需要转载的小伙伴转载后请注明转载的地址
需要用到的库
365好书链接:http://www.365haoshu.com/ 爬取《我以月夜寄相思》小说
首页进入到目录:http://www.365haoshu.com/Book/Chapter/List.aspx?NovelId=3026
获取小说的每个章节的名称和章节链接
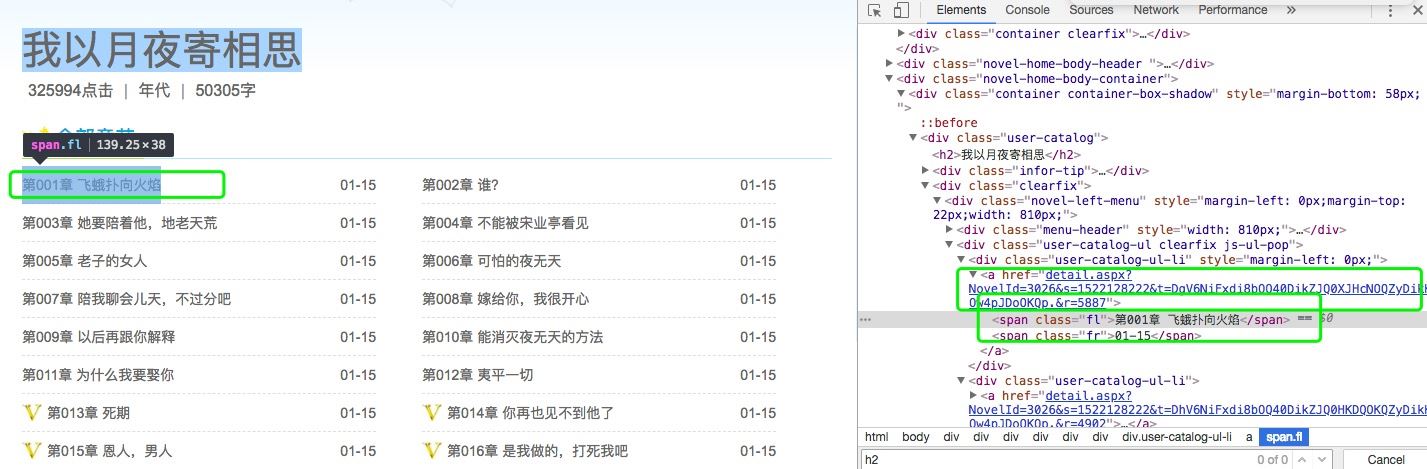
打开浏览器的开发者工具,查找一个章节:如下图,找到第一章的名称和href(也就是第一章节内容页面的链接),开始写代码
from bs4 import BeautifulSoup
import requests
import time
# 分别导入time、requests、BeautifulSoup库
url = 'http://www.365haoshu.com/Book/Chapter/'
# 链接地址url,这儿url章节链接没全写出来是因为下面获取章节链接时要用到这些url
req = requests.get(url+'List.aspx?NovelId=0326')
# 打开章节页面,
req_bf = BeautifulSoup(req.text,"html.parser")
print(req_bf)
# 将打开的页面以text打印出来
div = req_bf.find_all('div',class_='user-catalog-ul-li')
# 分析页面,所需要的章节名和章节链接是在div标签,属性class为user-catalog-ul-li下
# 找到这个下的内容,并打印
s = []
for d in div:
s.append(d.find('a'))
print(s)
# 获取div下面的a标签下的内容
names=[] # 存储章节名
hrefs=[] # 存储章节链接
for i in s:
names.append(i.find('span').string)
hrefs.append(url + i.get('href'))
# 将所有的章节和章节链接存入的列表中
观察href后的链接和打开章节内容页面的链接是不完全的相同的, 所以要拼接使得浏览器能直接打开章节内容
获取到链接和章节名后打开一个章节获取文本内容;
和获取章节名方法一致,一步一步查找到内容的位置
txt = requests.get(hrefs[0])
div_bf = BeautifulSoup(txt.text,'html.parser')
div = div_bf.find_all('div',class_='container user-reading-online pos-rel')
#print(div)
ps = BeautifulSoup(str(div),"html.parser")
p=ps.find_all('p',class_='p-content')
print(p)
txt=[]
for i in p:
txt.append(i.string+'\n')
print(txt)
获取单一章节完成
接下来整理代码,获取整个小说的内容,代码如下:
# --*-- coding=utf-8 --*--
from bs4 import BeautifulSoup
import requests
import time
class spiderstory(object):
def __init__(self): # 初始化
self.url = 'http://www.365haoshu.com/Book/Chapter/'
self.names = [] # 存放章节名
self.hrefs = [] # 存放章节链接
def get_urlAndName(self):
'''获取章节名和章节链接'''
req = requests.get(url=self.url+'List.aspx?NovelId=0326') # 获取章节目录页面
time.sleep(1) # 等待1秒
div_bf = BeautifulSoup(req.text,"html.parser") # req后面跟text和html都行
div = div_bf.find_all('div', class_='user-catalog-ul-li') # 查找内容,标签为div,属性为class='user-catalog-ul-li'
a_bf = BeautifulSoup(str(div))
a = a_bf.find_all('a') # # 查找内容,标签为a
for i in a:
self.names.append(i.find('span').string) # 获取内容直接string就行
self.hrefs.append(self.url + i.get('href')) # 获取链接
def get_text(self,url):
'''获取章节内容'''
req = requests.get(url=url)
div_bf = BeautifulSoup(req.text,"html.parser")
div = div_bf.find_all('div', class_='container user-reading-online pos-rel') # 查找内容
ps = BeautifulSoup(str(div), "html.parser")
p = ps.find_all('p', class_='p-content')
text = []
for each in p:
text.append(each.string)
print(text)
return text # 将获得的内容返回
def writer(self, name, path, text):
'''写入text文档中'''
with open(path, 'a', encoding='utf-8') as f:
f.write(name + '\n')
f.writelines(text)
f.write('\n\n')
if __name__ == "__main__": # 运行入口
s = spiderstory()
s.get_urlAndName()
le = len(s.names)
for i in range(le): # 利用for循环获得所有的内容
name = s.names[i]
text = str(s.get_text(s.hrefs[i]))
s.writer(name,"我以月夜寄相思.txt",text)
print('下载完毕!!!')

