因为最近在复习yolo系列的算法,就借着这个机会总结一下自己对这个算法的理解,由于是第一次写算法类的博客,文中有什么错误和行文不通的地方还希望大家指正。
yolov2与yolov1有很多改变。
最重要的改动:引入了anchor机制。v1通过最后接一个全连接层直接输出bbox的坐标。在yolov2中参考了fast-rcnn中的先验框机制,通过卷积层来学习anchor的offsets避免了全连接层。为了试应anchor这一操作,作者在网络中移除了一个池化层,来获得更高的网络输出,并且为了得到奇数个grid cell,将网络的的输入分辨率从448转为416.yolo网络降采样32倍,所以最后输出是13x13. 在引入了anchor机制后,每一个anchor都生成类别与空间的预测,而不是yolov1中每一个grid cell生成一个Bx5+C的预测,这一点的引入加强了yolo对密集小目标的检测。在加入anchor后一张图从原来生成98个boxes改为生成上千个anchor boxes。这样做网络的Accuracy有所下降,但是recall召回率得到了显著的提升,因为目前在自动驾驶行业工作,联想到特斯拉之前在高速高速公路上把正样本识别成负样本所以在我看来自动驾驶中的目标检测召回率是要比准确率更重要的一个指标。
使用k-means聚类得出anchor。在距离时如果修正函数选择的还是欧氏距离的话,就会产生那个很经典的问题,大的目标框会比小目标框产生更大的error。所以为了使聚类时的distance不受框的大小影响,作者使用的一种新的距离计算方式: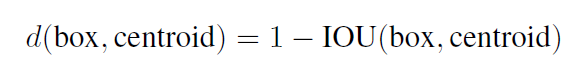
这一操作有效的提高了最后结果的avg IOU,在自动驾驶的视觉方面,最后检测框的位置精度很大程度上会影响测距的精度。
对于 location predict输出内容的修改:对比RPN结构,RPN输出的是对anchor box的偏移量,这导致在模型训练初期会有很多bbox出现在图像的任意位置,这导致了训练初期模型的不稳定性,就是的训练需要更长的时间达到收敛。yolov2使用了对grid cell的偏移量来作为最后结果的输出,这使得与ground truth的差别落在了0和1直接,并在后面使用了sigmoid作为激活函数来限制输出。
最后网络输出5个值 tx ty tw th 和to,其中tx ty是之前介绍过的对于grid cell的偏移量,tw和th是对预测框的宽高和anchor的修正值。to是和yolov1一样是判定是否在grid cell中有物体并计算iou。最后输出预测框结果如下:
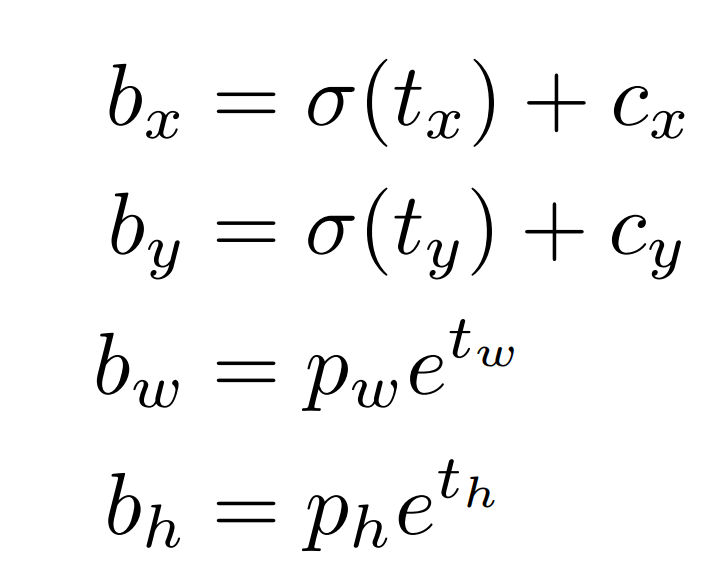
其中Cx和Cy是产生这个bbox的grid cell对于图像左上角的偏移量。pw和ph是anchor的宽和高。

使用了更细颗粒化的特征图:yolov2没有像ssd那样使用多尺度的特征图来产生anchor去使用不同大小的物体。而实使用了passthrough层来结合之前的26x26的特征图来讲最后的head部分特征图更finer-grained。
动态调整输入图片大小:由于yolov2的主干网络只使用了卷积层和池化层,这使得网络可以动态的调整特征图大小。为了使算法在不同分辨率上的图片表现的更好,在训练阶段,作者采用的了每10个batch就改变一下输入图像的尺度,因为网络的降采样是32倍,所以输入也都是32的倍数,从308到608.
backbone方面的改变:
YOLOV2中作者提出了自己的网络Darknet-19,而不是像v1中在googLEnet上做修改。正如绝大多数目标检测算法的backbone一样,darknet是一个分类网络,它把最后的全连接层换成了global average pooling层再接softmax层。整个网络只有卷积层和池化层,所以可以对输入灵活修改。下图为darknet的网络结构:
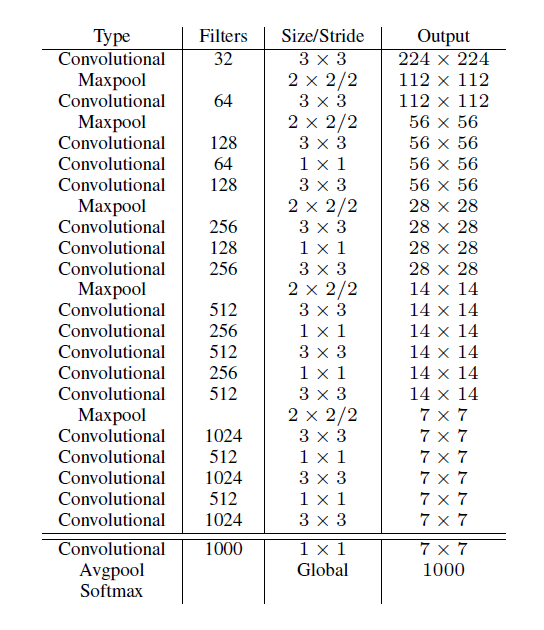
yolov2在每一个卷积层后都加入了BN层,在加入bn层后移除了训练中dropout的操作
yolov2在分类数据集ImageNet上预训练模型时直接使用了448x448分辨率的网络输入。在yolov1中预训练模型时输入的分辨率是224x224,在检测时才把分辨率转换成448x448
整个网络使用了19个卷积层和5个池化层。目前深度学习的网络设计思路就是加深加多参数,然后再去解决过拟合问题。

