static class Node<K,V> implements Map.Entry<K,V> {
// hash值
final int hash;
// key
final K key;
// value
volatile V val;
// 后驱节点
volatile Node<K,V> next;
....
}
// 负载因子:表示散列表的填满程度~ 在ConcurrentHashMap中,该属性是固定值0.75,不可修改~
private static final float LOAD_FACTOR = 0.75f;
或者说,Node 节点的 hash 值有几种情况?针对不同情况分析一下?
Node.hash = -1,表示当前节点是 **FWD(ForWardingNode) **节点(表示已经被迁移的节点)。Node.hash = -2,表示当前节点已经树化,且当前节点为 TreeBin 对象,TreeBin 对象代理操作红黑树。Node.hash > 0,表示当前节点是正常的 Node 节点,可能是链表,或者单个 Node。sizeCtr 即 Size Control,这个字段一定要仔细去理解一下,这个字段看不懂,可能会整个 ConcurrentHashMap 源码都一脸懵逼。
izeCtl == 0,是默认值,表示在真正第一次初始化散链表的时候使用默认容量 16 进行初始化。sizeCtl == -1表示当前散链表正处于初始化状态。有线程正在对当前散列表(table) 进行初始化操作。sizeCtl == -1 就相当于一个"标识锁",防止多个线程去初始化散列表。initTable()方法中,会通过 CAS 的方式去修改 sizeCtl 的值为 -1,表示已经有线程正在对散链表进行初始化,其他线程不可以再次初始化,只能等待!// SIZECTL:期望值,初始为0 // this 就表示当前 ConcurrentHashMap对象 // sc 表示要修改的 sizeCtrl // -1 表示将 sc 修改为 -1 U.compareAndSwapInt(this, SIZECTL, sc, -1);
sizeCtl = -1 操作成功的线程,可以接着执行对散链表初始化的逻辑。而 CAS 修改失败的线程,在这里会不断的自旋检查,直到散链表初始化结束。Thread.yield();方法,短暂释放 CPU 资源,把 CPU 资源让给更饥饿的线程去使用。目的是为了减轻自旋对CPU 性能的消耗。sizeCtl > 0 时,表示初始化或扩容完成后下一次触发扩容的阈值。比如,sizeCtl = 12 时,当散链表中数据的个数 >=12 时,就会触发扩容操作。-(1 + nThreads),表示有n个线程正在一起扩容。这时候,sizeCtl 的高 16 位表示扩容标识戳,低 16 位表示参与并发扩容线程数:1 + nThread, 即当前参与并发扩容的线程数量为 n 个。tab.length 去获取扩容唯一标识戳。
// 固定值16,与扩容相关,计算扩容时会根据该属性值生成一个扩容标识戳
private static int RESIZE_STAMP_BITS = 16;
/**
* table数组扩容时,计算出一个扩容标识戳,当需要并发扩容时,当前线程必须拿到扩容标识戳才能参与扩容:
*/
static final int resizeStamp(int n) {
// RESIZE_STAMP_BITS:固定值16,与扩容相关,计算扩容时会根据该属性值生成一个扩容标识戳
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
sizeCtl < 0 && sizeCtl != -1 时,这时候sizeCtl 的高 16 位就表示扩容标识戳,低 16 位表示参与并发扩容线程数:1 + nThread, 即当前参与并发扩容的线程数量为 n 个。这个问题其实就是问,向 ConcurrentHashMap 中添加数据确保线程安全是如何实现的。
添加数据具体流程如下:
ConcurrentHashMap 的寻址算法和 HashMap 差别不大:
/**
* 计算Node节点hash值的算法:参数h为hash值
* eg:
* h二进制为 --> 1100 0011 1010 0101 0001 1100 0001 1110
* (h >>> 16) --> 0000 0000 0000 0000 1100 0011 1010 0101
* (h ^ (h >>> 16)) --> 1100 0011 1010 0101 1101 1111 1011 1011
* 注:(h ^ (h >>> 16)) 目的是让h的高16位也参与寻址计算,使得到的hash值更分散,减少hash冲突产生~
* ------------------------------------------------------------------------------
* HASH_BITS --> 0111 1111 1111 1111 1111 1111 1111 1111
* (h ^ (h >>> 16)) --> 1100 0011 1010 0101 1101 1111 1011 1011
* (h ^ (h >>> 16)) & HASH_BITS --> 0100 0011 1010 0101 1101 1111 1011 1011
* 注: (h ^ (h >>> 16))得到的结果再& HASH_BITS,目的是为了让得到的hash值结果始终是一个正数
*/
static final int spread(int h) {
// 让原来的hash值异或^原来hash值的右移16位,再与&上HASH_BITS(0x7fffffff: 二进制为31个1)
return (h ^ (h >>> 16)) & HASH_BITS;
}
index = (tab.length -1) & hash 获得桶位下标。ConcurrentHashMap 统计存储数据的数量是通过 addCount(long x, int check) 方法实现的,本质上是借助了 LongAdder 原子类。
ConcurrentHashMap为什么不采用 ConcurrentHashMap为什么不采用 AtomicLong 统计散列表数据量呢?统计散列表数据量呢?
那么 LongAdder 是如何保证大并发量下,性能依旧高效呢?
先看下LongAdder的操作原理图:

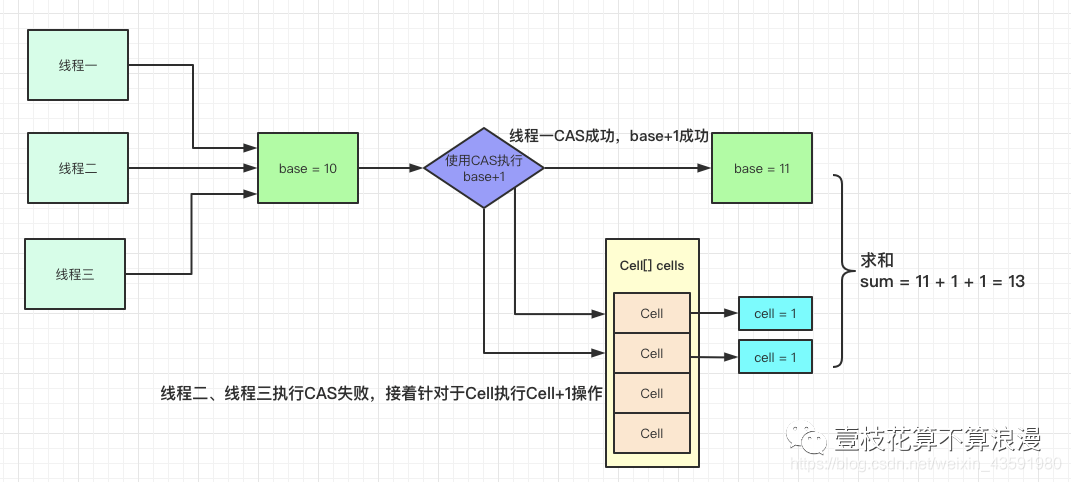
LongAdder采用"分段"的方式降低CAS失败的频次,典型的用空间换时间:
LongAdder有一个全局变量volatile long base;值,当并发不高的情况下都是通过CAS来直接操作base值,如果CAS失败,则针对LongAdder中的Cell[]数组中的Cell进行CAS操作,减少失败的概率。如当前类中base = 10,有三个线程进行CAS原子性的 加1操作,线程一执行成功,此时base=11,线程二、线程三执行失败后开始针对于Cell[]数组中的Cell元素进行加1操作,同样也是CAS操作,此时数组index=1和index=2中Cell的value都被设置为了1。
执行完成后,统计累加数据:sum = 11 + 1 + 1 = 13,利用LongAdder进行累加的操作就执行完了,流程图如下:
transferIndex 字段,用于记录旧散链表数据的总迁移进度!迁移工作进度是从 高位桶开始,一直迁移到下标是 0 的桶位。 ForwardingNode 对象表示桶内节点,这种 Node 比较特殊,是用来表示当前桶中的数据已经被迁移到新散链表的桶中去了。ForwardingNode 有哪些作用?
find() 方法重新定向到新散链表中去查询目标元素!这里要分两种情况考虑:
sizeCtl的低 16 位,即让低 16 位 +1,说明又加入一个新的线程去执行扩容。sizeCtl的低 16 位,即让低 16 位 -1,说明有一个线程退出并发扩容了。 sizeCtl 低 16 位-1后的值为 1,则说明当前线程是最后一个退出并发扩容的线程。写线程会被阻塞,因为红黑树比较特殊,新写入数据,可能会触发红黑树的自平衡,这就会导致树的结构发生变化,会影响读线程的读取结果!
在红黑树上读取数据和写入数据是互斥的,具体原理分析如下:
ConcurrentHashMap 中的红黑树由 TreeBin 来代理,TreeBin 内部有一个 Int 类型的 state 字段。park()挂起当前线程,使其等待被唤醒。挂起写线程时,写线程会先将 state 值的第 2 个 bit 位设置为 1(二进制为 10),转换成十进制就是 2,表示有写线程等待被唤醒。反过来,当红黑树上有写线程正在执行写入操作,那么如果有新的读线程请求该怎么处理?
state 值 -4。unsafe.unpark() 方法去唤醒该写线程。文章会不定时更新,有时候一天多更新几篇,如果帮助您复习巩固了知识点,后续会亿点点的更新!希望大家多多关注的其他内容!

