在上一篇的文章里我详细介绍了BAM(SAM/CRAM)的格式和一些需要注意的细节,还说了该如何使用samtools在命令行中对其进行操作。但是很多时候这些操作是不能满足我们的实际需要的,比如统计比对率、计算在某个比对质量值之上的read有多少,或者计算PE比对的插入片段长度分布,甚至需要你根据实际情况编写一个新的变异检测算法等。这个时候往往难以直接通过samtools来实现【注】,而是需要编写专门的程序进行计算。因此,在这一篇文章里我们就一起来学习应该如何在程序中借助Pysam来处理BAM文件。
【注】关于统计比对率其实是可以通过samtools stats计算获得的。不过我们这篇文章不是为了争辩samtools能做什么,不能做什么,而是要跟大家讨论该如何编写程序处理BAM。
不过,在开始之前我想稍微再补充一下上一节中提到的CRAM——我习惯将其称为BAM的高压缩格式,因为它和BAM/SAM的格式基本相同,但有四点我们需要注意一下:
CRAM的高压缩是通过借助参考序列和对其他信息的进一步编码来实现的,它相比于BAM有着更高的压缩率,能够节省30%-50%的空间;
CRAM目前的IO效率没有BAM高(压得密嘛),约慢30%,但在不断进步,现在已经更新到了3.x版本了;
CRAM和BAM可以通过samtools或者picard方便地实现互转;
CRAM一定会取代BAM,这话并不是我说的,而是bwa/samtools的作者lh3说的。
什么是Pysam
Pysam是一个专门用来处理(BAM/CRAM/SAM)比对数据和变异数据(VCF和BCF)的Python包。它的核心是htslib——一个高通量数据处理API(来自samtools和bwa的核心,基于C语言),开发者们用Python对它直接进行轻量级包装,因此能够在Python中方便地进行调用,并且保证了它与原生C-API功能上的高度一致。
为什么是Pysam
因为Pysam可以说是最为官方的版本,有比较固定的开发者在维护,它的稳定性和可靠性都很高。虽然还有一些其它的包同样能够处理BAM但其实它们大多绕不开对htslib的使用,但却没有pysam周全。而且Pysam还集成了tabix的接口,所以除了比对数据之外,还能够用于处理所有用tabix构建过索引的文件,总之就是全且可靠。
如果是文本格式的sam的话,其实也可以直接将其当作普通文本文件来处理,不需借助任何程序包(这在早期的数据分析中经常看到这种操作),只是要麻烦很多(必须自己在程序中处理所有细节,包括解析FLAG和CIGAR信息,以前我也干过不少类似的事情),甚至我还看到有人直接在程序中调用samtools view把BAM转换成SAM之后再处理的。。。这样的做法实在不推荐。
所以,只要你用的是Python,那么Pysam真的是目前看来比较好的选择。当然如果你用C/C++那么直接用htslib或者bamtools,如果是Java,那么直接使用htsjdk——htslib的java版本。
如何使用Pysam
首先,要为我们的Python环境安装这个包,如果已安装过的话可以忽略这一步。有两个方法,pip和bioconda,都比较简单,我们这里以pip——Python的包管理工具来进行:
$ pip install pysam
安装完成之后我们就可以在Python程序中调用pysam了。
读取BAM/CRAM/SAM文件
Pysam中的函数有很多,但是重要的读取函数主要有:
等以上几个,其中尤以AlignmentFile和VariantFile为核心。需要我们注意到的地方是,Pysam中的有些函数由于历史原因存在重复,比如名字上只有大小写的差异,但功能却是一样的(比如下图的TabixFile),有些则只是简化了函数名,这些情况用的时候留个心眼就行了。
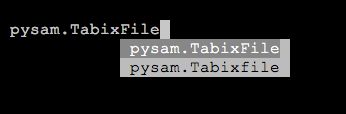
另外,这篇文章的目的是介绍如何处理比对文件,所以我打算只介绍AlignmentFile。
读取比对文件前,我建议先使用samtools index为比对文件构建好索引。当然如果是SAM文件就不必了——它是文本文件,索引的作用是让我们可以对文件进行随机读取,而不必总是从头开始。
下面我先用一个例子作为引子:
import pysam
bf = pysam.AlignmentFile('in.bam', 'rb')
我在这个例子里面,先在程序中导入pysam包,然后调用AlignmentFile函数读取'in.bam'文件,并把句柄赋值给了bf,bf其实是一个迭代器——Python中的术语,意思就是适合在for循环中进行遍历的对象。
这样我们就是可以通过bf获取这份比对文件中的内容了。比如我们想把in.bam中每一条read的比对位置(包含染色体编号和位置信息),比对质量值和插入片段长度输出(我们的in.bam来自PE测序数据的结果),那么可以这样做:
import pysam
bf = pysam.AlignmentFile('in.bam', 'rb')
for r in bf:
print r.reference_name, r.pos, r.mapq, r.isize
是不是很简单!打开in.bam文件之后,用for循环对其从头到尾地遍历,并把每个值都赋给r,r在这里代表的就是比对的read信息,它是一个对象(在Pysam由AlignedSegment定义),通过它就可以获取所有的比对信息,比如上面例子中:
这里例子的结果如下:
chrM 160 50 235
chrM 161 30 -283
chrM 314 60 -207
...
另外,由于bf是一个迭代器,我们其实还可以用bf.next()一个一个地对其进行访问,而不必在for循环中遍历,这在一些特殊的情况下,这个做法是非常有用且方便的。
当然,上面这个例子其实非常简单,实际上r变量中还有很多其它关于比对的信息,下面这个截图,就是变量中能够获取到的所有比对相关的信息,有好几十个。
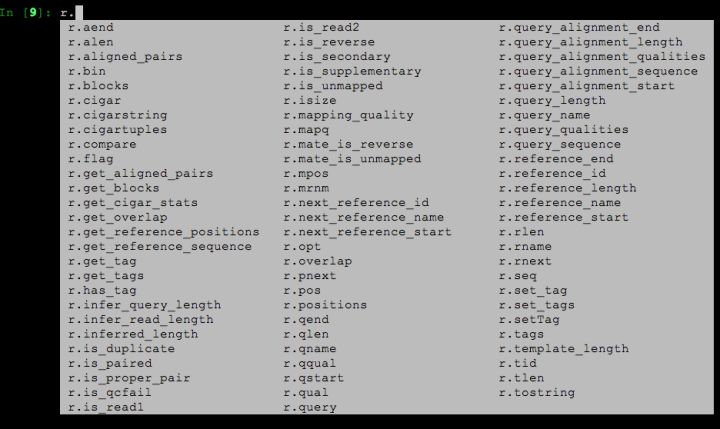
眼尖的同学可能也发现了,这里面存在一些名字类似的变量,如:r.mapping_quality 和 r.mapq,它们其实都是比对质量值。类似的也还有几个,这都是上面我提到的历史原因所致,不过这种多余变量随着Pysam的维护也正在逐步变少。
此外,Pysam中的位点坐标体系是0-base(意思是染色体的起始位置是从0而不是1开始算的)而不是1-base,所以上面的输出的160,其实真实位置应该要+1,也就是161。
还有,上文我也说过,AlignmentFile除了能够读/写BAM之外,还同样能够读/写CRAM和SAM。区别就在于函数中的第二个参数,比如上面例子中的字符'b'就是用于明确指定BAM文件,'r'字符代表“只读”模式(read首字母)。如果要打开CRAM文件,只需要把b换成c(代表CRAM)就行了,如下:
import pysam
cf = pysam.AlignmentFile('in.cram', 'rc')
那么,如果是SAM文件呢?去掉b或c即可:
import pysam
sf = pysam.AlignmentFile('in.sam', 'r')
读取特定比对区域内的数据
有时候我们并不需要遍历整一份BAM文件,我们可能只想获得区中的某一个区域(比如chrM中301-310中的信息),那么这个时候可以用Alignmen模块中的fetch函数:
import pysam
bf = AlignmentFile('in.bam', 'rb')
for r in bf.fetch('chrM', 300, 310):
print r
bf.close()
通过fetch函数就可以定位特定区域了,非常方便。不过,这个时候输入文件in.bam就必须要有索引,不然无法实现这种读取操作。最后用完了,要记得关闭文件(bf.close())。
来个稍微难一点的例子
问题:如何输出覆盖在某个位置上,比对质量值大于30的所有碱基?
这个问题包含两个部分:
如何做呢?这个时候我们要用AlignmentFile模块的另一个函数——pileups来协助解决,代码如下:
import pysam
bf = pysam.AlignmentFile("in.bam", "rb" )
for pileupcolumn in bf.pileup("chrM", 300, 301):
for read in [al for al in pileupcolumn.pileups if al.alignment.mapq>30]:
if not read.is_del and not read.is_refskip:
if read.alignment.pos + 1 == 301:
print read.alignment.reference_name,\
read.alignment.pos + 1,\
read.alignment.query_sequence[read.query_position]
bf.close()
这段代码看起来虽然简单,但其实包含了很多信息。总的来说,就是通过pileup获取了所有覆盖到该位置的read,并将其存到pileupcolumn中。然后,对pileupcolumn调用pileups(注意多了一个s)获得一条read中每个比对位置的信息(一条read那么长,并非只覆盖了一个位置),然后通过判断语句留下覆盖到目标位点(301)的碱基。代码中的read.alignment是Pysam中AlignedSegment对象,它包含的内容和上述其它例子中的r是一样的。read.alignment.pos + 1还是0-base的原因。最后结果如下:
chrM 301 A
chrM 301 A
chrM 301 A
chrM 301 C
chrM 301 C
chrM 301 C
chrM 301 C
chrM 301 C
chrM 301 C
chrM 301 C
...
创建BAM/CRAM/SAM文件
最后这个例子,我想告诉大家该如何用Pysam输出BAM/CRAM/SAM格式,具体还是看代码吧,这里想输出结果是BAM文件,所以输出模式是“wb”,例子中我们只输出一条比对结果作为说明。
import pysam
header = {'HD': {'VN': '1.0'},
'SQ': [{'LN': 1575, 'SN': 'chr1'},
{'LN': 1584, 'SN': 'chr2'}]
}
tmpfilename = "out.bam"
with pysam.AlignmentFile(tmpfilename, "wb", header=header) as outf:
a = pysam.AlignedSegment() # 定义一个AlignedSegment对象用于存储比对信息
a.query_name = "read_28833_29006_6945"
a.query_sequence="AGCTTAGCTAGCTACCTATATCTTGGTCTTGGCCG"
a.flag = 99
a.reference_id = 0
a.reference_start = 32
a.mapping_quality = 20
a.cigar = ((0,10), (2,1), (0,25))
a.next_reference_id = 0
a.next_reference_start=199
a.template_length=167
a.query_qualities = pysam.qualitystring_to_array("<<<<<<<<<<<<<<<<<<<<<:<9/,&,22;;<<<")
a.tags = (("NM", 1),
("RG", "L1"))
outf.write(a)
小结
我写这篇文章的目的主要有两个:第一,充实上一篇文章中关于如何操作BAM的内容;第二,介绍Pysam这一个值得使用的包给大家。另外,我上面列举的例子其实都比较偏于基础操作,这可能和我自身对认知的看法有关。我一直认为,只有真正理解并灵活地应用基础操作,才可以灵活地解决一切复杂的问题。
而且,上面几个例子中用到的模块和函数其实都是比较常用的,所以我比较推荐优先掌握它们。这些例子里面用到的数据我已放到github了,感兴趣的同学可以在公众号后台回复“WGS”即可获得,后续也会陆续有其它的代码和数据可供参考。
最后,Pysam的内容其实还有很多,我所介绍的也仅在对于比对数据的处理,其它很多的模块和函数,包括对Fasta,Fastq,VCF,BCF和Tabix文件的处理,我就不进行一一介绍了,建议大家在使用的时候多看看它的完整文档。
以上所述是小编给大家介绍的使用Python处理BAM的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!

