---
# 磕叨
在公司做项目是见到前辈们写的一段任务链的代码,大概如下
```
Runnable task = new TaskA(new TaskB(new TaskC(new taskD())));
task.run();
```
taskA执行run调用并完成TaskA声明的任务逻辑之后,内部会自动调用构造参数传入的TaskB的run方法,过程类似TaskA,TaskB完成之后一样会调用参数传入的task,直到最后一个没有带下一个task类传入的任务完成,即完成一个管道式调用。
爱思考的我在想,可用,不好用重用,于是动手改改。
---
# 准备
经过一段时间开发后,有了一个常用的工具类,方便快速开发,但是这里用到的东西很少,还是要说明一下,这里用到一个我称作ecommon的包,当然我只用了两个很基础的额部分。这两个部分完全可以用你自己的实现,是非常简单的。
- 函数接口
jdk8之后很方便让我们写出lambda,但是我觉得理解起来不直观,于是自己重写了 12 个接口,按参数个数和返回类型可以直接根据函数名直接选出你要的。具体在 https://github.com/kimffy24/EJoker/treehttps://img.qb5200.com/download-x/dev/ejoker-common/src/main/java/pro/jiefzz/ejoker/common/system/functional , IVoid打头的就是无返回的,后面的数字就是要带多少个参数,参数和返回类型全部都是泛型。1-6个参数已经能包括大部分情况了,需要更多参数的情况完全可以自定义一个上下文传递过去。
- 字符串填充类
类似`String.format`,但是我不用正则,而是类似slf4j那种,`log.info("This is a template, keyA={}, keyB={}", "valueA", "valueB")` , 类似这种占位填充。我的实现在 https://github.com/kimffy24/EJoker/blobhttps://img.qb5200.com/download-x/dev/ejoker-common/src/main/java/pro/jiefzz/ejoker/common/system/helper/StringHelper.java 的fill方法中。你也可以用 `String.format` 代替。
# 思路简述
我们先明确,jdk8以下的情况不作考虑。
pipeline我更多的印象是来自终端上的应用

pipeline是单向的,上个task的输出作为下个task的输入,直到没有下一个task,最后一个task的作用就应该是你期望的。且`后续任务只关心前者的输出结果,对于的他是谁,怎么做的,是不关心的`。记为 `Point1`
这个特点是我视为管道与切面或职责链模式的区别所在。
首先,我们得有第一推动,让管道流能有个开始,再就是有中间task,他必定是能接收到上一个任务的输出的,并且,可能有自带参数,并且有自己的输出,最后,有latest的task 与中间task区别在于他不用返回了,latest一般是以副作用的形式实现我们的企图的,如上图的 `wc -l` 作为最后一个任务是直接把结果打印到屏幕上,而不是返回一个变量给我们读取。根据java的强类型属性,以及刚刚一段的分析,可以得知,有3种类型的任务,开始任务,中间任务,最后任务,并且中间任务的个数是不限的,所有任务至于相邻的任务有一个管理点,那就是 ` 前者的输出类型与后者的输入类型一致 ` (网文中大部分说自己实现的pipeline的模式都是传递Object类型,到各个子任务中自己强转到需要的类型的,不说好与不好,但我肯定不喜欢)。这个特性记为 `Point2`。
而且,每个子任务,本身是可以带参数的,这是一个需要支持的点。像上图命令中的管道,每个子命令(除第一个)都是同时接受前一个命令的输出作为输入,且自带参数的。但是java在这里其实并不灵活,因此我们约定 `后续任务的第一个参数就是前一个任务的输入` , 这个约定是直接影响到我们的代码实现的。这个特性记为 `Point3`。
另外,管道的入口唯一的,一定是从开始任务往后流的。如果入口不一样,那么就是像个不同的管道,他们的意图以及输入输出的期望都是不同的。这个特性记为 `Point4`。
最后,在java中使用,我肯定不能像终端那种,错了重敲命令就是了,所以需要异常控制以及做一些相邻任务承上启下的时刻做点什么,例如日子打印,断言等。这个算附加题。
# 提起键盘撸
(因为我已经写完并测试完了,所以我就反过来解析我是怎么想的了)
这里以Runnable接口作为基础接口。给出其中一个测试的例子
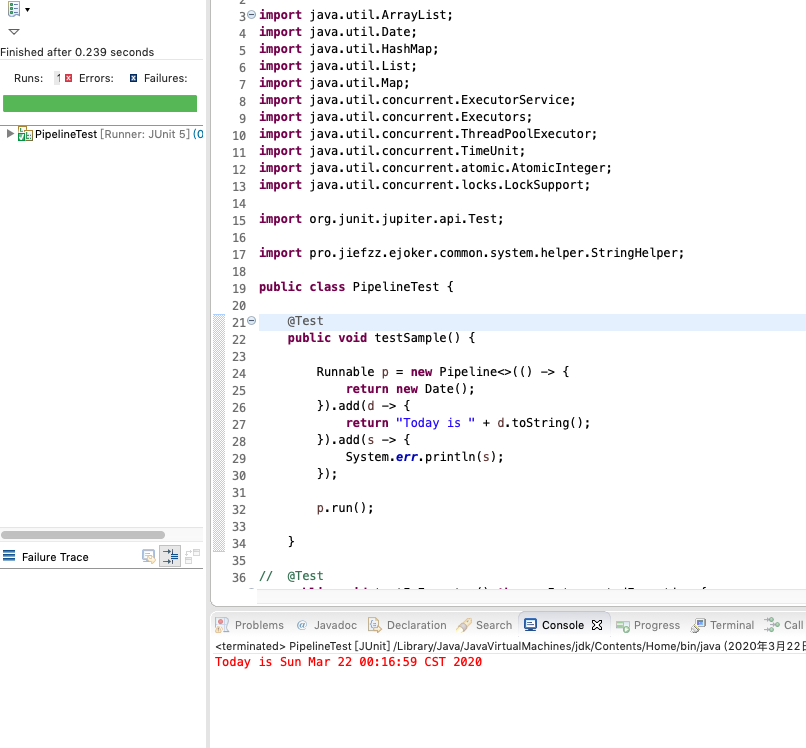
这里初始任务是给出一个日期,中间任务是拼接成人类友好的1句话,最终任务是直接打印到屏幕。(现实中要实现这样一句话,当然是直接撸啦。这里只是为了演示),看看Pipeline初始任务的定义
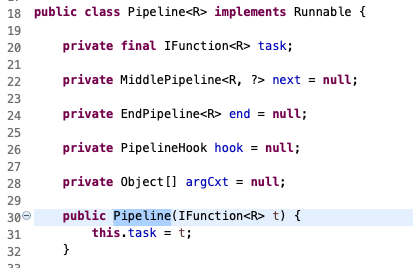
先不看其他属性,看构造方法,传入一个 `IFunction
` ,按照准备一节的定义,他是一个返回类型为声明泛型R,且无参数输入的闭包函数(或称作lambda表达式)。对照上面PipelineTest中就是那个 `() -> { return new Date(); }` , (得益于jdk8的类型推断,在 `new Pipeline<>` 构造时,不用再声明其泛型,编译器能根据闭包函数的return类型推断出这里是个Date类型)。`next`, `end` 是指明管道的下接任务,这可以看出管道是极其类似于任务链/职责链的(需要注意`next`和`end`同时`只能有个一个存在`)。hook是异常管理以及任务间承接时做一个切面方法的,argCxt是记下传递参数,方便hook中的方法使用(这个是因为java需要的,跟管道模式并没有关系)。
再看add方法的一个重载,添加并返回中间task

add方法传入一个`IFunction1`的闭包(lambda),尾数为1,意味着接受一个 `R` 类型的输入,并在方法升声明了 `RT` ,以 `RT` 类型作为输出。其中 `R` 的泛型声明在类上,就是与构造方法的 `R` 是同一个类型。而 `RT` 的具体类型的推断会根据具体的lambda的返回类型决定。这里add方法会返回刚刚构造出来的中间任务的声明对象。add方法需要保证当前任务是没被声明过后续任务的。
再看MiddlePipeline类的定义
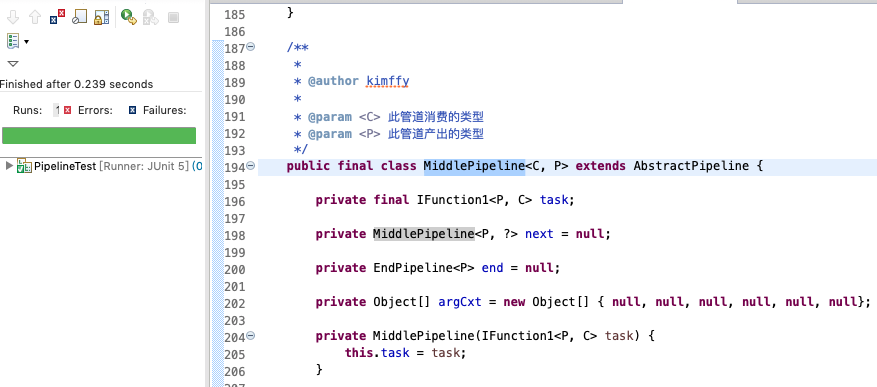
先看构造方法,他就是接受add方法传入的闭包。他声明了两个泛型变量 分别是 ``,其中 `C`代表他的输入类型, `P`代表的他的产出类型。同初始任务一样,他也有`next` 和 `end` 指明他的管道后接任务(`next`)。可以注意到这里的 `next` 和初始任务的属性 `next` 的产出类型都是被放上了泛型通配符 `?` ,是因为任务并没办法知道他的子任务的产出类型的(后面会再说一下这个问题)。
再看add方法的一个另一个重载,添加并返回最终task

类似返回中间态的task,只不过这里用了无返回的闭包。
再看EndPipeline类的定义

最终task的定义清爽很多,他只关心输入,并执行。并且他没有后续任务。
再来补充下AbstractPipeline的解析

这个写法是为了实现`Point4`所描述的事的,只要是同一个pipeline上的task所有入口都是初始任务上的那个`run`方法。(为了省事实现,后续任务的基类和所有派生类都是初始任务的非静态内部类)
再看看初版版本run方法
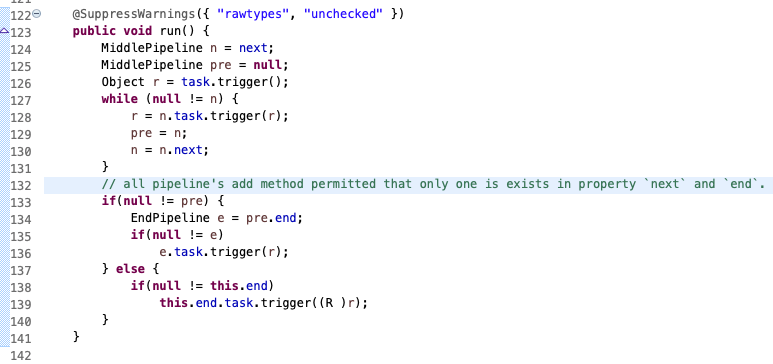
逻辑很简单,执行初始任务,得到结果,然后找后续任务,把结果作为输入来执行后续任务,(其中循环时满足上一个输出作为下一个输入),直到有一个管道类的中间态任务为`null`,然后判断最终任务是否为`null` ,非空则执行它。
需要说明一下这里用 `@SuppressWarnings` 压制了警告,是因为确信java编译器能确保联系两个add进来的task之间的输入输出的类型关系是一致的(这一点,如果不一致,在编写代码时IDE就会报错了)。
到此,一个简单的java实现的pipeline模式基本可以用,跑最开始那个demoTest是没有问题了。
再给一个样例demo
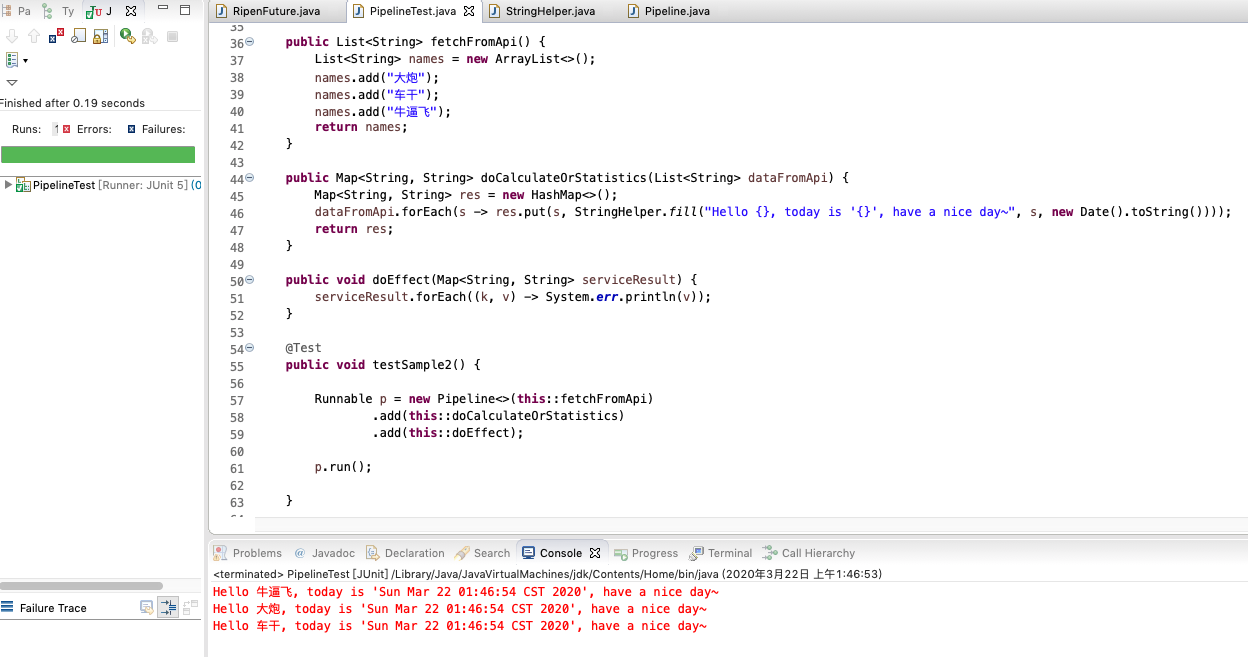
管道中的3个方法的职责就如他的名字那样(实现上我这里只是简单的new一下),然后同过Pipeline类以及它的add方法串起来,执行结果如红色部分。聪明的人肯定能想到,那么像那个java的stream的?嗯很像,stream是类似把元素放到单个跑到上,按照定义那样的自己跑到终点(这也是使用方代码方便地切换到并行流的原因,因为逻辑一致,当然,并发问题是另一个层面的问题)。
而pipeline则横向的一阶段一阶段地执行,如果要增加吞吐量怎么搞?聪明的你肯定能想到分片了,这样走下去就跟parallelstream的意图不谋而合了。那么还有别的好处吗?嗯,你想想Mock测试?职责上有没有让你更好切分了(正如这里命令的方法名那这样)?
---
# 进一步完善
上面一节基本上能把 `Point1` 、 `Point2`的一半 、 `Point3` 、 `Point4` 实现了,剩下 `Point2`中说到的,除了接收前一个任务的输入,还允许管道声明时传入参数的这个功能,以及那个附加题说到的java应用上的妥协。
### pipeline声明上附带参数
这个时候就要好好用到 `准备` 一节中的那些 `函数接口` 了。说起来并不好解析,但是如果你了解过curry柯里化这个概念的话,那一看图你就懂了,看图。
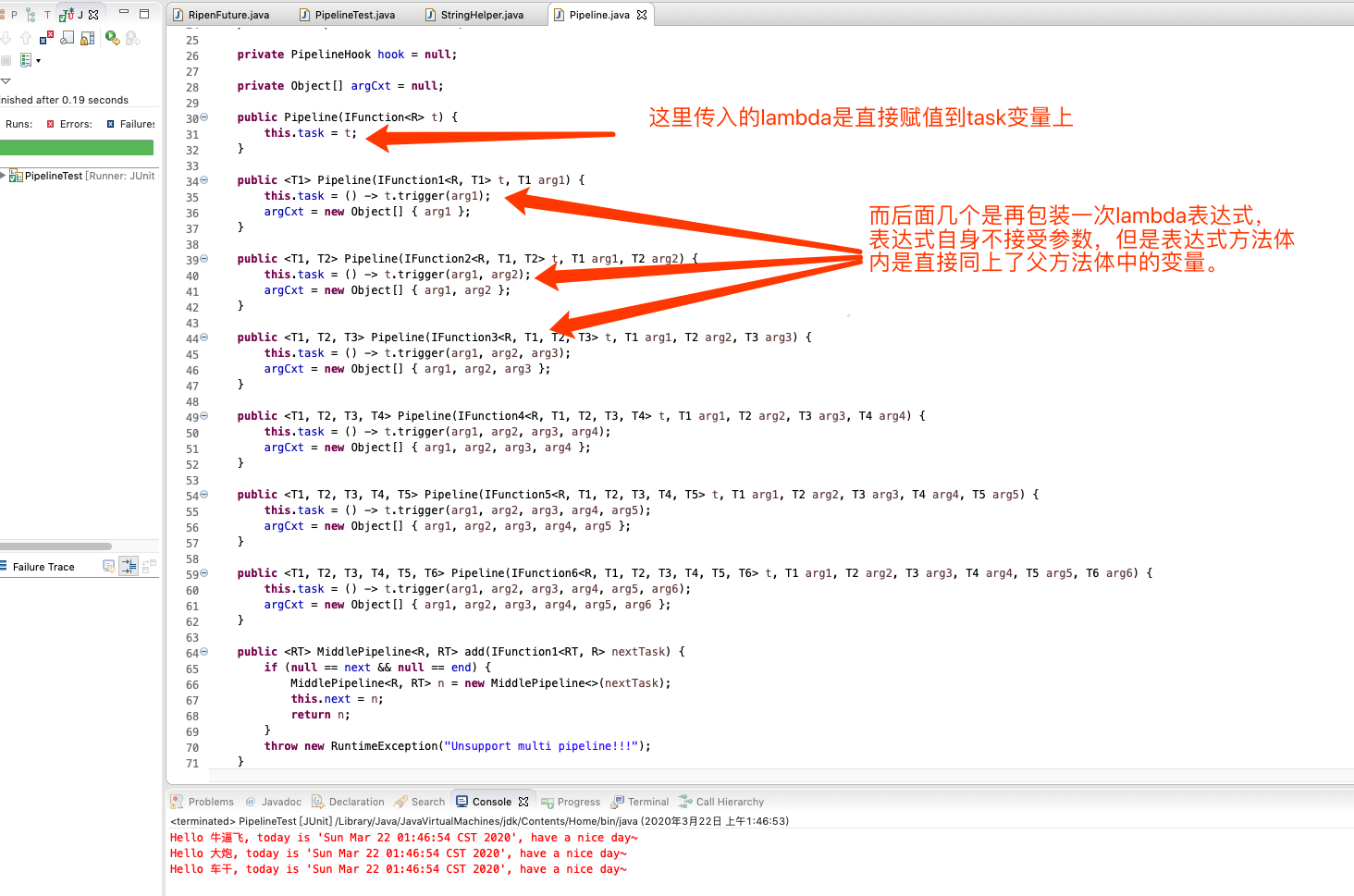
就是把带参数的lambda重新包装一次为不带参数的lambda表达式。后面middlePipeline的带参数部分则是重新封装为一个只接受一个参数且返回类型相同的lambda表达式,这是类似的。
来一个测试看看,并附上图中说明
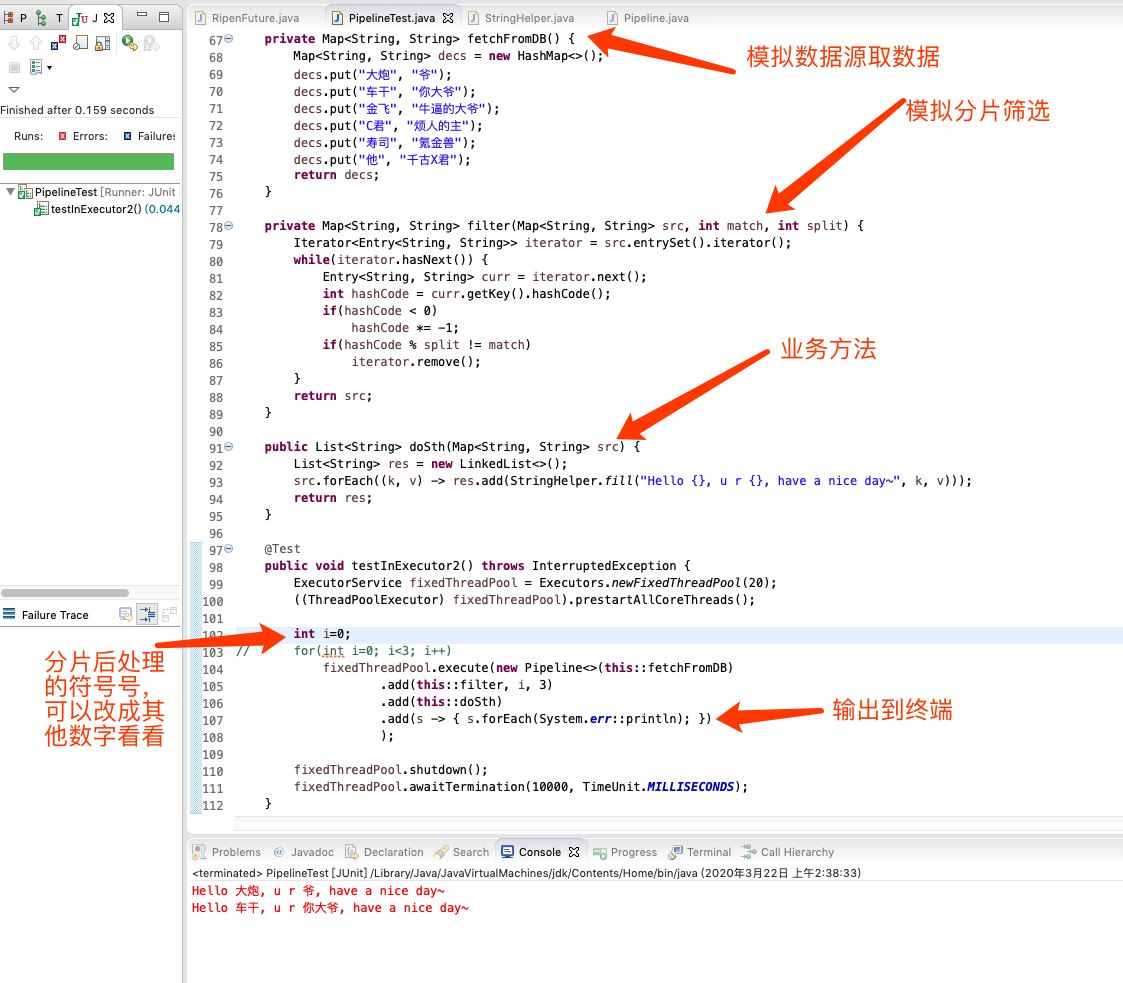
### 对java友好支持
附加题说的这个就跟简单了,找个地方分别设置好两个玩意,在对应的地方执行他们就是了
```
public class PipelineHook {
private boolean preventThrow = false;
// 异常发生时执行此表达式
public final IVoidFunction3 exceptionHandler;
// 调用后续任务钱执行此lambda表达式
public final IVoidFunction1
