对python3下的requests使用并不是很熟练,今天稍微用了下,请求几次下来后发现出现连接超时的异常,上网查了下,找到了一个还算中肯的解决方法。
retrying是python的一个自带的重试包
from retrying import retry
retrying 这个包的用法原理就是在你不知道那段代码块是否会发生异常,若发生异常,可以再次执行该段的代码块,如果没有发生异常,那么就继续执行往下执行代码块
以前你的代码可能是这样写的:
def get_html(url): pass def log_error(url): pass url = "" try: get_page(url) except: log_error(url)
也有可能是这样子写的:
# 请求超过十次就放弃 attempts = 0 success = False while attempts < 10 and not success: try: get_html(url) success = True except: attempts += 1 if attempts == 10: break
使用 retrying 的写法:
import random
from retrying import retry
@retry()
def do_something_unreliable():
if random.randint(0, 10) > 1:
raise IOError("Broken sauce, everything is hosed!!!111one")
else:
return "Awesome sauce!"
result = do_something_unreliable()
print(result)
上面的是简单的用法,你可以试下,下面是一些可选参数的使用方式。
stop_max_attempt_number
用来设定最大的尝试次数,超过该次数就停止重试
stop_max_delay
超过时间段,函数就不会再执行了
wait_random_min和wait_random_max
用随机的方式产生两次retrying之间的停留时间
补充:python中Requests的重试机制
import requests
from requests.adapters import HTTPAdapter
s = requests.Session()
# 重试次数为3
s.mount('http://', HTTPAdapter(max_retries=3))
s.mount('https://', HTTPAdapter(max_retries=3))
# 超时时间为5s
s.get('http://example.com', timeout=5)
在wiki当中对指数退避算法的介绍是:
In a variety of computer networks, binary exponential backoff or truncated binary exponential backoff refers to an algorithm used to space out repeated retransmissions of the same block of data, often as part of network congestion avoidance.
翻译成中文的意思大概是“在各种的计算机网络中,二进制指数后退或是截断的二进制指数后退使用于一种隔离同一数据块重复传输的算法,常常做为网络避免冲突的一部分”
比如说在我们的服务调用过程中发生了调用失败,系统要对失败的资源进行重试,那么这个重试的时间如何把握,使用指数退避算法我们可以在某一范围内随机对失败的资源发起重试,并且随着失败次数的增加长,重试时间也会随着指数的增加而增加。
当然,指数退避算法并没有人上面说的那么简单,想具体了解的可以具体wiki上的介绍
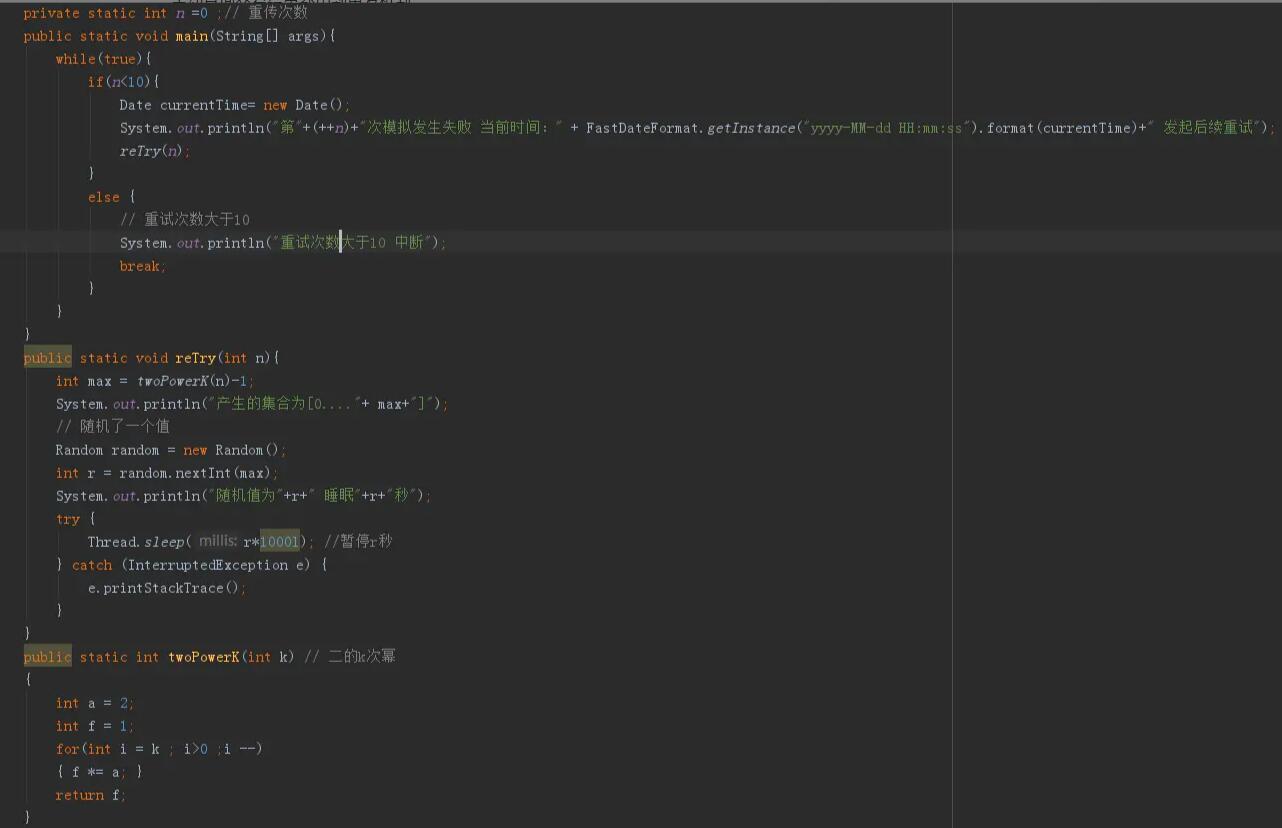
当系统每次调用失败的时候,我们都会产生一个新的集合,集合的内容是0~2n-1,n代表调用失败的次数
第一次失败 集合为 0,1
第二次失败 集合为 0,1,2,3
第三次失败 集合为 0,1,2,3,4,5,6,7
在集合中随机选出一个值记为R,下次重试时间就是R*基本退避时间(对应在指数退避算法中争用期) 当然,为了防止系统无限的重试下去,我们会指数重新的最大次数
使用指数退避算法,可以防止连续的失败,从某方面讲也可以减轻失败服务的压力,试想一下,如果一个服务提供者的服务在某一时间发生了异常、超时或是网络抖动,那么频繁的重试所得到的结果也大致都是失败。这样的频繁的重试不仅没有效果,反而还会增服务的负担。
接入三方支付服务,在三方支付提供的接入接口规范中,服务方交易结束结果通知和商户主动查询交易结果都用到重发机制
在app应用中,很多场景会遇到轮询一类的问题,轮询对于app性能和电量的消耗都过大。

以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。

