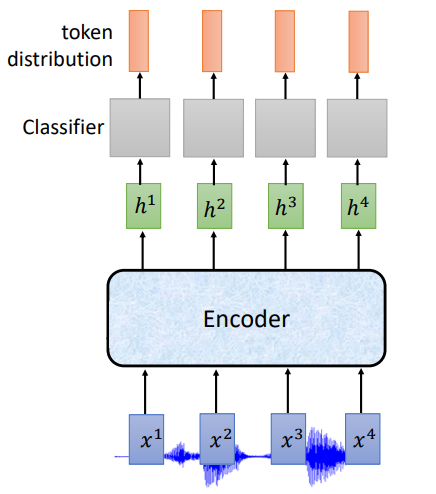
根据上面说的,在线语音识别,模型在听到声音的时候就需要输出,我们看下使用RNN的基本架构
```
input: 长度为T的声学特征
Encoder:单向RNN
ouput:长度为T的token,每一个输出位置对应词典中每个词的概率
```
但是对每一个输入的声学特征不总是会有对应的输出token,每一声学特征所包含的信息是非常少的,所以CTC在输出的词汇表中加入了一个标记$\phi$,表示什么也没有,词典大小变为V+1
```
ouput:长度为T的token,其中包括

