# 写在前面的话
相关背景及资源:
[曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享](https://www.cnblogs.com/grey-wolf/p/12044199.html)
[曹工说Spring Boot源码(2)-- Bean Definition到底是什么,咱们对着接口,逐个方法讲解](https://www.cnblogs.com/grey-wolf/p/12051957.html )
[曹工说Spring Boot源码(3)-- 手动注册Bean Definition不比游戏好玩吗,我们来试一下](https://www.cnblogs.com/grey-wolf/p/12070377.html)
[曹工说Spring Boot源码(4)-- 我是怎么自定义ApplicationContext,从json文件读取bean definition的?](https://www.cnblogs.com/grey-wolf/p/12078673.html)
[曹工说Spring Boot源码(5)-- 怎么从properties文件读取bean](https://www.cnblogs.com/grey-wolf/p/12093929.html)
[曹工说Spring Boot源码(6)-- Spring怎么从xml文件里解析bean的](https://www.cnblogs.com/grey-wolf/p/12114604.html )
[曹工说Spring Boot源码(7)-- Spring解析xml文件,到底从中得到了什么(上)](https://www.cnblogs.com/grey-wolf/p/12151809.html)
[曹工说Spring Boot源码(8)-- Spring解析xml文件,到底从中得到了什么(util命名空间)](https://www.cnblogs.com/grey-wolf/p/12158935.html)
[曹工说Spring Boot源码(9)-- Spring解析xml文件,到底从中得到了什么(context命名空间上)](https://www.cnblogs.com/grey-wolf/p/12189842.html)
[曹工说Spring Boot源码(10)-- Spring解析xml文件,到底从中得到了什么(context:annotation-config 解析)](https://www.cnblogs.com/grey-wolf/p/12199334.html)
[曹工说Spring Boot源码(11)-- context:component-scan,你真的会用吗(这次来说说它的奇技淫巧)](https://www.cnblogs.com/grey-wolf/p/12203743.html)
[曹工说Spring Boot源码(12)-- Spring解析xml文件,到底从中得到了什么(context:component-scan完整解析)](https://www.cnblogs.com/grey-wolf/p/12214408.html)
[曹工说Spring Boot源码(13)-- AspectJ的运行时织入(Load-Time-Weaving),基本内容是讲清楚了(附源码)](https://www.cnblogs.com/grey-wolf/p/12228958.html)
[曹工说Spring Boot源码(14)-- AspectJ的Load-Time-Weaving的两种实现方式细细讲解,以及怎么和Spring Instrumentation集成](https://www.cnblogs.com/grey-wolf/p/12283544.html)
[曹工说Spring Boot源码(15)-- Spring从xml文件里到底得到了什么(context:load-time-weaver 完整解析)](https://www.cnblogs.com/grey-wolf/p/12288391.html)
[曹工说Spring Boot源码(16)-- Spring从xml文件里到底得到了什么(aop:config完整解析【上】)](https://www.cnblogs.com/grey-wolf/p/12314954.html)
[曹工说Spring Boot源码(17)-- Spring从xml文件里到底得到了什么(aop:config完整解析【中】)](https://www.cnblogs.com/grey-wolf/p/12317612.html)
[曹工说Spring Boot源码(18)-- Spring AOP源码分析三部曲,终于快讲完了 (aop:config完整解析【下】)](https://www.cnblogs.com/grey-wolf/p/12322587.html)
[曹工说Spring Boot源码(19)-- Spring 带给我们的工具利器,创建代理不用愁(ProxyFactory)](https://www.cnblogs.com/grey-wolf/p/12359963.html)
[曹工说Spring Boot源码(20)-- 码网恢恢,疏而不漏,如何记录Spring RedisTemplate每次操作日志](https://www.cnblogs.com/grey-wolf/p/12375656.html)
[曹工说Spring Boot源码(21)-- 为了让大家理解Spring Aop利器ProxyFactory,我已经拼了](https://www.cnblogs.com/grey-wolf/p/12384356.html)
[曹工说Spring Boot源码(22)-- 你说我Spring Aop依赖AspectJ,我依赖它什么了](https://www.cnblogs.com/grey-wolf/p/12418425.html)
[曹工说Spring Boot源码(23)-- ASM又立功了,Spring原来是这么递归获取注解的元注解的](https://www.cnblogs.com/grey-wolf/p/12535152.html)
[曹工说Spring Boot源码(24)-- Spring注解扫描的瑞士军刀,asm技术实战(上)](https://www.cnblogs.com/grey-wolf/p/12571217.html)
[曹工说Spring Boot源码(25)-- Spring注解扫描的瑞士军刀,ASM + Java Instrumentation,顺便提提Jar包破解](https://www.cnblogs.com/grey-wolf/p/12584861.html)
[曹工说Spring Boot源码(26)-- 学习字节码也太难了,实在不能忍受了,写了个小小的字节码执行引擎](https://www.cnblogs.com/grey-wolf/p/12600097.html)
[工程代码地址](https://gitee.com/ckl111/spring-boot-first-version-learn ) [思维导图地址](https://www.processon.com/view/link/5deeefdee4b0e2c298aa5596)
工程结构图:

# 概要
前面三讲,主要涉及了ASM的一些内容,为什么要讲ASM,主要是因为spring在进入到注解时代后,扫描注解也变成了一项必备技能,现在一个大系统,业务类就动不动大几百个,扫描注解也是比较耗时的,所以催生了利用ASM来快速扫描类上注解的需求。
但是,扫描了那么多类,比如,component-scan扫描了100个类,怎么知道哪些要纳入spring管理,变成bean呢?
这个问题很简单,对吧?component注解、controller、service、repository、configuration注解了的类,就会扫描为bean。
那,假如现在面试官问你,不使用这几个注解,让你自定义一个注解,比如@MyComponent,你要怎么才能把@MyComponent注解的类,扫描成bean呢?
# 核心原理
因为xml版本的component-scan,和注解版本的@Component-scan,内部复用了同样的代码,所以我这里还是以xml版本来讲。
xml版本的,一般如下配置:
```xml
```
该元素的处理器为:
`org.springframework.context.annotation.ComponentScanBeanDefinitionParser`.
该类实现了`org.springframework.beans.factory.xml.BeanDefinitionParser`接口,该接口只有一个方法:
```java
BeanDefinition parse(Element element, ParserContext parserContext);
```
方法核心,就是传入要解析的xml元素,和上下文信息,然后你凭借这些信息,去解析bean definition出来。
假设交给我们来写,大概如下思路:
1. 获取component-scan的base-package属性
2. 获取第一步的结果下的全部class,获取class上的注解信息,保存起来
3. 依次判断class上,是否注解了controller、service、configuration等注解,如果是,则算是合格的bean definition。
spring的实现也差不多,但是复杂的多,核心倒是差不多。比如,spring中:
获取component-scan的base-package属性,可能是个list,所以要遍历;其中,循环内部,调用了ClassPathScanningCandidateComponentProvider#findCandidateComponents。
```java
for (String basePackage : basePackages) {
/**
* 扫描候选的component,注意,这里的名称叫CandidateComponent,所以这里真的就只扫描了 * @component或者基于它的那几个。(service、controller那些)
* 这里是没包含下面这些:
* 1、propertysource注解的
*/
Set
candidates = findCandidateComponents(basePackage);
```
如下所示,在获取某个包下面的满足条件的bean时,代码如下:
```java
public Set findCandidateComponents(String basePackage) {
Set candidates = new LinkedHashSet();
try {
// 1
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + "/" + this.resourcePattern;
Resource[] resources = this.resourcePatternResolver.getResources(packageSearchPath);
// 2
for (Resource resource : resources) {
if (resource.isReadable()) {
try {
// 3
MetadataReader metadataReader = this.metadataReaderFactory.getMetadataReader(resource);
// 4
if (isCandidateComponent(metadataReader)) {
...
```
我们逐个讲解每个代码点:
* 1处,获取包下面的全部resource,类型为Resource
* 2处,遍历Resource数组
* 3处,获取资源的metadataReader,这个metadataReader,可以用来获取资源(一般为class文件)上的注解
* 4处,调用方法isCandidateComponent,判断是否为候选的bean
接下来,我们看看 isCandidateComponent 怎么实现的:
```java
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
// 1
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, this.metadataReaderFactory)) {
return false;
}
}
for (TypeFilter tf : this.includeFilters) {
// 2
if (tf.match(metadataReader, this.metadataReaderFactory)) {
AnnotationMetadata metadata = metadataReader.getAnnotationMetadata();
if (!metadata.isAnnotated(Profile.class.getName())) {
return true;
}
AnnotationAttributes profile = MetadataUtils.attributesFor(metadata, Profile.class);
return this.environment.acceptsProfiles(profile.getStringArray("value"));
}
}
return false;
}
```
* 1处,遍历excludeFilters,如果参数中的class,匹配excludeFilter,则返回false,表示不合格;
* 2处,遍历includeFilters,如果参数中的class,匹配includeFilter,则基本可以断定合格了,但是因为@profile注解的存在,又加了一层判断,如果class上不存在profile,则返回true,合格;
否则,判断profile是否和当前激活了的profile匹配,如果匹配,则返回true,否则flase。
敲黑板,这里的excludeFilters和includeFilters,其实就是@component-scan中的如下属性:
```java
public @interface ComponentScan {
...
/**
* Indicates whether automatic detection of classes annotated with {@code @Component}
* {@code @Repository}, {@code @Service}, or {@code @Controller} should be enabled.
*/
boolean useDefaultFilters() default true;
/**
* Specifies which types are eligible for component scanning.
* Further narrows the set of candidate components from everything in
* {@link #basePackages()} to everything in the base packages that matches
* the given filter or filters.
* @see #resourcePattern()
*/
Filter[] includeFilters() default {};
/**
* Specifies which types are not eligible for component scanning.
* @see #resourcePattern()
*/
Filter[] excludeFilters() default {};
...
}
```
# spring 为什么认识@Component注解的类
大家看了前面的代码,大概知道了,判断一个类,是否足够荣幸,被扫描为一个bean,是依赖于两个属性,一个includeFilters,一个excludeFilters。
但是,我们好像并不能知道:为什么@Component注解的类、@controller、@service注解的类,就能成为一个bean呢?
我们先直接做个黑盒实验,按照如下配置:
```xml
```
被扫描的类路径下,一个测试类,注解了Controller:
```java
@Controller
public class TestController {
}
```
然后我们运行测试代码:
```java
public static void testDefaultFilter() {
ClassPathXmlApplicationContext context =
new ClassPathXmlApplicationContext("classpath:component-scan-default-filter.xml");
TestController bean = context.getBean(TestController.class);
System.out.println(bean);
}
```
在如下地方,debug断点可以看到:
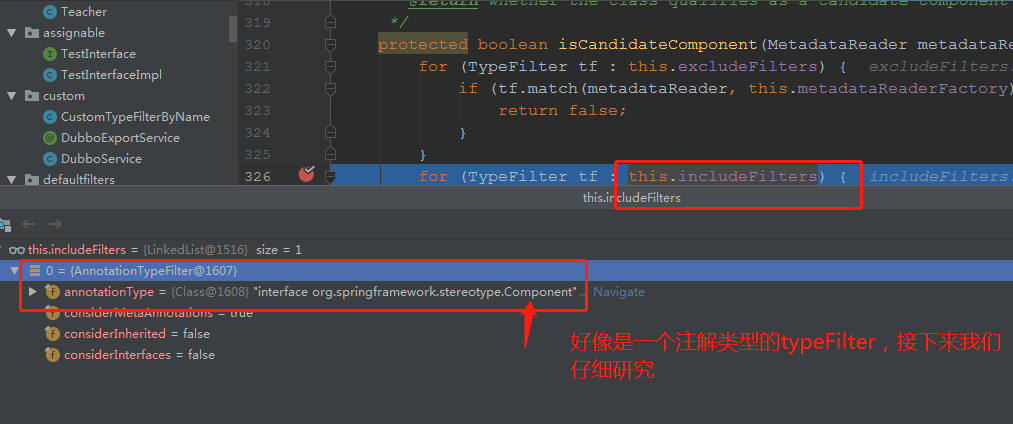
如上的includeFilters,大家看到了,包含了一个TypeFilter,类型为`org.springframework.core.type.filter.AnnotationTypeFilter`,其类继承结构为:
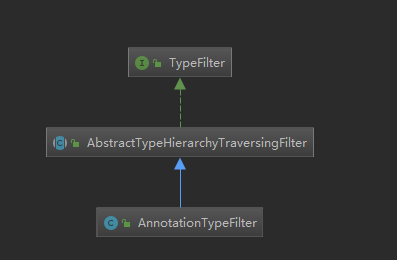
这个TypeFilter,就一个方法:
```java
public interface TypeFilter {
/**
* Determine whether this filter matches for the class described by
* the given metadata.
* @param metadataReader the metadata reader for the target class
* @param metadataReaderFactory a factory for obtaining metadata readers
* for other classes (such as superclasses and interfaces)
* @return whether this filter matches
* @throws IOException in case of I/O failure when reading metadata
*/
boolean match(MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory)
throws IOException;
}
```
方法很好理解,参数是:当前的被扫描到的那个类的元数据reader,通过这个reader,可以取到class文件中的各种信息,底层就是通过ASM方式来实现;第二个参数,可以先跳过。
返回值呢,就是:这个filter是否匹配,我们前面的includeFilters和excludeFilters数组,其元素类型都是这个,所以,这个typeFilter是只管匹配与否,不分是非,不管对错。
我们这里这个org.springframework.core.type.filter.AnnotationTypeFilter,就是根据注解来匹配,比如,我们前面这里的filter,就要求是@Componnet注解标注了的类才可以。
但是,我们的TestController,没有标注Component注解,只标注了Controller注解。对,是这样,但是因为Controller是被@Component标注了的,所以,你标注Controller,就相当于同时标注了下面这一坨:
```java
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Controller {
```
同时,由于我们的AnnotationTypeFilter,在匹配算法上,做的比较漂亮,不止检测直接标注在类上的注解,如Controller,还会去检测:Controller上的注解(俗称:元注解,即,注解的注解)。这块实现逻辑在:
```java
org.springframework.core.type.filter.AnnotationTypeFilter#matchSelf
@Override
protected boolean matchSelf(MetadataReader metadataReader) {
AnnotationMetadata metadata = metadataReader.getAnnotationMetadata();
return metadata.hasAnnotation(this.annotationType.getName()) ||
(this.considerMetaAnnotations && metadata.hasMetaAnnotation(this.annotationType.getName()));
}
```
这里的considerMetaAnnotations,默认为true,此时,就会去检测@Controller上的元注解,发现标注了@Component,所以,这里的检测就为true。
所以,标注了Controller的类,就被扫描为Bean了。
##includeFilters,什么时候添加了这么一个AnnotationTypeFilter
在xml场景下,是在如下位置:
```java
org.springframework.context.annotation.ComponentScanBeanDefinitionParser#parse
public BeanDefinition parse(Element element, ParserContext parserContext) {
String[] basePackages = StringUtils.tokenizeToStringArray(element.getAttribute(BASE_PACKAGE_ATTRIBUTE),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
// Actually scan for bean definitions and register them.
// 1
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element);
Set beanDefinitions = scanner.doScan(basePackages);
registerComponents(parserContext.getReaderContext(), beanDefinitions, element);
return null;
}
```
上述代码,就是负责解析`component-scan`这个标签时,被调用的;代码1处,configureScanner代码如下:
```java
protected ClassPathBeanDefinitionScanner configureScanner(ParserContext parserContext, Element element) {
XmlReaderContext readerContext = parserContext.getReaderContext();
boolean useDefaultFilters = true;
if (element.hasAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE)) {
useDefaultFilters = Boolean.valueOf(element.getAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE));
}
// 1.
ClassPathBeanDefinitionScanner scanner = createScanner(readerContext, useDefaultFilters);
...
}
```
如上,代码1处,createScanner时,传入useDefaultFilters,这是个boolean值,默认为true,来自于component-scan的如下属性,即use-default-filters:
```xml
```
跟踪进去后,最终会调用如下位置的代码:
```java
protected void registerDefaultFilters() {
/**
* 默认扫描Component注解
*/
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
...
}
```
ok,一切就水落石出了。
# 自定义typeFilter--扫描指定注解
说了那么多,我们完全可以禁用掉默认的typeFilter,配置自己想要的typeFilter,比如,我想要定义如下注解:
```java
@Documented
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface MyComponent {
}
```
标注了这个注解的,我们就要把它扫描为bean,那么可以如下配置:
```xml
```
注意,禁用掉默认的filter,避免干扰,可以看到,如下我们的测试类,是只注解了@MyComponent的:
```java
@MyComponent
public class Teacher {
}
```
测试代码:
```java
public static void testAnnotationFilter() {
ClassPathXmlApplicationContext context =
new ClassPathXmlApplicationContext("classpath:component-scan-annotation-filter.xml");
Teacher bean = context.getBean(Teacher.class);
System.out.println(bean);
}
```
输出如下:
> 22:34:01.574 [main] DEBUG o.s.b.f.s.DefaultListableBeanFactory - Returning cached instance of singleton bean 'teacher'
> org.springframework.test.annotation.Teacher@2bd7cf67
# 自定义typeFilter--扫描指定注解
事实上,component-scan允许我们定义多种类型的typeFilter,如AspectJ:
```xml
```
只要满足这个路径的,都会被扫描为bean。
测试路径下,有如下类:
```java
package org.springframework.test.assignable;
public interface TestInterface {
}
public class TestInterfaceImpl implements TestInterface {
}
```
测试代码:
```java
static void testAspectj() {
ClassPathXmlApplicationContext context =
new ClassPathXmlApplicationContext(
"classpath:component-scan-aspectj-filter.xml");
TestInterface bean = context.getBean(TestInterface.class);
System.out.println(bean);
}
```
输出如下:
> 22:37:22.347 [main] DEBUG o.s.b.f.s.DefaultListableBeanFactory - Returning cached instance of singleton bean 'testInterfaceImpl'
> org.springframework.test.assignable.TestInterfaceImpl@3dea2f07
这个背后使用的typefilter,类型为:
org.springframework.core.type.filter.AspectJTypeFilter。
```java
public class AspectJTypeFilter implements TypeFilter {
private final World world;
private final TypePattern typePattern;
public AspectJTypeFilter(String typePatternExpression, ClassLoader classLoader) {
this.world = new BcelWorld(classLoader, IMessageHandler.THROW, null);
this.world.setBehaveInJava5Way(true);
PatternParser patternParser = new PatternParser(typePatternExpression);
TypePattern typePattern = patternParser.parseTypePattern();
typePattern.resolve(this.world);
IScope scope = new SimpleScope(this.world, new FormalBinding[0]);
this.typePattern = typePattern.resolveBindings(scope, Bindings.NONE, false, false);
}
// 1
public boolean match(MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory)
throws IOException {
String className = metadataReader.getClassMetadata().getClassName();
ResolvedType resolvedType = this.world.resolve(className);
return this.typePattern.matchesStatically(resolvedType);
}
}
```
代码1处,即:使用aspectj的方式,来判断是否候选的class是否匹配。
# 自定义typeFilter--指定类型的子类或实现类被扫描为bean
我们也可以这样配置:
```xml
```
这里的类型是assignable,只要是`TestInterface`的子类,即可以被扫描为bean。
其实现:
```java
public class AssignableTypeFilter extends AbstractTypeHierarchyTraversingFilter {
private final Class targetType;
/**
* Create a new AssignableTypeFilter for the given type.
* @param targetType the type to match
*/
public AssignableTypeFilter(Class targetType) {
super(true, true);
this.targetType = targetType;
}
@Override
protected boolean matchClassName(String className) {
return this.targetType.getName().equals(className);
}
@Override
protected Boolean matchSuperClass(String superClassName) {
return matchTargetType(superClassName);
}
@Override
protected Boolean matchInterface(String interfaceName) {
return matchTargetType(interfaceName);
}
protected Boolean matchTargetType(String typeName) {
if (this.targetType.getName().equals(typeName)) {
return true;
}
else if (Object.class.getName().equals(typeName)) {
return Boolean.FALSE;
}
else if (typeName.startsWith("java.")) {
try {
Class clazz = getClass().getClassLoader().loadClass(typeName);
return Boolean.valueOf(this.targetType.isAssignableFrom(clazz));
}
catch (ClassNotFoundException ex) {
// Class not found - can't determine a match that way.
}
}
return null;
}
}
```
总体来说,逻辑不复杂,反正就是:只要是我们指定的类型的子类或者接口实现,就ok。
# 自定义typeFilter--实现自己的typeFilter
我这里实现了一个typeFilter,如下:
```java
/**
* 自定义的类型匹配器,如果注解了我们的DubboExportService,就匹配;否则不匹配
*/
public class CustomTypeFilterByName implements TypeFilter {
@Override
public boolean match(MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory) throws IOException {
boolean b = metadataReader.getAnnotationMetadata().hasAnnotation(DubboExportService.class.getName());
if (b) {
return true;
}
return false;
}
}
```
判断很简单,注解了DubboExportService就行。
看看怎么配置:
```xml
```
# 总结
好了,说了那么多,大家都理解没有呢,如果没有,建议把代码拉下来一起跟着学。
其实dubbo貌似就是通过如上的自定义typeFilter来实现的,回头我找找相关源码,佐证一下,补上。
demo的源码在:

