概要
本篇主要介绍聚合查询的内部原理,正排索引是如何建立的和优化的,fielddata的使用,最后简单介绍了聚合分析时如何选用深度优先和广度优先。
正排索引
聚合查询的内部原理是什么,Elastichsearch是用什么样的数据结构去执行聚合的?用倒排索引吗?
工作原理
我们了解到倒排索引对搜索是非常高效的,但是在排序或聚合操作方面,倒排索引就显得力不从心,例如我们举个实际案例,假设我们有两个文档:
- I have a friend who loves smile
- love me, I love you
为了建立倒排索引,我们先按最简单的用空格把每个单词分开,可以得到如下结果:
*表示该列文档中有这个词条,为空表示没有该词条
| Term | doc1 | doc2 |
|---|---|---|
| I | * | * |
| have | * | |
| a | * | |
| friend | * | |
| who | * | |
| loves | * | |
| smile | * | |
| love | * | |
| me | * | |
| you | * |
如果我们要搜索love you,我们只需要查找包含每个词条的文档:
| Term | doc1 | doc2 |
|---|---|---|
| love | * | |
| you | * |
搜索是非常高效的,倒排索引根据词条来排序,我们首先在词条列表中打到love,然后扫描所有的列,可以快速看到doc2包含这个关键词。
但聚合操作呢?我们需要找到doc2里所有唯一的词条,用倒排索引来完成,代价就非常高了,需要迭代索引的每个词条,看一下有没有doc2,有就把这个词条收录起来,没有就检查下一个词条,直到整个倒排索引全部搜索完成。很慢而且难以扩展,并且 会随着数据量的增加而增加。
聚合查询肯定不能用倒排索引了,那就用正排索引,建立的数据结构将变成这样:
| Doc | terms |
|---|---|
| doc1 | I, have, a, friend, who, loves, smile |
| doc2 | love, me, I, you |
这样的数据结构,我们要搜索doc2包含多少个词条就非常容易了。
倒排索引+正排索引结合的优势
如果聚合查询里有带过滤条件或检索条件,先由倒排索引完成搜索,确定文档范围,再由正排索引提取field,最后做聚合计算。
这样才是最高效的
帮助理解两个索引结构
倒排索引,类似JAVA中Map的k-v结构,k是分词后的关键词,v是doc文档编号,检索关键字特别容易,但要找到aggs的value值,必须全部搜索v才能得到,性能比较低。
正排索引,也类似JAVA中Map的k-v结构,k是doc文档编号,v是doc文档内容,只要有doc编号作参数,提取相应的v即可,搜索范围小得多,性能比较高。
底层原理
基本原理
- 正排索引也是索引时生成(index-time),倒排索引也是index-time。
- 核心写入原理与倒排索引类似,同样基于不变原理设计,也写os cache,磁盘等,os cache要存放所有的doc value,存不下时放磁盘。
- 性能问题,jvm内存少用点,os cache搞大一些,如64G内存的机器,jvm设置为16G,os cache内存给个32G左右,os cache够大才能提升正排索引的缓存和查询效率。
column压缩
正排索引本质上是一个序列化的链表,里面的数据类型都是一致的(不一致说明索引建立不规范),压缩时可以大大减少磁盘空间、提高访问速度,如以下几种压缩技巧:
- 如果所有的数值各不相同(或缺失),设置一个标记并记录这些值
- 如果这些值小于 256,将使用一个简单的编码表
- 如果这些值大于 256,检测是否存在一个最大公约数
- 如果没有存在最大公约数,从最小的数值开始,统一计算偏移量进行编码
例如:
doc1: 550
doc2: 600
doc3: 500
最大公约数50,压缩后的结果可能是这样:
doc1: 11
doc2: 12
doc3: 10
同时最大公约数50也会保存起来。
禁用正排索引
正排索引默认对所有字段启用,除了analyzed text。也就是说所有的数字、地理坐标、日期和不分析(not_analyzed)字符类型都会默认开启。针对某些字段,可以不存正排索引,减少磁盘空间占用(生产不建议使用,毕竟无法预知需求的变化),示例如下:
# 对字段sessionId取消正排索引
PUT music
{
"mappings": {
"_doc": {
"properties": {
"sessionId": {
"type": "keyword",
"doc_values": false
}
}
}
}
}
同样的,我们对倒排索引也可以取消,让一个字段可以被聚合,但是不能被正常检索,示例如下:
PUT music
{
"mappings": {
"_doc": {
"properties": {
"sessionId": {
"type": "keyword",
"doc_values": true,
"index": false
}
}
}
}
}
fielddata原理
上一小节我们提到,正排索引对分词的字段是不启用的,如果我们尝试对一个分词的字段进行聚合操作,如music索引的author字段,将得到如下提示:
Fielddata is disabled on text fields by default. Set fielddata=true on [author] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.
这段提示告诉我们,如果分词的字段要支持聚合查询,必须设置fielddata=true,然后把正排索引的数据加载到内存中,这会消耗大量的内存。
解决办法:
- 设置fielddata=true
- 使用author.keyword字段,建立mapping时有内置字段的设置。
内部原理
analyzed字符串的字段,字段分词后占用空间很大,正排索引不能很有效的表示多值字符串,所以正排索引不支持此类字段。
fielddata结构与正排索引类似,是另外一份数据,构建和管理100%在内存中,并常驻于JVM内存堆,极易引起OOM问题。
加载过程
fielddata加载到内存的过程是lazy加载的,对一个analzyed field执行聚合时,才会加载,而且是针对该索引下所有的文档进行field-level加载的,而不是匹配查询条件的文档,这对JVM是极大的考验。
fielddata是query-time创建,动态填充数据,而不是不是index-time创建,
内存限制
indices.fielddata.cache.size 控制为fielddata分配的堆空间大小。 当你发起一个查询,分析字符串的聚合将会被加载到fielddata,如果这些字符串之前没有被加载过。如果结果中fielddata大小超过了指定大小,其他的值将会被回收从而获得空间(使用LRU算法执行回收)。
默认无限制,限制内存使用,但是会导致频繁evict和reload,大量IO性能损耗,以及内存碎片和gc,这个参数是一个安全卫士,必须要设置:
indices.fielddata.cache.size: 20%
监控fielddata内存使用
Elasticsearch提供了监控监控fielddata内存使用的命令,我们在上面可以看到内存使用和替换的次数,过高的evictions值(回收替换次数)预示着内存不够用的问题和性能不佳的原因:
# 按索引使用 indices-stats API
GET /_stats/fielddata?fields=*
# 按节点使用 nodes-stats API
GET /_nodes/stats/indices/fielddata?fields=*
# 按索引节点
GET /_nodes/stats/indices/fielddata?level=indices&fields=*
fields=*表示所有的字段,也可以指定具体的字段名称。
熔断器
indices.fielddata.cache.size的作用范围是当前查询完成后,发现内存不够用了才执行回收过程,如果当前查询的数据比内存设置的fielddata 的总量还大,如果没有做控制,可能就直接OOM了。
熔断器的功能就是阻止OOM的现象发生,在执行查询时,会预算内存要求,如果超过限制,直接掐断请求,返回查询失败,这样保护Elasticsearch不出现OOM错误。
常用的配置如下:
- indices.breaker.fielddata.limit:fielddata的内存限制,默认60%
- indices.breaker.request.limit:执行聚合的内存限制,默认40%
- indices.breaker.total.limit:综合上面两个,限制在70%以内
最好为熔断器设置一个相对保守点的值。fielddata需要与request断路器共享堆内存、索引缓冲内存和过滤器缓存,并且熔断器是根据总堆内存大小估算查询大小的,而不是实际堆内存的使用情况,如果堆内有太多等待回收的fielddata,也有可能会导致OOM发生。
ngram对fielddata的影响
前缀搜索一章节我们介绍了ngram,ngram会生成大量的词条,如果这个字段同时设置fielddata=true的话,那么会消耗大量的内存,这里一定要谨慎。
fielddata精细化控制
fielddata过滤
过滤的主要目的是去掉长尾数据,我们可以加一些限制条件,如下请求:
PUT /music/_mapping/children
{
"properties": {
"tags": {
"type": "text",
"fielddata": true,
"fielddata_frequency_filter": {
"min": 0.001,
"max": 0.1,
"min_segment_size": 500
}
}
}
}
fielddata_frequency_filter过滤器会基于以下条件进行过滤:
- 出现频率介绍0.1%和10%之间
- 忽略文档个数小于500的段文件
fidelddata是按段来加载的,所以出现频率是基于某个段计算得来的,如果一个段内只有少量文档,统计词频意义不大,等段合并到大的段当中,超过500个文档这个限制,就会纳入计算。
fielddata数据对内存的占用是显而易见的,对fielddata过滤长尾是一种权衡。
序号标记预加载
假设我们的文档用来标记状态有几种字符串:
- SUCCESS
- FAILED
- PENDING
- WAIT_PAY
状态这类的字段,系统设计时肯定是可以穷举的,如果我们存储到Elasticsearch中也用的是字符串类型,需要的存储空间就会多一些,如果我们换成1,2,3,4这种Byte类型的,就可以节省很多空间。
"序号标记"做的就是这种优化,如果文档特别多(PB级别),那节省的空间就非常可观,我们可以对这类可以穷举的字段设置序号标记,如下请求:
PUT /music/_mapping/children
{
"properties": {
"tags": {
"type": "text",
"fielddata": true,
"eager_global_ordinals": true
}
}
}
深度优先VS广度优先
Elasticsearch的聚合查询时,如果数据量较多且涉及多个条件聚合,会产生大量的bucket,并且需要从这些bucket中挑出符合条件的,那该怎么对这些bucket进行挑选是一个值得考虑的问题,挑选方式好,事半功倍,效率非常高,挑选方式不好,可能OOM,我们拿深度优先和广度优先这两个方式来讲解。
我们举个电影与演员的例子,一部电影由多名演员参与,我们搜索的需求:出演电影最多的10名演员以及他们合作最多的5名演员。
如果是深度优先,示例图如下:
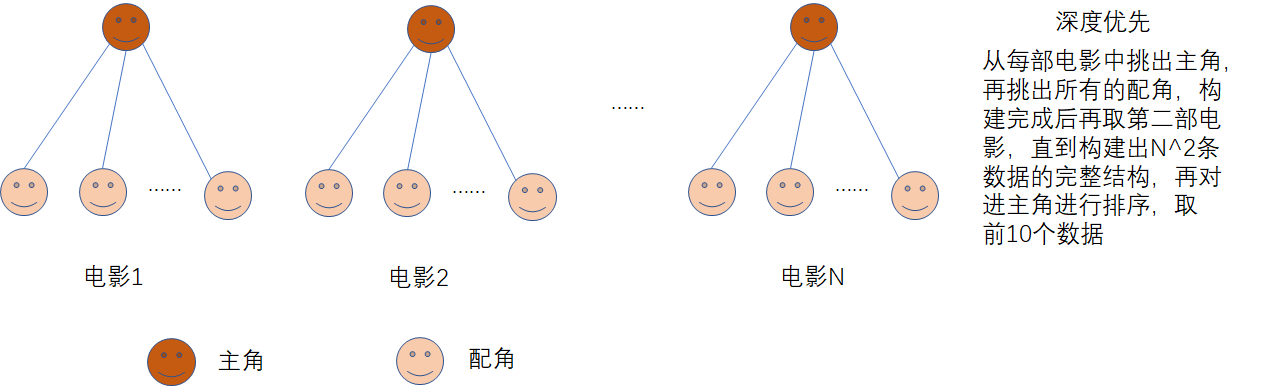
这种查询方式需要构建完整的数据,会消耗大量的内存。假设我们每部电影有10位演员(1主9配),有10万部电影,那么第一层的数据就有10万条,第二层为9*10万=90万条,共100万条数据。
我们对这100万条数据进行排序后,取主角出演次数最多的10个,即10条数据,裁掉99加上与主角合作最多的5名演员,共50条数据。
构建了100万条数据,最终只取50条,内存是不是有点浪费?
如果是广度优先,示例图如下:

这种查询方式先查询电影主角,取前面10条,第一层就只有10条数据,裁掉其他不要的,然后找出跟主角有关联的配角人员,与合作最多的5名,共50条数据。
聚合查询默认是深度优先,设置广度优先只需要设置collect_mode参数为breadth_first,示例:
GET /music/children/_search
{
"size": 0,
"aggs": {
"lang": {
"terms": {
"field": "language",
"collect_mode" : "breadth_first"
},
"aggs": {
"length_avg": {
"avg": {
"field": "length"
}
}
}
}
}
}
注意
使用深度优先还是广度优先,要考虑实际的情况,广度优先仅适用于每个组的聚合数量远远小于当前总组数的情况,比如上面的例子,我只取10位主角,但每部电影都有一位主角,聚合的10位主角组数远远小于总组数,所以是适用的。
另外一组按月统计的柱状图数据,总组数固定只有12个月,但每个月下的数据量特别大,广度优先就不适合了。
所以说,使用哪种方式要看具体的需求。
小结
本篇讲解的聚合查询原理,可以根据实际案例做一些演示,加深一下印象,多阅读一下官网文档,实际工作中这块用到的地方还是比较多的,谢谢。
专注Java高并发、分布式架构,更多技术干货分享与心得,请关注公众号:Java架构社区
可以扫左边二维码添加好友,邀请你加入Java架构社区微信群共同探讨技术


