前言
Elastic-Job是ddframe中dd-job的作业模块中分离出来的分布式弹性作业框架。去掉了和dd-job中的监控和ddframe接入规范部分。该项目基于成熟的开源产品Quartz和Zookeeper及其客户端Curator进行二次开发。 ddframe其他模块也有可独立开源的部分,之前当当曾开源过dd-soa的基石模块DubboX。 项目开源地址:https://github.com/dangdangdotcom/elastic-job
Elastic-Job是ddframe中dd-job的作业模块中分离出来的分布式弹性作业框架。去掉了和dd-job中的监控和ddframe接入规范部分。该项目基于成熟的开源产品Quartz和Zookeeper及其客户端Curator进行二次开发。
项目开源地址
ddframe其他模块也有可独立开源的部分,之前当当曾开源过dd-soa的基石模块DubboX。
elastic-job和ddframe关系见下图
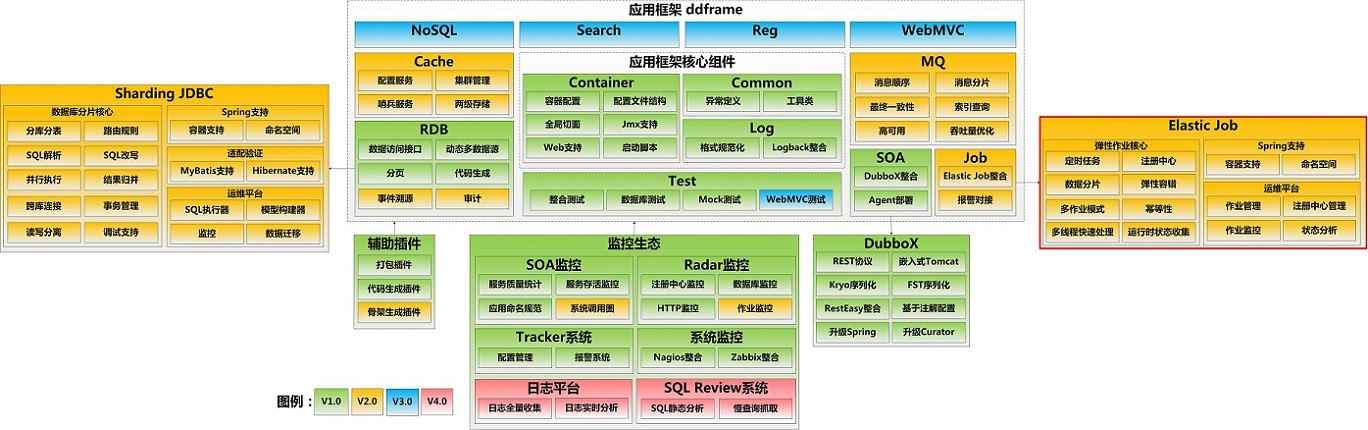
Elastic-Job主要功能
目录结构说明
elastic-job核心模块,只通过Quartz和Curator就可执行分布式作业。
elastic-job对spring支持的模块,包括命名空间,依赖注入,占位符等。
elastic-job web控制台,可将编译之后的war放入tomcat等servlet容器中使用。
使用例子。
测试elastic-job使用的公用类,使用方无需关注。
引入maven依赖
elastic-job已经发布到中央仓库,可以在pom.xml文件中直接引入maven坐标。
<!-- 引入elastic-job核心模块 --> <dependency> <groupId>com.dangdang</groupId> <artifactId>elastic-job-core</artifactId> <version>1.0.1</version> </dependency> <!-- 使用springframework自定义命名空间时引入 --> <dependency> <groupId>com.dangdang</groupId> <artifactId>elastic-job-spring</artifactId> <version>1.0.1</version> </dependency>
代码开发
提供3种作业类型,分别是OneOff, Perpetual和SequencePerpetual。需要继承相应的抽象类。
方法参数shardingContext包含作业配置,分片和运行时信息。可通过getShardingTotalCount(),getShardingItems()等方法分别获取分片总数,运行在本作业服务器的分片序列号集合等。
OneOff作业类型比较简单,需要继承AbstractOneOffElasticJob,该类只提供了一个方法用于覆盖,此方法将被定时执行。用于执行普通的定时任务,与Quartz原生接口相似,只是增加了弹性扩缩容和分片等功能。
public class MyElasticJob extends AbstractOneOffElasticJob {
@Override
protected void process(JobExecutionMultipleShardingContext context) {
// do something by sharding items
}
}
Perpetual作业类型略为复杂,需要继承AbstractPerpetualElasticJob并可以指定返回值泛型,该类提供两个方法可覆盖,分别用于抓取和处理数据。可以获取数据处理成功失败次数等辅助监控信息。
需要注意fetchData方法的返回值只有为null或长度为空时,作业才会停止执行,否则作业会一直运行下去。这点是参照TbSchedule的设计。Perpetual作业类型更适用于流式不间歇的数据处理。
作业执行时会将fetchData的数据传递给processData处理,其中processData得到的数据是通过多线程(线程池大小可配)拆分的。
建议processData处理数据后,更新其状态,避免fetchData再次抓取到,从而使得作业永远不会停止。processData的返回值用于表示数据是否处理成功,抛出异常或者返回false将会在统计信息中归入失败次数,返回true则归入成功次数。
public class MyElasticJob extends AbstractPerpetualElasticJob<Foo> {
@Override
protected List<Foo> fetchData(JobExecutionMultipleShardingContext context) {
List<Foo> result = // get data from database by sharding items
return result;
}
@Override
protected boolean processData(JobExecutionMultipleShardingContext context, Foo data) {
// process data
return true;
}
}
SequencePerpetual作业类型和Perpetual作业类型极为相似,所不同的是Perpetual作业类型可以将获取到的数据多线程处理,但不会保证多线程处理数据的顺序。
如:从2个分片共获取到100条数据,第1个分片40条,第2个分片60条,配置为两个线程处理,则第1个线程处理前50条数据,第2个线程处理后50条数据,无视分片项;SequencePerpetual类型作业则根据当前服务器所分配的分片项数量进行多线程处理,每个分片项使用同一线程处理,防止了同一分片的数据被多线程处理,从而导致的顺序问题。
如:从2个分片共获取到100条数据,第1个分片40条,第2个分片60条,则系统自动分配两个线程处理,第1个线程处理第1个分片的40条数据,第2个线程处理第2个分片的60条数据。由于Perpetual作业可以使用多余分片项的任意线程数处理,所以性能调优的可能会优于SequencePerpetual作业。
public class MyElasticJob extends AbstractSequencePerpetualElasticJob<Foo> {
@Override
protected List<Foo> fetchData(JobExecutionSingleShardingContext context) {
List<Foo> result = // get data from database by sharding items
return result;
}
@Override
protected boolean processData(JobExecutionSingleShardingContext context, Foo data) {
// process data
return true;
}
}
作业配置
与Spring容器配合使用作业,可以将作业Bean配置为Spring Bean, 可在作业中通过依赖注入使用Spring容器管理的数据源等对象。可用placeholder占位符从属性文件中取值。
Spring命名空间配置
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:reg="http://www.dangdang.com/schema/ddframe/reg" xmlns:job="http://www.dangdang.com/schema/ddframe/job" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.dangdang.com/schema/ddframe/reg http://www.dangdang.com/schema/ddframe/reg/reg.xsd http://www.dangdang.com/schema/ddframe/job http://www.dangdang.com/schema/ddframe/job/job.xsd "> <!--配置作业注册中心 --> <reg:zookeeper id="regCenter" serverLists=" yourhost:2181" namespace="dd-job" baseSleepTimeMilliseconds="1000" maxSleepTimeMilliseconds="3000" maxRetries="3" /> <!-- 配置作业A--> <job:bean id="oneOffElasticJob" class="xxx.MyOneOffElasticJob" regCenter="regCenter" cron="0/10 * * * * ?" shardingTotalCount="3" shardingItemParameters="0=A,1=B,2=C" /> <!-- 配置作业B--> <job:bean id="perpetualElasticJob" class="xxx.MyPerpetualElasticJob" regCenter="regCenter" cron="0/10 * * * * ?" shardingTotalCount="3" shardingItemParameters="0=A,1=B,2=C" processCountIntervalSeconds="10" concurrentDataProcessThreadCount="10" /> </beans>
<job:bean />命名空间属性详细说明
<reg:zookeeper />命名空间属性详细说明
基于Spring但不使用命名空间
<!-- 配置作业注册中心 -->
<bean id="regCenter" class="com.dangdang.ddframe.reg.zookeeper.ZookeeperRegistryCenter" init-method="init">
<constructor-arg>
<bean class="com.dangdang.ddframe.reg.zookeeper.ZookeeperConfiguration">
<property name="serverLists" value="${xxx}" />
<property name="namespace" value="${xxx}" />
<property name="baseSleepTimeMilliseconds" value="${xxx}" />
<property name="maxSleepTimeMilliseconds" value="${xxx}" />
<property name="maxRetries" value="${xxx}" />
</bean>
</constructor-arg>
</bean> <!-- 配置作业-->
<bean id="xxxJob" class="com.dangdang.ddframe.job.spring.schedule.SpringJobController" init-method="init">
<constructor-arg ref="regCenter" />
<constructor-arg>
<bean class="com.dangdang.ddframe.job.api.JobConfiguration">
<constructor-arg name="jobName" value="xxxJob" />
<constructor-arg name="jobClass" value="xxxDemoJob" />
<constructor-arg name="shardingTotalCount" value="10" />
<constructor-arg name="cron" value="0/10 * * * * ?" />
<property name="shardingItemParameters" value="${xxx}" />
</bean>
</constructor-arg>
</bean>
不使用Spring配置
如果不使用Spring框架,可以用如下方式启动作业。
import com.dangdang.ddframe.job.api.JobConfiguration;
import com.dangdang.ddframe.job.schedule.JobController;
import com.dangdang.ddframe.reg.base.CoordinatorRegistryCenter;
import com.dangdang.ddframe.reg.zookeeper.ZookeeperConfiguration;
import com.dangdang.ddframe.reg.zookeeper.ZookeeperRegistryCenter;
import com.dangdang.example.elasticjob.core.job.OneOffElasticDemoJob;
import com.dangdang.example.elasticjob.core.job.PerpetualElasticDemoJob;
import com.dangdang.example.elasticjob.core.job.SequencePerpetualElasticDemoJob;
public class JobDemo {
// 定义Zookeeper注册中心配置对象
private ZookeeperConfiguration zkConfig = new ZookeeperConfiguration("localhost:2181", "elastic-job-example", 1000, 3000, 3);
// 定义Zookeeper注册中心
private CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(zkConfig);
// 定义作业1配置对象
private JobConfiguration jobConfig1 = new JobConfiguration("oneOffElasticDemoJob", OneOffElasticDemoJob.class, 10, "0/5 * * * * ?");
// 定义作业2配置对象
private JobConfiguration jobConfig2 = new JobConfiguration("perpetualElasticDemoJob", PerpetualElasticDemoJob.class, 10, "0/5 * * * * ?");
// 定义作业3配置对象
private JobConfiguration jobConfig3 = new JobConfiguration("sequencePerpetualElasticDemoJob", SequencePerpetualElasticDemoJob.class, 10, "0/5 * * * * ?");
public static void main(final String[] args) {
new JobDemo().init();
}
private void init() {
// 连接注册中心
regCenter.init();
// 启动作业1
new JobController(regCenter, jobConfig1).init();
// 启动作业2
new JobController(regCenter, jobConfig2).init();
// 启动作业3
new JobController(regCenter, jobConfig3).init();
}
}
使用限制
实现原理
弹性分布式实现
第一台服务器上线触发主服务器选举。主服务器一旦下线,则重新触发选举,选举过程中阻塞,只有主服务器选举完成,才会执行其他任务。
某作业服务器上线时会自动将服务器信息注册到注册中心,下线时会自动更新服务器状态。
主节点选举,服务器上下线,分片总数变更均更新重新分片标记。
定时任务触发时,如需重新分片,则通过主服务器分片,分片过程中阻塞,分片结束后才可执行任务。如分片过程中主服务器下线,则先选举主服务器,再分片。
通过4可知,为了维持作业运行时的稳定性,运行过程中只会标记分片状态,不会重新分片。分片仅可能发生在下次任务触发前。
每次分片都会按服务器IP排序,保证分片结果不会产生较大波动。
实现失效转移功能,在某台服务器执行完毕后主动抓取未分配的分片,并且在某台服务器下线后主动寻找可用的服务器执行任务。

流程图
作业启动

作业执行

运维平台
elastic-job运维平台以war包形式提供,可自行部署到tomcat或jetty等支持servlet的web容器中。elastic-job-console.war可以通过编译源码或从maven中央仓库获取。
登录
默认用户名和密码是root/root,可以通过修改conf\auth.properties文件修改默认登录用户名和密码。
主要功能
设计理念
运维平台和elastic-job并无直接关系,是通过读取作业注册中心数据展现作业状态,或更新注册中心数据修改全局配置。
控制台只能控制作业本身是否运行,但不能控制作业进程的启停,因为控制台和作业本身服务器是完全分布式的,控制台并不能控制作业服务器。
不支持项
添加作业。因为作业都是在首次运行时自动添加,使用运维平台添加作业并无必要。
停止作业。即使删除了Zookeeper信息也不能真正停止作业的运行,还会导致运行中的作业出问题。
删除作业服务器。由于直接删除服务器节点风险较大,暂时不考虑在运维平台增加此功能。
主要界面
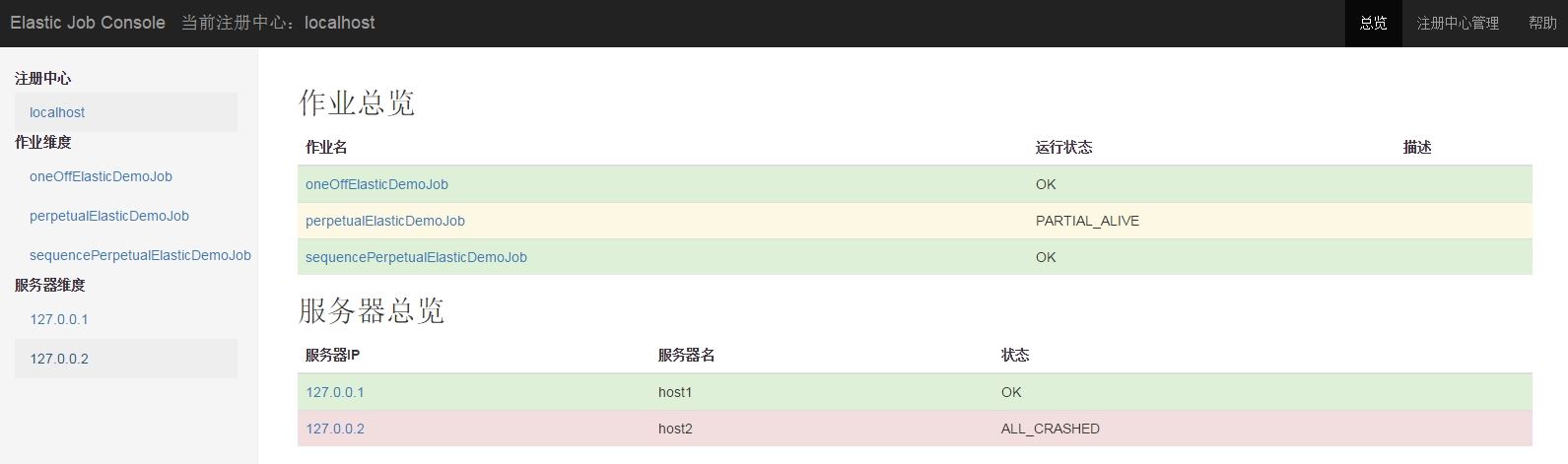
总览页
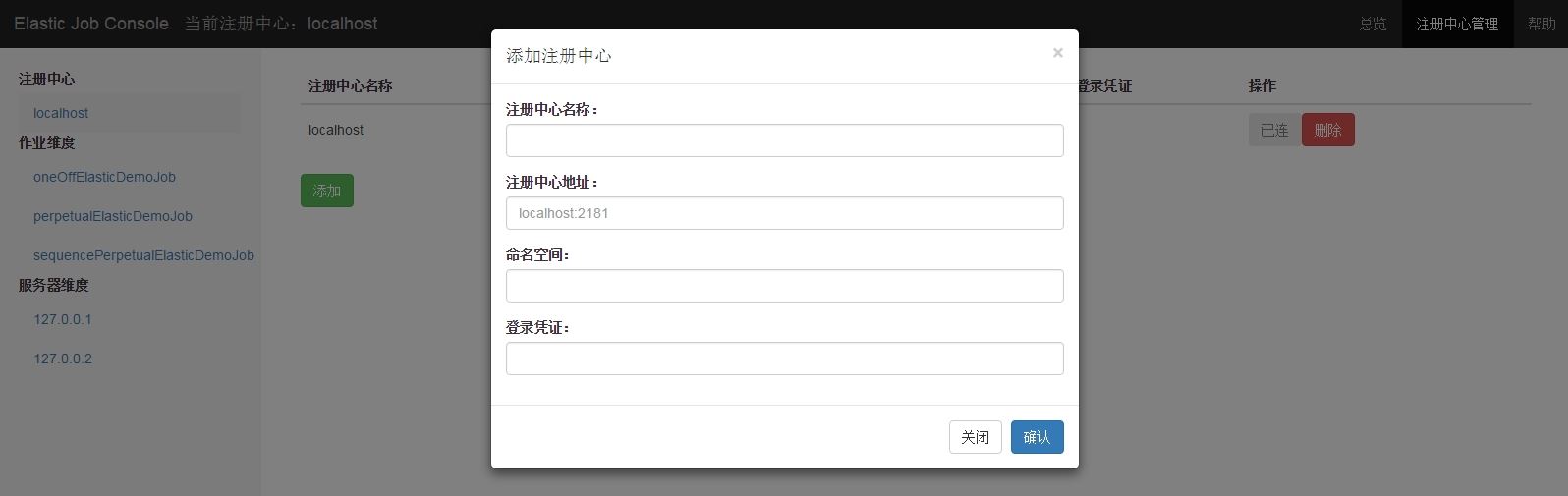
注册中心管理页
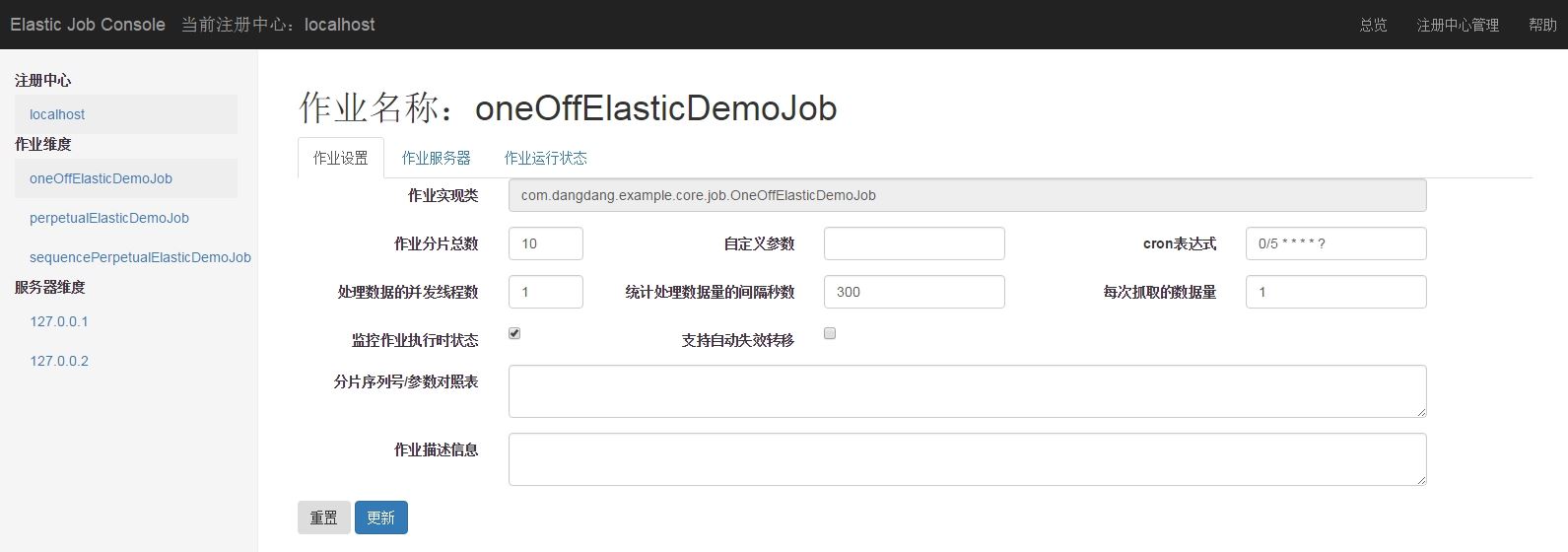
作业详细信息页
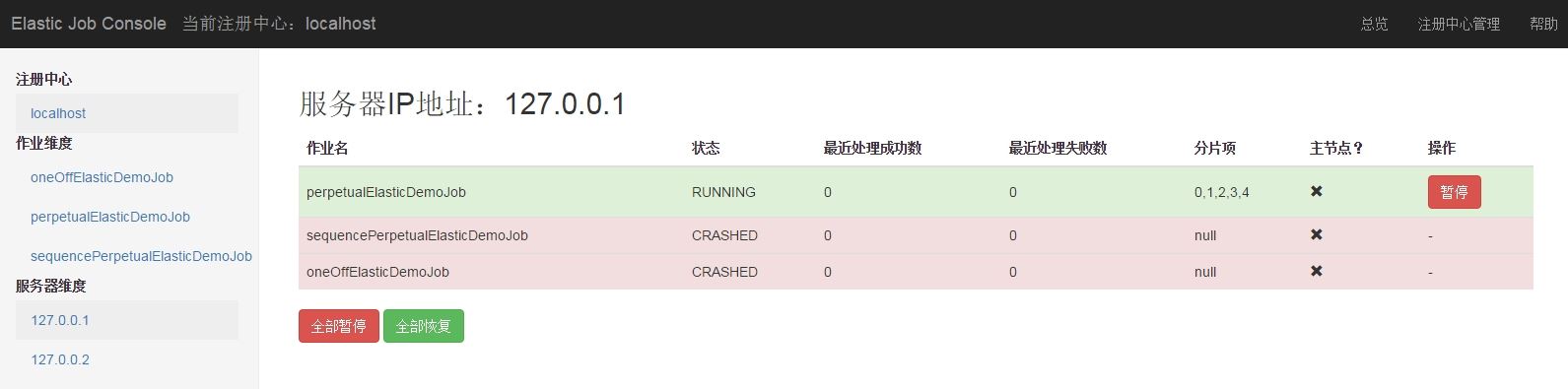
服务区详细信息页
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。

