又到了吹水时间,是这样的,今天开发时想将自己写好的代码拿来优化,因为不想在开发服弄,怕搞坏了到时候GIT到生产服一大堆问题,然后把它分离到我轮子(工具)项目上,最后运行后发现我获取List的时候很卡至少10秒,我惊了平时也就我的正常版本是800ms左右(不要看它很久,因为数据量很大,也很正常。),前提是我也知道很慢,就等的确需要优化时,我在放出我优化的plus版本,回到10秒哪里,最开始我刚刚接到这个app项目时,在我用 PageHelper.startPage(page, num);(分页),还没等查到的数据封装(PageInfo)就已经分好页了,现在换到轮子上就发现了这个问题,它没有帮我将limit拼接到sql后面,导致我获取全部,再PageInfo分页,数据量庞大导致很卡,最后…
10秒:

正常的:
分页拦截实际上就是获取sql后将sql拼接limit
pom.xml
<!-- 引入分页插件 -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.2.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
</dependency>
yml
spring:
application:
name: spring-cloud-dynamic
datasource:
#类型
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/f2f?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: root
password:
initial-size: 2
max-idle: 10
min-idle: 1
max-wait: 60000
max-active: 20 #最大空闲连接数
#多久进行一次检测,检测需要关闭的空闲连接
time-between-eviction-tuns-millis: 60000
MybatisConfig
/**
* @author lanys
* @Description:
* @date 23/7/2021 下午8:38
*/
@Configuration
@EnableTransactionManagement
@PropertySource(value = "classpath:application.yml", ignoreResourceNotFound = true)
public class MybatisConfig implements TransactionManagementConfigurer {
@Value("${mybatis.mapper-locations}")
private String mapper;
@Value("${mybatis.type-aliases-package}")
private String aliases;
@Autowired
private DataSource dataSource;
@Bean(name = "sqlSessionFactory")
public SqlSessionFactory sqlSessionFactory() throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
// 设置数据源
bean.setDataSource(dataSource);
// 设置xml
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources(mapper));
// 设置别名
bean.setTypeAliasesPackage(aliases);
// 添加分页插件
bean.setPlugins(new Interceptor[]{pageInterceptor()});
bean.getObject().getConfiguration().setMapUnderscoreToCamelCase(true);
return bean.getObject();
}
/**
* 分页拦截器
* @return
*/
private PageInterceptor pageInterceptor() {
PageInterceptor pageInterceptor = new PageInterceptor();
// 详见 com.github.pagehelper.page.PageParams
Properties p = new Properties();
// RowBounds是否进行count查询 - 默认不查询
p.setProperty("rowBoundsWithCount", "true");
// 当设置为true的时候,如果page size设置为0(或RowBounds的limit=0),就不执行分页,返回全部结果
p.setProperty("pageSizeZero", "true");
// 分页合理化
p.setProperty("reasonable", "false");
// 是否支持接口参数来传递分页参数,默认false
p.setProperty("supportMethodsArguments", "true");
// 设置数据库方言 , 也可以不设置,会动态获取
p.setProperty("helperDialect", "mysql");
pageInterceptor.setProperties(p);
return pageInterceptor;
}
@Override
public PlatformTransactionManager annotationDrivenTransactionManager() {
return new DataSourceTransactionManager(dataSource);
}
}
测试
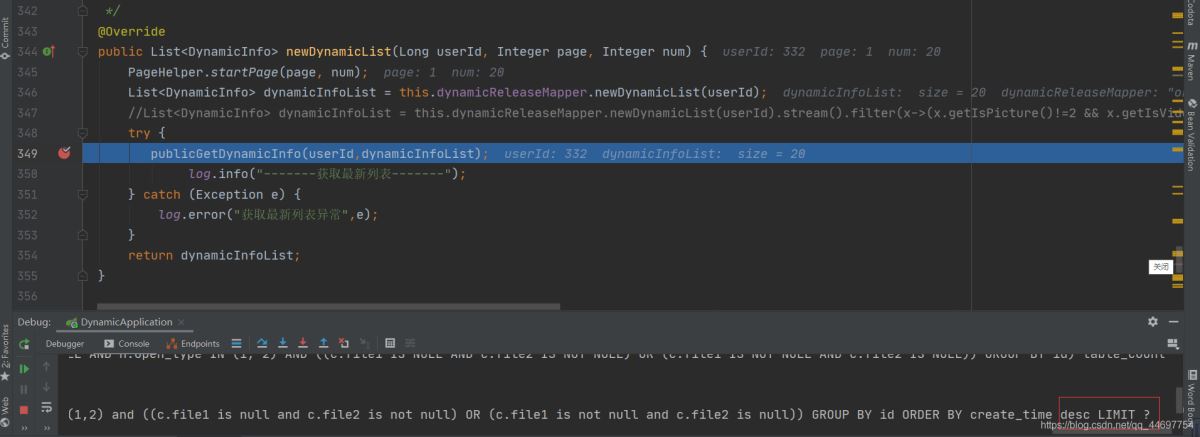
自己的其中代码
/**
* 关注列表
* @param userId
* @param page
* @param size
* @return
*/
@Override
public List<DynamicInfo> focusList(Long userId, Integer page, Integer size) {
PageHelper.startPage(page, size);
List<DynamicInfo> listByUserId = new ArrayList<>();
try {
//获取自己关注列表
listByUserId = this.dynamicReleaseMapper.getListFocusId(userId);
if (listByUserId == null || listByUserId.size() == 0){
return listByUserId;
}
//List<DynamicInfo> listByUserId = this.dynamicReleaseMapper.getListFocusId(userId).stream().filter(x->(x.getIsPicture()!=2 && x.getIsVideo() !=2)||(x.getIsPicture()==2 && x.getIsVideo() !=2)||(x.getIsPicture()!=2 && x.getIsVideo() ==2)).collect(Collectors.toList());
publicGetDynamicInfo(userId,listByUserId);
//}
log.info("-------获取关注列表-------");
return listByUserId;
} catch (Exception e) {
log.error("获取关注列表异常",e);
}
return listByUserId;
}
想分页要加 PageHelper.startPage(page, size);,否则会默认不分页,也可以自己加limit.
结果(sql语句很长截取一部分):
GROUP BY id ORDER BY create_time desc LIMIT ?
这代码是最后发现不对后,问公司大佬才懂,瞬间学到了,可能有人会问,这有什么好处吗?
优点(自己的想法):
1. 直接在数据库过滤,少了很多处理。为什么?因为如果你先查出全部在进行封装分页,看不出什么问题。但是如果你直接获取后,还要其他处理,比如一个动态,你要获取最新的动态,动态需要图片,视频,标签,地址等,这一系列获取,如果获取到的动态很少还好,如果很多,那个速度自己都觉得可怕(慢)。
2. 运行速度快很多,在开发中,尽量减少访问数据库来获取数据。
3. 省事,有些是在sql后面自己加limit,但是sql语句很多时,也很繁琐
缺点:
看个人需求,看合不合适

