- 介绍
- 基于SVM对MINIST数据集进行分类
- 使用SVM
- SVM分析垃圾邮件
- 加载数据集
- 分词
- 构建词云
- 构建数据集
- 进行训练
- 交叉验证
- 炼丹术
- 总结
- 参考
介绍
在上一篇博客:数据挖掘入门系列教程(八点五)之SVM介绍以及从零开始公式推导中,详细的讲述了SVM的原理,并进行了详细的数学推导。在这篇博客中,主要是应用SVM,使用SVM进行数据分类,不会涉及到SVM的解释,so,如果对svm并不是特别了解的话,非常建议先去看我的上一篇博客(or其他博主的博客),然后再来看这一篇博客。因为在这篇并不是自己实现SVM而是基于sklearn中的svm包来进行应用。因此,我们可能使用几行代码可能就可以对数据集进行训练了。
我们不仅要知其然,更要知其所以然。
在这一章博客中,我们会使用SVM做两个任务:
- 基于SVM对MINIST数据集进行分类。
- 基于SVM对垃圾邮件进行判断
基于SVM对MINIST数据集进行分类
在前面神经网络的博客中,我们基于pybrain使用神经网络对MINIST手写数据集进行分类,但是最后结果并不是很好(可以说得上是比较差了),只有:

这次我们使用SVM来进行继续操作。数据集在前面的博客中已经进行说明,就不再赘述。
直接看代码吧:
使用SVM
下面的代码没有什么好说的,就是加载下载处理好的数据集,然后在将数据集分割成训练集和测试集(在Github中有这两个数据集,先解压再使用【其中dataset是压缩包,需要解压】):
import numpy as np
X = np.load("./Datahttps://img.qb5200.com/download-x/dataset.npy")
y = np.load("./Data/class.npy")
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(X,y,random_state=14 )
然后我们就可以使用SVM进行训练了:
from sklearn import svm
predictor = svm.SVC(gamma='scale', C=1.0, decision_function_shape='ovr', kernel='rbf')
# 进行训练
predictor.fit(x_train, y_train)
同样关于SVM的官网介绍在这里。关于svm包具体的使用可以看官方文档,官方文档写的还是蛮详细的。
这里来解释一下代码:
svm有很多类型的Estimators如下:

在这里我们选择SVC,也就是说使用SVM进行分类。具体的使用在这里。关于代码中参数的介绍:
-
C = 1.0在上一章博客中,我们提到的软间隔支持向量机中提到了以下公式:
\[\begin{equation}\begin{aligned} \mathcal{L}(\boldsymbol{w}, b, \boldsymbol{\xi}, \boldsymbol{\alpha}, \boldsymbol{\beta}):=& \frac{1}{2} \boldsymbol{w}^{\top} \boldsymbol{w}+C \sum_{i=1}^{m} \xi_{i} \\ &+\sum_{i=1}^{m} \alpha_{i}\left(1-\xi_{i}-y_{i}\left(\boldsymbol{w}^{\top} \boldsymbol{\phi}\left(\boldsymbol{x}_{i}\right)+b\right)\right) \\ &+\sum_{i=1}^{m} \beta_{i}\left(-\xi_{i}\right) \end{aligned}\end{equation} \tag{18} \]其中C就是用来平衡结构风险和经验风险的。
-
kernel='rbf'kernel代表的是核函数,“rbf”代表的就是(高斯)径向基函数核(英语:Radial basis function kernel)表达式如下:
\[\begin{equation}K\left(\mathbf{x}, \mathbf{x}^{\prime}\right)=\exp \left(-\gamma\left\|\mathbf{x}-\mathbf{x}^{\prime}\right\|_{2}^{2}\right)\end{equation} \] -
gamma='scale'在rbf核函数中,我们有一个变量\(\gamma\),
gamma='scale'代表\(\gamma = \frac{1}{(n\_features * X.var()) }\) -
decision_function_shape='ovr'在SVM的介绍中,我们详细的推导过SVM二分类的问题,但是如果类别是多个(大于3),那么怎么办呢?(比如说MINIST数据集中一共有0~9一共十个类别),此时我们可以使用一对一(one vs one),一对多(one vs rest)的方法来解决。
-
ovo
其做法就是在任意两个类样本之间设计一个SVM,因此\(k\)个类别的样本就需要设计\(\frac{k(k-1)}{2}\)个SVM。最后进行预测分类的时候,哪一个类别划分的次数最多,则就判定为该类别。
-
ovr
训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为离超平面最远的那类。
-
fit()就是表示对数据集进行训练。
再然后,我们进行预测并使用F1进行评估:
# 预测结果
result = predictor.predict(x_test)
# 进行评估
from sklearn.metrics import f1_score
print("F-score: {0:.2f}".format(f1_score(result,y_test,average='micro')))
最后结果如下

\(97 \%\),这个结果还是不错的。
本来呢,这篇博客到这里就ok了,怎么使用也介绍完了,但是我觉得这篇博客也太少了点,因此又决定再水一点内容。
SVM分析垃圾邮件
简单点来说,我们就是想通过一封邮件是不是垃圾邮件。一共有1w+1条数据(50001垃圾邮件数据,5k正常邮件的数据)。数据集下载地址:GitHub
部分数据展示如下:

其中每一行数据就是一封邮件。
加载数据集
加载数据集还是挺简单的,代码如下(数据集在我的GitHub中):
# 垃圾邮件文件地址
spam_data_path = "./Data/resource/spam_5000.utf8"
# 正常邮件文件地址
ham_data_path = "./Data/resource/ham_5000.utf8"
with open(spam_data_path,encoding='utf-8') as f:
spam_txt_list = f.readlines()
with open(ham_data_path,encoding="utf-8") as f:
ham_txt_list= f.readlines()
这里还需要介绍一个概念——停止词(百度百科介绍):
人类语言包含很多功能词。与其他词相比,功能词没有什么实际含义。最普遍的功能词是限定词(“the”、“a”、“an”、“that”、和“those”),这些词帮助在文本中描述名词和表达概念,如地点或数量。介词如:“over”,“under”,“above” 等表示两个词的相对位置。
这些功能词的两个特征促使在搜索引擎的文本处理过程中对其特殊对待。第一,这些功能词极其普遍。记录这些词在每一个文档中的数量需要很大的磁盘空间。第二,由于它们的普遍性和功能,这些词很少单独表达文档相关程度的信息。如果在检索过程中考虑每一个词而不是短语,这些功能词基本没有什么帮助。
在信息检索中,这些功能词的另一个名称是:停用词(stopword)。称它们为停用词是因为在文本处理过程中如果遇到它们,则立即停止处理,将其扔掉。将这些词扔掉减少了索引量,增加了检索效率,并且通常都会提高检索的效果。停用词主要包括英文字符、数字、数学字符、标点符号及使用频率特高的单汉字等。
这里我们使用的是百度的停用词表,数据是来自GitHub,当然在我的GitHub上面,已经将这个词表上传上去了。
stop_word_path = "./Data/resource/stopword.txt"
with open(stop_word_path,encoding='utf-8') as f:
# 去除空格以及换行符
stop_words = f.read().strip()
分词
什么是分词呢?对于中文来说,分词就是将连续的一串子序列(句子)分成一个一个的词。比如说”我喜欢你“可以分成”我“,”喜欢“,”你“。实际上在计算机中对中文进行分词还是满困难的。因为有很多歧义,新词等等。这里我们使用jieba库进行分词,举例使用如下:
import jieba
a = "请不要把陌生人的些许善意,视为珍稀的瑰宝,却把身边亲近人的全部付出,当做天经地义的事情,对其视而不见"
cut_a = jieba.cut(a)
print(list(cut_a))
结果如下:

使用jieba对垃圾邮件和正常邮件进行分词代码如下(去除分词中的停词以及部分词):
import jieba
spam_words = []
# 垃圾邮件
for spam_txt in spam_txt_list:
words = []
cut_txts = jieba.cut(spam_txt)
for cut_txt in cut_txts:
# 判断分词是否是字母表组成的,是否是换行符,并且是否在停词表中
if(cut_txt.isalpha() and cut_txt!="\n" and cut_txt not in stop_words):
words.append(cut_txt)
# 将词组成句子
sentence = " ".join(words)
spam_words.append(sentence)
spam_words部分数据结果如下(数据类型为list):

也就是说,我们将每一封垃圾邮件数据分成了一个一个的词(在词的中间使用空格分开),然后组成这一封邮件的词的特征。
同理我们处理正常邮件数据:
import jieba
ham_words = []
for ham_txt in ham_txt_list:
words = []
cut_txts = jieba.cut(ham_txt)
for cut_txt in cut_txts:
if(cut_txt.isalpha() and cut_txt!="\n" and cut_txt not in stop_words):
words.append(cut_txt)
sentence = " ”.join(words)
ham_words.append(sentence)
构建词云
这个没什么好说的,就是使用WordCloud构建词云。text是一个字符串,WordCloud会自动使用空格或者逗号对text进行分割。
%pylab inline
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 词云展示
def showWordCloud(text):
wc = WordCloud(
background_color = "white",
max_words = 200,
# 为了显示中文,使用字体
font_path = "./Data/resource/simhei.ttf",
min_font_size = 15,
max_font_size = 50,
width = 600
)
wordcloud = wc.generate(text)
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
展示垃圾邮件词云我们将数据list变成使用空格连接的字符串。
showWordCloud(" ".join(spam_words))

展示正常邮件数据
showWordCloud(" ".join(ham_words))

构建数据集
通过前面的步骤我们已经得到了邮件进行分词之后的结果。在SVM中我们知道,每一条数据的特征的个数是一样多的(也就是他们拥有相同的特征,但是可能特征值不同),但是很明显对于文本数据,每一封邮件的特征词明显是不一样的。这里我们可以想一想在数据挖掘入门系列教程(七)之朴素贝叶斯进行文本分类中,我们使用了DictVectorizer转换器将特征字典转换成了一个矩阵,这里的数据是list数据,因此我们选择CountVectorizer将list数据转换成举证。
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import numpy as np
from collections import defaultdict
data = []
data.extend(ham_words)
data.extend(spam_words)
# binary默认为False,一个关键词在一篇文档中可能出现n次,如果binary=True,非零的n将全部置为1
# max_features 对所有关键词的出现的频率进行降序排序,只取前max_features个作为关键词集
vectorizer = CountVectorizer(binary=False,max_features=1500)
result = vectorizer.fit_transform(data)
然后我们在加上列对应的名字(非必须,不影响训练):
# 词汇表,为字典类型,key为词汇,value为索引
vocabulary = vectorizer.vocabulary_
result = pd.DataFrame(result.toarray())
# 对索引进行从小到大的排序
colnames = sorted(vocabulary.items(),key = lambda item:item[1])
colname = []
for i in colnames:
colname.append(i[0])
result.columns = colname
最后部分的result的数据如下所示(0代表此词在邮件中没有出现,非0则代表出现):
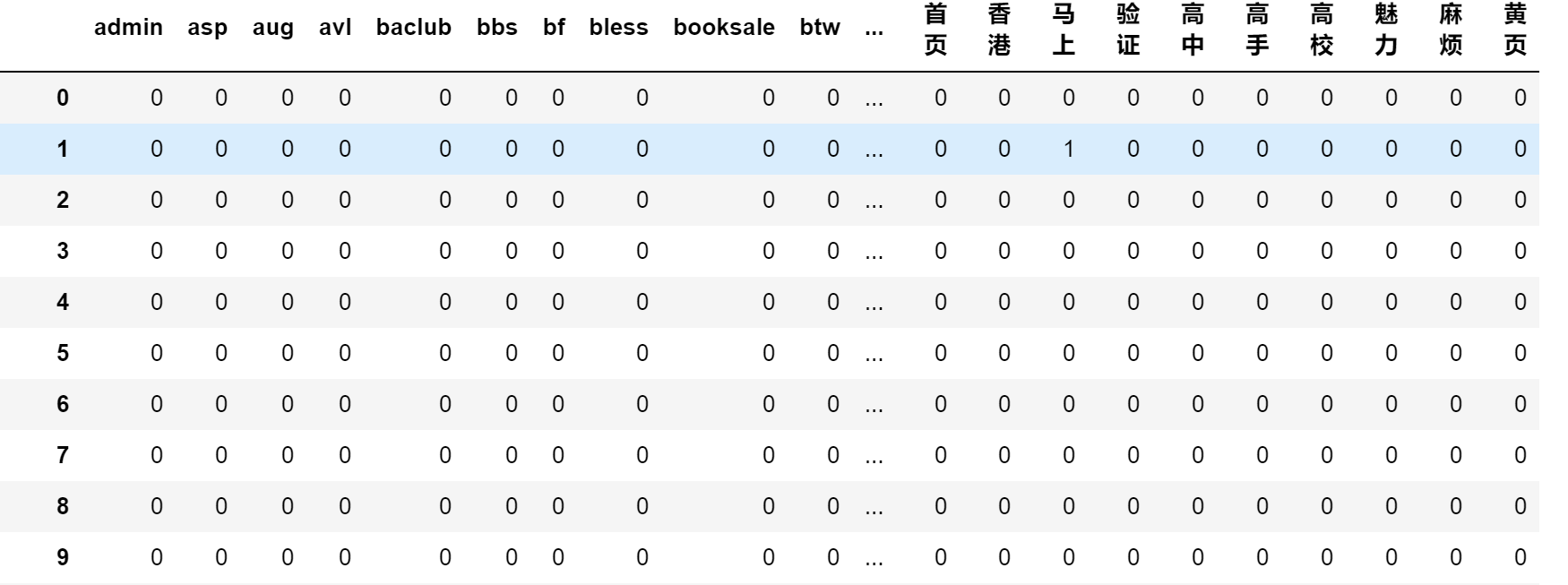
其中index中\([0,5000)\)是正常的邮件数据,\([5000,10001]\)是垃圾邮寄数据。
进行训练
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
# 使用0,1划分垃圾邮件和正常邮件
labels = []
labels.extend(np.ones(5000))
labels.extend(np.zeros(5001))
# 划分训练集和测试集
train,test,trainlabel,testlabel = train_test_split(result,labels,random_state=14)
predictor = SVC(gamma='scale', C=1.0, decision_function_shape='ovr', kernel='rbf')
predictor.fit(train,trainlabel)
predict_lable = predictor.predict(test)
最后进行评估结果为:
print("the accurancy is :",np.mean(predict_lable == testlabel))

交叉验证
当然我们还可以进行交叉验证来进行评估:
from sklearn.model_selection import cross_val_score
predictor = SVC(gamma='scale', C=1.0, decision_function_shape='ovr', kernel='rbf')
scores = cross_val_score(predictor,result,labels,scoring='f1')
print("Score: {}".format(np.mean(scores)))
这个准确度可以说是杠杠的:

炼丹术
继续水一波,来试一下选择不同数量的features,然后再观察不同数量的features对精度的影响。
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
labels = []
labels.extend(np.ones(5000))
labels.extend(np.zeros(5001))
# 画图的两个轴
scores = []
indexs = []
data = []
data.extend(ham_words)
data.extend(spam_words)
for i in range(1,3000,50):
# 转换器
vectorizer = CountVectorizer(binary=False,max_features=i)
result = vectorizer.fit_transform(data)
train,test,trainlabel,testlabel = train_test_split(result,labels,random_state=14)
# 划分训练集和测试集
predictor = SVC(gamma='scale', C=1.0, decision_function_shape='ovr', kernel='rbf')
predictor.fit(train,trainlabel)
score = predictor.score(test,testlabel)
scores.append(score)
indexs.append(i)
然后,画图即可:
plt.plot(indexs,scores)
plt.show()
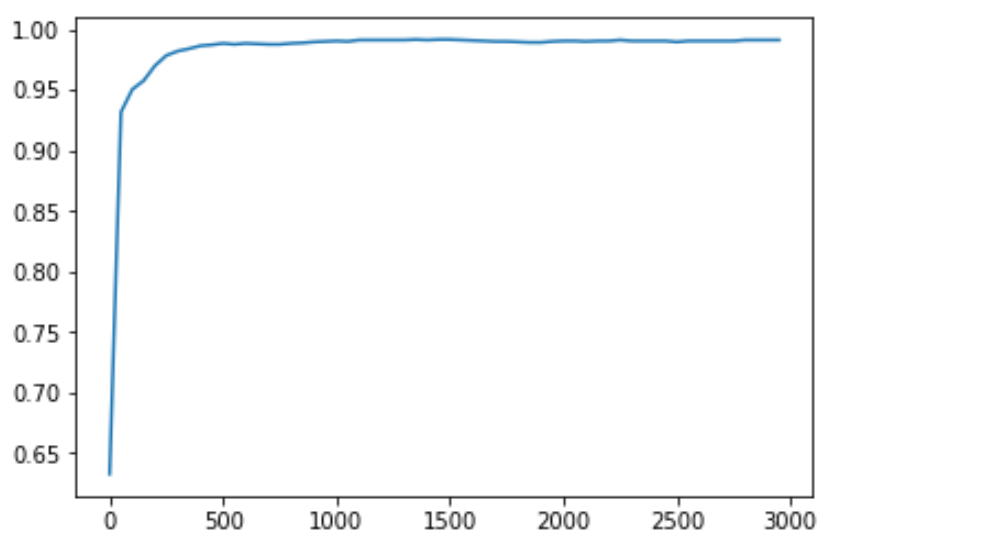
总的来说,结果还不错咯,500个以上的features就可以达到越\(98\%\)以上的精度。
总结
啊,终于水完了!!
这一篇博客主要是介绍基于sklearn的SVM的使用。可以很明显的看到,基本上只需要几行代码就ok了。因此我们更应该去关注svm的原理而不是简单的学会调用包然后就表示:“啊!我会了!SVM真简单”。实际上,如果我们不了解原理的话,我们甚至连调包都不知道里面的参数代表的含义是什么。
项目地址:Github
参考
- wiki:径向基函数核
- SVM实现多分类的三种方案
- sklearn 实现中文数据集的垃圾邮件分类
- 停止词

