# 使用 puppeteer 爬取链家房价信息
[toc]
此文记录了使用 `puppeteer` 库进行动态网站爬取的过程。
## 页面结构
[地址](https://wh.lianjia.com/chengjiao/)
链家的历史成交记录页面在这里,它是`后台渲染模式`,无法通过监听和模拟 `xhr 请求`来快速获取,只能想办法分析它的页面结构,进行元素提取。
页面通过分页进行管理,例如其第二页链接为`https://wh.lianjia.com/chengjiao/baibuting/pg2/`,遍历分页没问题了。
有问题的是,通过首页可以看到它的历史信息有 5 万多条,一页有 30 条,但它的主页只显示了 100 页,没办法通过遍历分页获取全部数据。
好在,链家提供了筛选器。经过测试,使用街道级的区域筛选可以满足分页的限制。
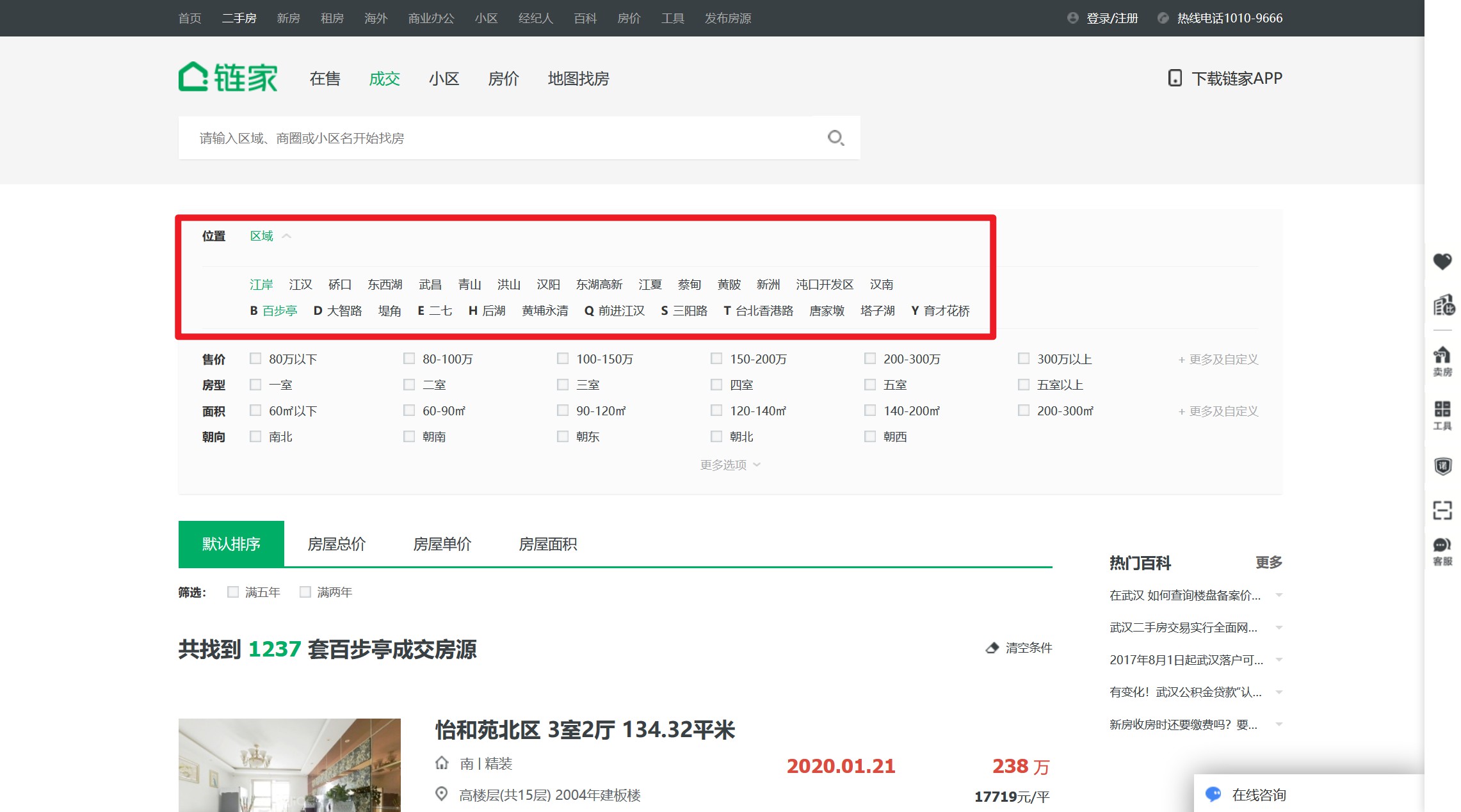
那么爬取思路就是,遍历`区级`按钮,在每个区级按钮下面遍历其`街道按钮`,在每个街道按钮下,遍历其每个分页。
## 爬虫库
nodejs 领域的爬虫库,比较常用的有 `cheerio`、`pupeteer`。其中,`cheerio`一般用作静态网页的爬取,`pupeteer` 常用作爬取动态网页。
虽然链家网页是后台静态生成的,但是考虑到要对页面进行操作(*点击其区域选择器*),因此优先考虑选用 `pupeteer` 库。
### pupeteer 库
pupeteer 库是谷歌浏览器在17年自行开发Chrome Headless特性后,与之同时推出的。本质上就是一个不含界面的浏览器,有点像电脑的终端,所有操作都通过代码进行操作。
这样,我们就可以在对网站进行检索之前,操作指定元素滚动到底部,以触发更多信息。或者在需要翻页的时候,操作代码对翻页按钮进行点击,然后对翻页后的页面进行相关处理。
## 实现
这是其 [git 地址](https://github.com/puppeteer/puppeteer),这是其[中文教程](https://zhaoqize.github.io/puppeteer-api-zh_CN/)。
### 打开待爬页面
```js
// 1. 引包
const puppeteer = require('puppeteer');
// 2. 在异步环境中执行(pupeteer 所有操作都是异步实现的)
(async ()=>{
// 创建浏览器窗口
const browser = await puppeteer.launch({
headless: false, // 有界面模式,可以查看执行详情
});
// 创建标签页
const page = await browser.newPage();
// 进入待爬页面
await page.goto('https://wh.lianjia.com/chengjiao/');
// 遍历页面
})()
```
这样就成功在 `pupeteer` 中打开链家网站了。
光打开是不够的,我们期待的是在网页中操作筛选按钮,获取每个街道的页面,以便我们遍历其分页进行查询。
### 遍历区级页面
我们首先要找到区级按钮,并点击它。
**标准思路**
```js
(async ()=>{
// ......
// 使用选择器
/* page.$$() 会在页面执行 document.querySelectorAll,并返回 ElementHandle 对象的数组
page.$() 执行 document.querySelector,返回 ElementHandle 对象
*/
let districts = await page.$$('div[data-role=ershoufang]>div>a')
for(let district of districts){
await district.click() // 模拟点击页面对象
// 遍历街道
}
})
```
第一想法大概是这样写,通过选择器拿到所有按钮,然后挨个点击。
恭喜,收到报错一枚。
`Error: Execution context was destroyed, most likely because of a navigation.`
说你的执行上下文被干掉了,可能是因为页面的导航。
为了弄清这个问题,我们有必要先看一下`Execution context`是什么东东。
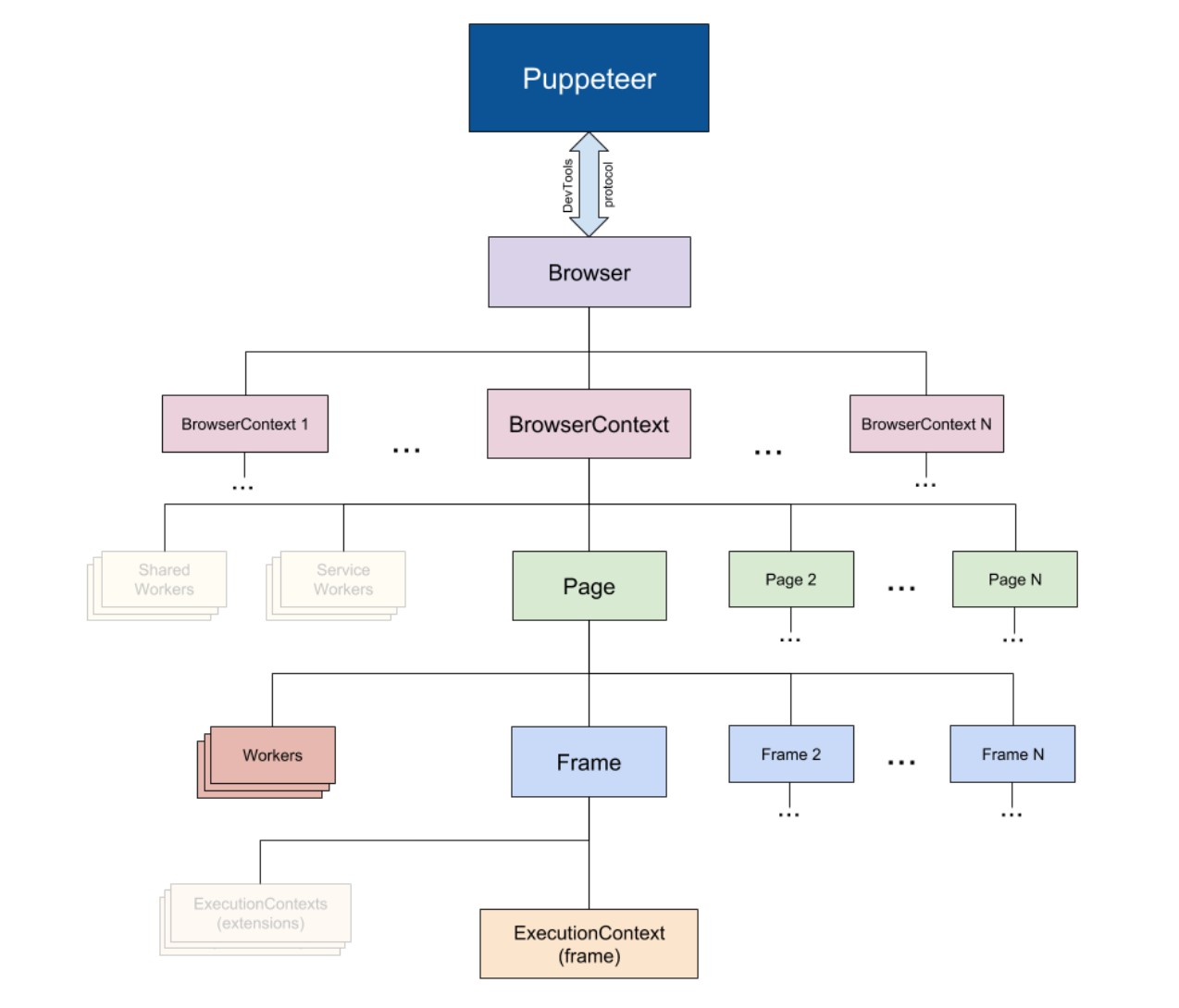
这是 `pupeteer` 内部的组织结构,一个 `page` 下面有很多个 `Frame` `,一个Frame` 下面有一个 `Execution context`。
我们这个报错刚好就是在点击第二个按钮时触发的。
那就了然了。点击第一下导航成功, `page` 就变了,而你的第二个 `district` 还在依赖之前的那个 `page` ,结果找不到 `Execution context` ,然后就报错了。
如何解决呢?
有两个思路。
#### 方法一
将区级按钮的链接缓存下来,这样在遍历跳转的时候,它就不会依赖 `原page` 。
```js
(async ()=>{
// ......
// 使用选择器
/* page.$$eval('选择器', callback(eles)) 会在page页面内部执行 Array.from(document.querySelectorAll(selector)),然后把数组参数传给 callback
*/
let districts = await page.$$eval('div[data-role=ershoufang]>div>a',links=>{
// 对传进来的元素处理
let arr = []
for(let link of links){
arr.push(link.href)
}
return arr
})
for(let district of districts){
await page.goto(district) // 使用 page.goto() 替代点击
// 遍历街道
}
})
```
这里需要特殊解释的是,对于页面的操作如点击按钮、导航链接等等都是在 `node` 里完成的。而**在页面之中的操作,比如读取元素的某个属性,是在浏览器的引擎里处理的**,类似于 `html` 文件中 `script` 标签里的脚本。
对于 pupeteer ,它的脚本文件一般都被包裹在 `*.*eval()` 之中,譬如`page.evaluate(pageFunction[, ...args])`、 `page.$eval(selector,pageFunction, ...args)`、`elementHandle.$eval(selector, pageFunction, ...args)`。
**在这种脚本中,无法访问 `node` 环境下的全局变量,除非你传参数进去**:
```js
let name = 'bug'
page.$eval('id',(ele/* 这个参数是该方法自身返回的所选择元素 */, nodeParam)=>{
console.log(nodeParam) // 'bug'
},name)
```
#### 方法二
另一个办法,就是在进行链接跳转时,不在 `原page` 直接跳,而是新开一个 `page2` 页面。这样你就不能使用点击,而是获取其链接。
```js
(async ()=>{
// 新建一个标签页用来做跳转缓存
const page2 = await browser.newPage();
// ......
// 仍使用原方法获取元素
let districts = await page.$$('div[data-role=ershoufang]>div>a')
for(let district of districts){
let link = (await district.getProperty('href'))._remoteObject.value // 获取属性
await page2.goto(link) // 在新页面跳转,原 page 不变
// 遍历街道
}
})
```
这两种办法都可行,不过第一种办法似乎更简单一点,将每个按钮的链接都缓存过后,似乎也没有再保留 `原page` 的必要。
总之呢,我们现在已经能够遍历各个区级页面了!
### 遍历街道页面
以下操作均在遍历`区级页面`的 `for` 循环中书写。
操作与遍历区级页面类似,首先找到街道按钮,然后循环跳转。这里的跳转逻辑也跟上述类似,要么选择缓存其链接,要么新开一个 `page3` 做分页循环。
我喜欢缓存,毕竟新开页面也要耗内存不是?
```js
(async ()=>{
let streets = await page.$$eval(
'div[data-role=ershoufang] div:last-child a', (links => {
// 对传进来的元素处理
let arr = []
for(let link of links){
arr.push(link.href)
}
return arr
})
)
for(let street of streets){
await page.goto(street) // 使用 page.goto() 替代点击
// 遍历页码
}
})
```
### 遍历分页
因为分页的链接处理比较简单,递增就可以了。
有个小问题,我们如何确定循环结束。
有几个思路,
**第一**,街道首页会显示该区域共有多少套房,每个分页是 `30` 套,除一下就可以了。
**第二**,我们可以获取分页按钮的最后一个数值,不过遗憾的是最后一个数值大部分情况下是 `下一页`,鉴于此我们也许可以做个 `while` 循环,当该分页的最后一个按钮不是 `下一页` 时表示遍历结束。但对于房数比较少的区域,也许只有两三页,本来就没有`下一页` 按钮,那就会直接跳过漏爬。
**第三**,查看一下页面结构。以上都是从渲染过后的页面上看到的信息,而在页面结构上也许有 `totalPage` 之类的字段。仔细看了下分页组件,果然在标签属性里有总页数。
以上思路中,第二个大概是最二的,然而我就是用的这个方法…出了好多低级错误,才换。其实第二个只要简单优化一下也可以用,比如获取分页按钮的最后一个,如果是`下一页`,就获取它前面的兄弟元素,还是能轻松得到总页数。
总之让我们用最简单的吧:
```js
// 遍历页码
let totalPage = await page.$eval('div.house-lst-page-box',el => {
return JSON.parse(el.getAttribute('page-data')).totalPage
})
for (let i = 1; i <= totalPage; i++) {
// 这里的一个小优化,因为街道首页即是第一页,没必要再跳
if(i > 1) await page.goto(`${street}pg${i}`) // 跳转拼接的分页链接
// 业务代码
}
```
### 业务信息
这样,我们就实现了每一页数据的遍历,可以开开心心地写业务逻辑了。
**基本上能看到的数据,都可以抓取下来,全凭你的兴趣。**
这里分享一下我的部分爬虫代码:
```js
// 基本就是 page.$$eval() 选择元素,然后在页面内执行分析,将结果 return 出来
let page_storage = await page.$$eval('ul.listContent>li', (lis => lis.map(li => {
let link = li.querySelector('a').href;
let [orientation, decoration] = li.querySelector('.houseInfo').innerText.split(' | ')
let title = li.querySelector('div.title>a').innerText.split(' ')
let [name, type, area] = [...title]
let date = li.querySelector('.dealDate').innerText
let totalPrice = li.querySelector('.totalPrice .number').innerText
let unitPrice = li.querySelector('.unitPrice .number').innerText
return {
// 用不了 es6 语法
orientation: orientation,
decoration: decoration,
link: link,
name: name,
type: type,
area: area,
date: date,
totalPrice: totalPrice,
unitPrice: unitPrice
}
}))
// 成果保存
```
### 成果保存
我是把数据先存在本地了,也可以直接保存到数据库。
这里需要注意的是,要将读写文件的操作也做下 `Promise` 封装,不然异步执行得有点乱。
```js
const saveTOLocal = function (obj) {
// 返回一个 promise 对象
return new Promise((resolve, reject) => {
// 读取文件
fs.readFile('.https://img.qb5200.com/download-x/data/yichengjiao.json', 'utf8', (err, data) => {
let res = JSON.parse(data)
// 更新内容
res.push(obj)
// 写入文件
fs.writeFile(`.https://img.qb5200.com/download-x/data/yichengjiao.json`, JSON.stringify(res), 'utf8', (err) => {
resolve() // 写入完成后,promise resolved
})
})
})
}
(async ()=>{
// ......
await saveToLocal(page_storage)
})
```
因为网络原因,或者代码问题,或者各种奇奇怪怪的意想不到的事情,都可能导致你的爬虫系统崩溃,所以,**不要等全部爬取完后统一保存——你可能会搞砸掉所有鸡蛋**。而是分阶段性地保存,比如我是以街道为单位进行保存的(上面的以页为单位只是演示)。
同时,还**要有预案,当爬虫崩溃后,你要知道它在哪崩溃的,如何让它在崩溃的位置重新启动**,而不是每次都要从头开始。
### 代码优化
主干功能部分已经说完了,对于几个细小的优化点也是很重要的,它很可能会让你节省好多好多时间。
算笔账,比如总共有 5万 套房,你要打开 5万 个网页,一个网页打开两三秒,你需要 40 个小时才能爬完。**如果把打开网页的速度提升一秒,你就能节省 20 个小时!**
**page.goto()**
在上面的描述中,我统一用 `page.goto(url)` 的方式,没有加任何配置,是为了方便理解。现在,这些关键的配置必须要补上了。
```js
page.goto(url, {
/*
网络超时,默认是 30s 。
但难免遇到网络不好的时候,如果一过 30s 就报错,还是挺难受的。
设为 0 表示无限等待。
*/
timeout:0,
/*
页面认为跳转成功的满足条件,默认是 'load',页面的 load 事件触发才算成功。
但其实大部分情况下用不到 load 条件,我们需要的很多页面信息都在结构和样式里,当 domcontentloaded 触发就够用了。
时间对比上,load 要两三秒,domcontentloaded 一秒都用不了,提升非常大。
*/
waitUntil:'domcontentloaded'
})
```
**业务优化**
链家这个网站自身特性上,它一个街道有时对应好几个区,当你爬完这个区的所有街道,爬另一个区时发现又跳回这个街道再爬一次,就很消耗时间做无用功。
我的解决办法是在爬街道的时候,**给街道名做缓存**。当下次爬到它时,就直接跳过爬下一个。
我还有一个额外的需求是爬每套房子的坐标,在分页界面没有,必须跳转到该房子的链接下找。如果每个房子都跳一遍,5万 套,一个 1s 也要十几个小时。
不过链家中的房子地址是以小区为单位的,同一小区的所有房子共享同一坐标。所以,我**在爬取街道信息的时候,都新建一个小区名缓存**,如之前有记录,就不必跳转直接沿用之前的坐标。据测试,一个街道的几百栋房子,一般分布在 60 个左右的小区里。所以我只需要跳转60次就能获取几百个数据。
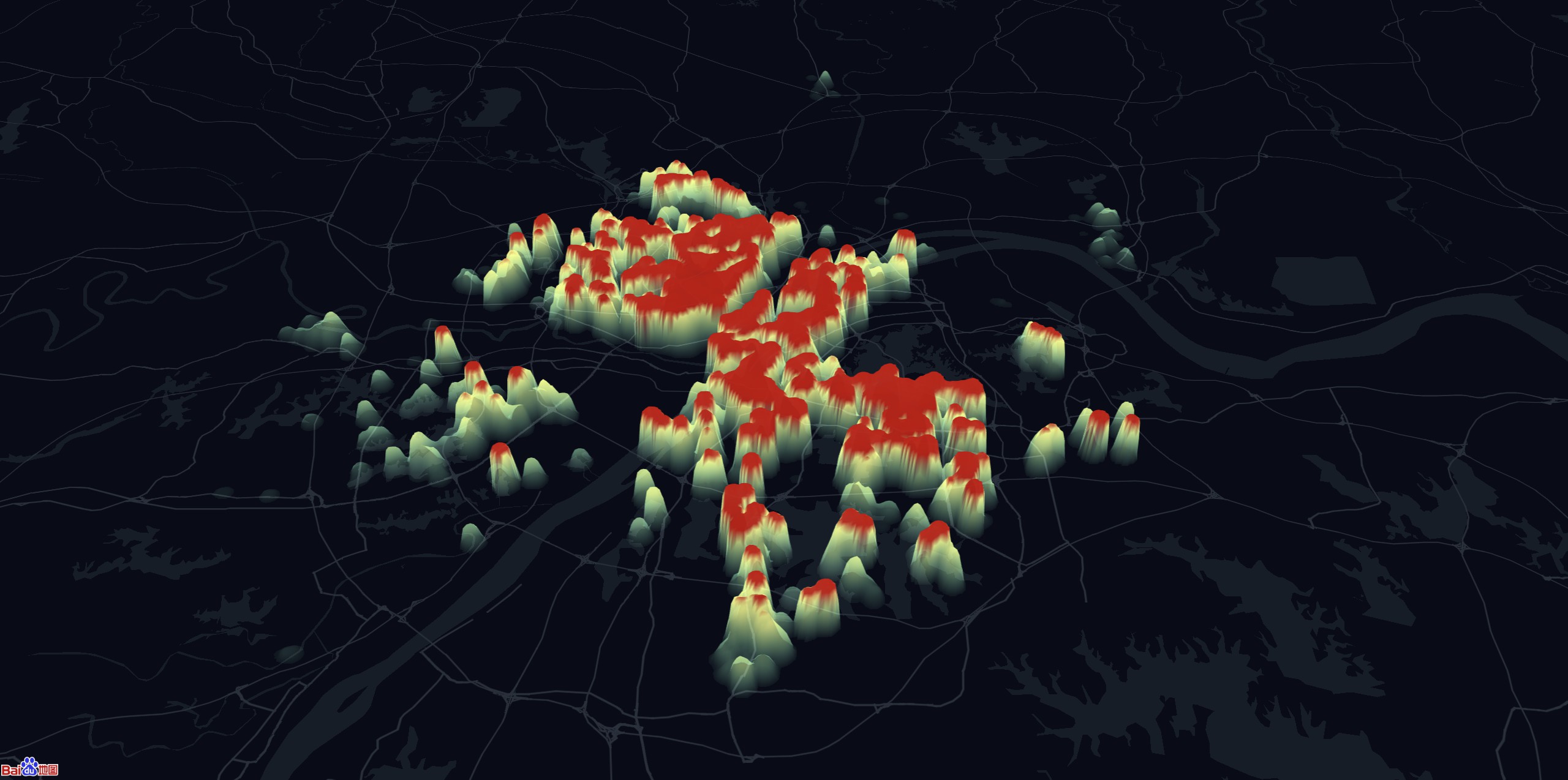
## 成果展示
综合使用上述方法,共花了一个半小时获取了 5万 套房子的属性和坐标。
这是使用 `leaflet` 做的一点可视化:
**房价热力图**
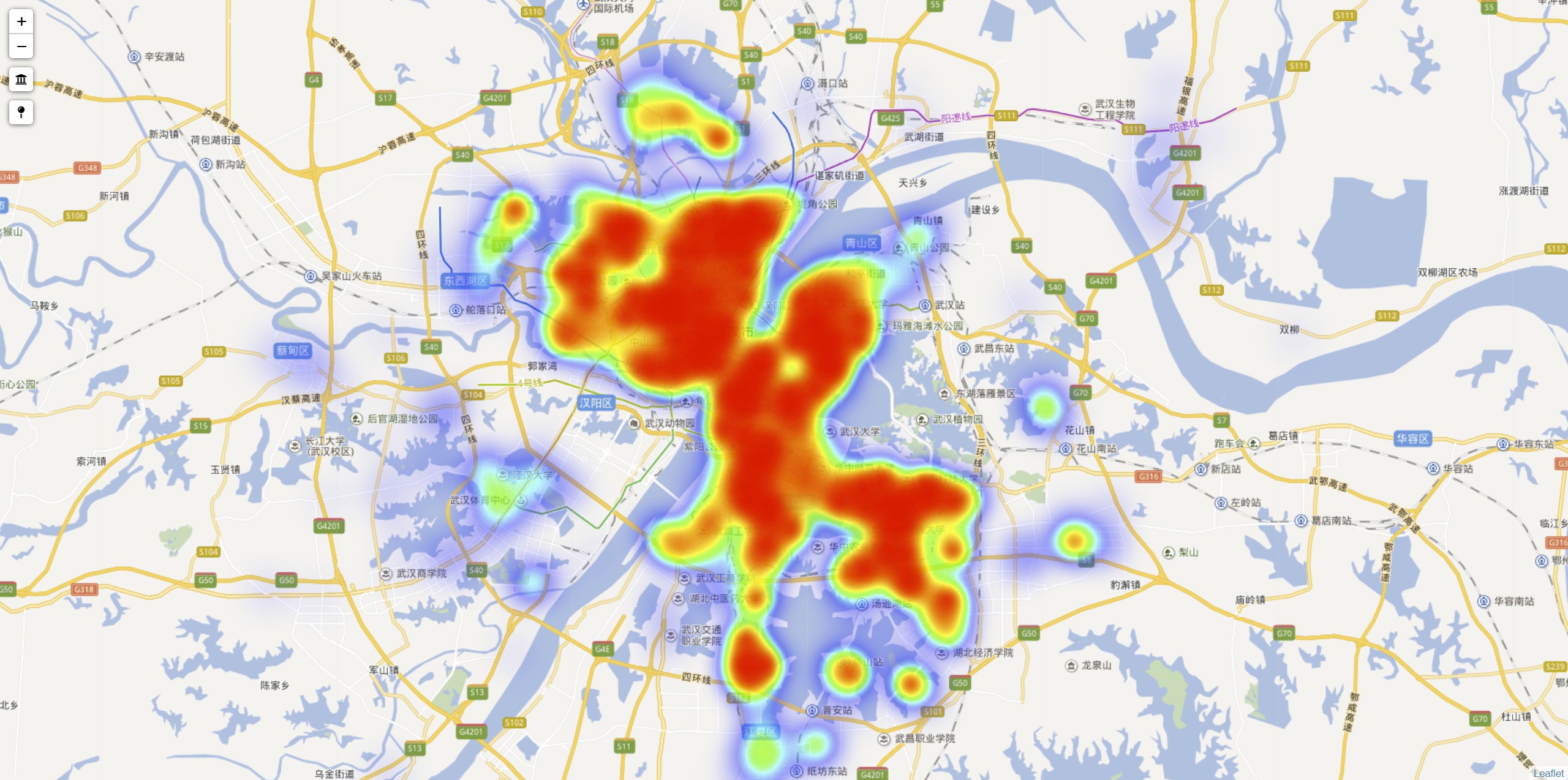
**房屋点聚合**

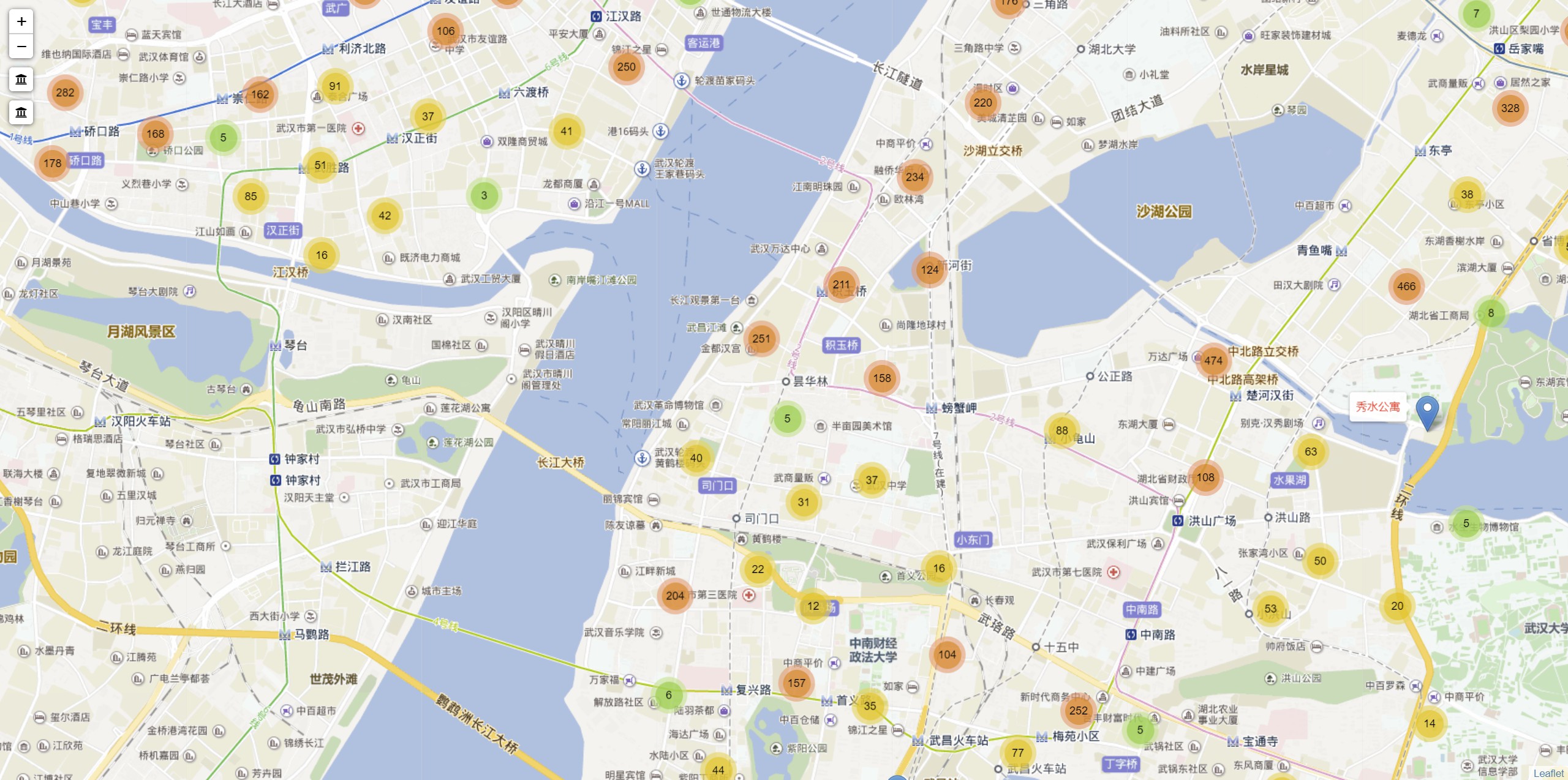
**百度热力图**