文档对象模型 (DOM) 会将 web 页面与到脚本或编程语言连接起来。DOM模型表示具有逻辑树的文档。树的每个分支的终点都是一个节点(node),每个节点都包含着对象(objects)。DOM的方法(methods)允许以编程方式进行访问树,从而改变文档的结构,样式和内容。节点可以关联上事件处理器,一旦某一事件被触发了,那些事件处理器就会被执行。
从网络传给渲染引擎的 HTML 文件字节流是无法直接被渲染引擎理解的,所以要将其转化为渲染引擎能够理解的内部结构,这个结构就是 DOM。DOM 提供了对 HTML 文档结构化的表述。在渲染引擎中,DOM 有三个层面的作用
简言之,DOM 是表述 HTML 的内部数据结构,它会将 Web 页面和 JavaScript 脚本连接起来,并过滤一些不安全的内容
DOM 并不是一个编程语言,但如果没有DOM, JavaScript 语言也不会有任何网页,XML页面以及涉及到的元素的概念或模型。在文档中的每个元素— 包括整个文档,文档头部, 文档中的表格,表头,表格中的文本 — 都是文档所属于的文档对象模型(DOM)的一部分,因此它们可以使用DOM和一个脚本语言如 JavaScript,来访问和处理。
起初,JavaScript和DOM是交织在一起的,但它们最终演变成了两个独立的实体。JavaScript可以访问和操作存储在DOM中的内容,因此我们可以写成这个近似的等式:
API (web 或 XML 页面) = DOM + JS (脚本语言)
在渲染引擎内部,有一个叫HTML 解析器(HTMLParser)的模块,它的职责就是负责将 HTML 字节流转换为 DOM 结构。
HTML 解析器并不是等整个文档加载完成之后再解析的,而是随着 HTML 文档边加载边解析的,是网络进程加载了多少数据,HTML 解析器便解析多少数据。
流程:网络进程接收到响应头之后,会根据响应头中的 content-type 字段来判断文件的类型,比如 content-type 的值是“text/html”,那么浏览器就会判断这是一个 HTML 类型的文件,根据这个判断选择相应的解析引擎,然后为该请求选择或者创建一个渲染进程。渲染进程准备好之后,网络进程和渲染进程之间会建立一个共享数据的管道,网络进程接收到数据后就往这个管道里面放,而渲染进程则从管道的另外一端不断地读取数据,并同时将读取的数据传送给 HTML 解析器。
可以把这个管道想象成一个“水管”,网络进程接收到的字节流像水一样倒进这个“水管”,而“水管”的另外一端是渲染进程的 HTML 解析器,它会动态接收字节流,并将其解析为 DOM。
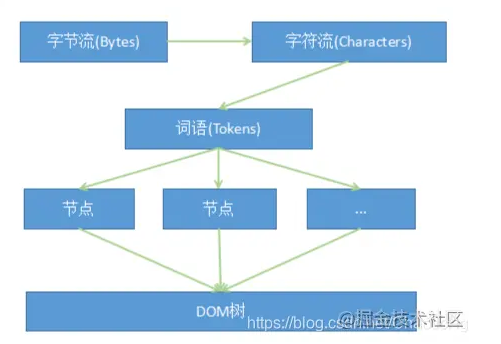
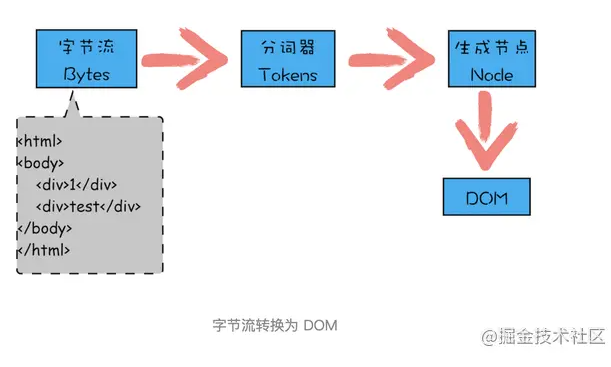
从图中可以看出,字节流转换为 DOM 需要三个阶段。
第一个阶段,通过分词器将字节流转换为 Token。
解析 HTML 也是一样的,需要通过分词器先将字节流转换为一个个 Token,分为 Tag Token 和文本 Token。将 HTML 代码通过词法分析生成的 Token 如下图所示:

由图可知,Tag Token 又分 StartTag 和 EndTag。
第二阶段是将 Token 解析为 DOM 节点
HTML 解析器维护了一个Token 栈结构,该 Token 栈主要用来计算节点之间的父子关系,在第一个阶段中生成的 Token 会被按照顺序压到这个栈中。具体的处理规则如下所示:
通过分词器产生的新 Token 就这样不停地压栈和出栈,整个解析过程就这样一直持续下去,直到分词器将所有字节流分词完成。
第三阶段是将 DOM 节点添加到 DOM 树中
将创建的 DOM 节点,添加到 document 上,形成 DOM 树。
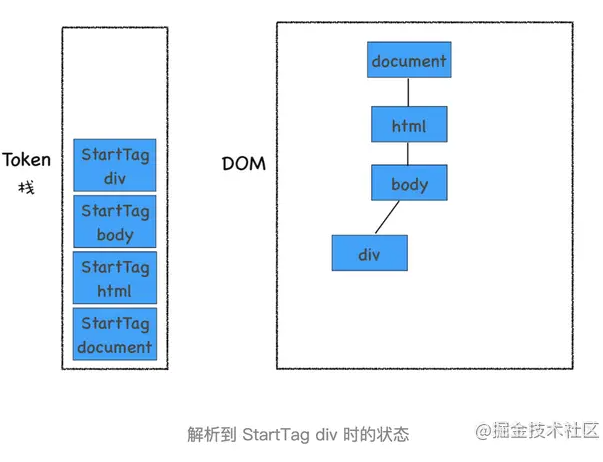
HTML 解析器开始工作时,会默认创建了一个根为 document 的空 DOM 结构,同时会将一个 StartTag document 的 Token 压入栈底。然后经过分词器解析出来的第一个 StartTag html Token 会被压入到栈中,并创建一个 html 的 DOM 节点,添加到 document 上,如下图所示

然后按照同样的流程解析出来 StartTag body 和 StartTag div,其 Token 栈和 DOM 的状态如下图所示:
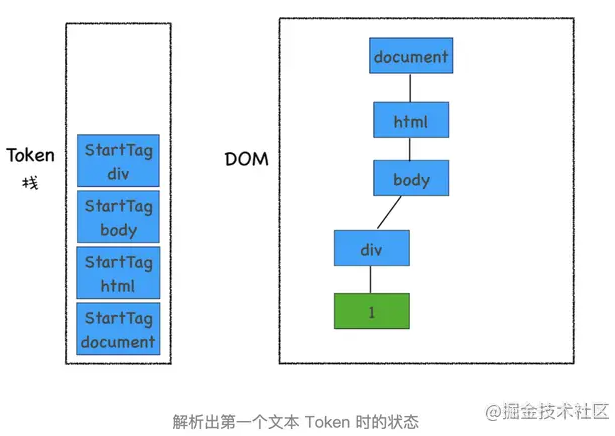
接下来解析出来的是第一个 div 的文本 Token,渲染引擎会为该 Token 创建一个文本节点,并将该 Token 添加到 DOM 中,它的父节点就是当前 Token 栈顶元素对应的节点,如下图所示:
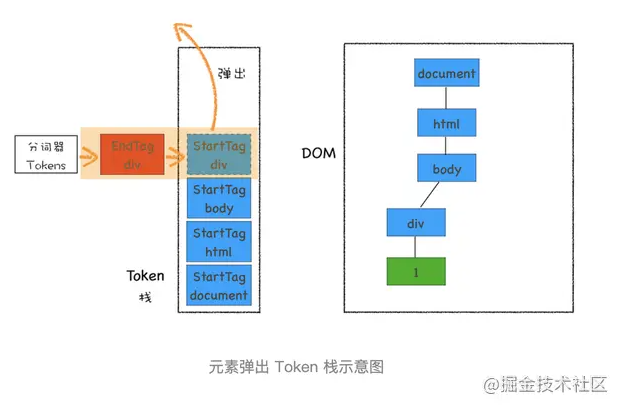
再接下来,分词器解析出来第一个 EndTag div,这时候 HTML 解析器会去判断当前栈顶的元素是否是 StartTag div,如果是则从栈顶弹出 StartTag div,如下图所示
按照同样的规则,一路解析,最终结果如下图所示:
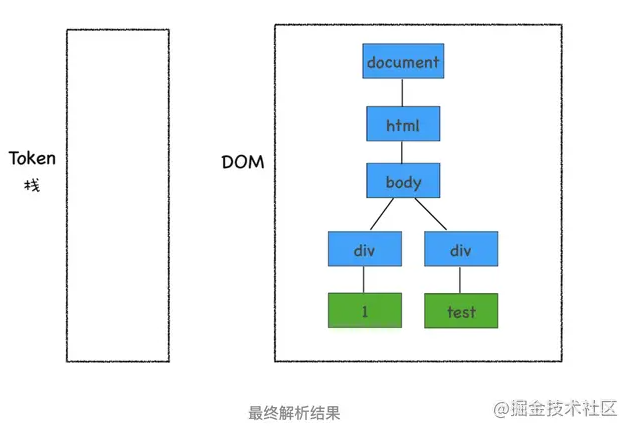
通过上面的介绍,相信你已经清楚 DOM 是怎么生成的了。不过在实际生产环境中,HTML 源文件中既包含 CSS 和 JavaScript,又包含图片、音频、视频等文件,所以处理过程远比上面这个 Demo 复杂。不过理解了这个简单的 Demo 生成过程,我们就可以往下分析更加复杂的场景了。
如果页面中含有一段 JavaScript 脚本,或者引入了脚本文件,则这段脚本的解析过程就与上面的过程有点不一样了。
script标签之前,所有的解析流程还是和之前介绍的一样,但是解析到script标签时,渲染引擎判断这是一段脚本,此时 HTML 解析器就会暂停 DOM 的解析,JavaScript 引擎介入,因为 JavaScript 脚本可能要修改当前已经生成的 DOM 结构。
如果脚本是通过 JavaScript 文件加载的,则需要先下载这段 JavaScript 代码。这里需要重点关注下载环境,因为JavaScript 文件的下载过程会阻塞 DOM 解析,而通常下载又是非常耗时的,会受到网络环境、JavaScript 文件大小等因素的影响。
如果脚本是直接内嵌的 JavaScript 脚本,则直接执行。
如果 JavaScript 脚本修改了 DOM 中的 div 中的内容,所以执行这段脚本之后,已经解析过的 div 节点内容也会被修改。脚本执行完成之后,HTML 解析器恢复解析过程,继续解析后续的内容,直至生成最终的 DOM。
还有一种情况则是,如果 JavaScript 代码出现了,修改页面 CSS 样式的语句,用来操纵 CSSOM ,所以在执行 JavaScript 之前,需要先解析 JavaScript 语句之上所有的 CSS 样式。所以如果代码里引用了外部的 CSS 文件,那么在执行 JavaScript 之前,还需要等待外部的 CSS 文件下载完成,并解析生成 CSSOM 对象之后,才能执行 JavaScript 脚本。
而 JavaScript 引擎在解析 JavaScript 代码之前,是不知道 JavaScript 是否操纵了 CSSOM 的,所以渲染引擎在遇到 JavaScript 脚本时,不管该脚本是否操纵了 CSSOM,都会执行 CSS 文件下载,解析操作,再执行 JavaScript 脚本。所以说 JavaScript 脚本是依赖样式表的。
通过上面的分析,我们知道了 JavaScript 会阻塞 DOM 生成,而样式文件又会阻塞 JavaScript 的执行,所以在实际的工程中需要重点关注 JavaScript 文件和样式表文件,使用不当会影响到页面性能的。
为防止页面阻塞,Chrome 浏览器做了很多优化,其中一个主要的优化是预解析操作。当渲染引擎收到字节流之后,会开启一个预解析线程,用来分析 HTML 文件中包含的 JavaScript、CSS 等相关文件,解析到相关文件之后,预解析线程会提前下载这些文件。
再回到 DOM 解析上,我们知道引入 JavaScript 线程会阻塞 DOM,不过也有一些相关的策略来规避,比如使用 CDN 来加速 JavaScript 文件的加载,压缩 JavaScript 文件的体积。另外,如果 JavaScript 文件中没有操作 DOM 相关代码,就可以将该 JavaScript 脚本设置为异步加载,通过 async 或 defer 来标记代码,使用方式如下所示:
<script async type="text/javascript" src='foo.js'></script>
<script defer type="text/javascript" src='foo.js'></script>
async 和 defer 虽然都是异步的,不过还有一些差异,使用 async 标志的脚本文件一旦加载完成,会立即执行;而使用了 defer 标记的脚本文件,需要在 DOMContentLoaded 事件之前执行。
首先我们介绍了 DOM 是如何生成的,然后又基于 DOM 的生成过程分析了 JavaScript 是如何影响到 DOM 生成的。也谈到 CSS 和 JavaScript 都会影响到 DOM 的生成。
DOM生成的过程
解析 HTML 需要通过分词器先将字节流转换为 Token。
如果压入到栈中的是StartTag Token,HTML 解析器会为该 Token 创建一个 DOM 节点,然后将该节点加入到 DOM 树中。如果分词器解析出来是文本 Token,那么会生成一个文本节点,然后将该节点加入到 DOM 树中。如果分词器解析出来的是EndTag 标签,HTML 解析器会查看 Token 栈顶的元素是否是 StarTag div,如果是,就将 StartTag div 从栈中弹出,表示该 div 元素解析完成。
通过分词器产生的新 Token 就这样不停地压栈和出栈,整个解析过程就这样一直持续下去,直到分词器将所有字节流分词完成。
在解析过程中如果遇到 JavaScript 代码,则停止 HTML 解析,如果js通过脚本加载的则先下载该脚本再执行,再执行之前 CSS 也会被解析生成 CSSOM。经此过程直至整个 DOM 构建完成。

