本章内容包括:
和C语言一样,C++允许甚至鼓励程序员将组件放在独立的文件中。可以单独编译这些文件,然后将它们连接成可执行程序。(通常,C++编译器即编译程序,也管理连接器)。如果只修改了一个文件,则可以只重新编译该文件,然后将它与其他文件的编译版本链接。这使得大程序的管理更便捷。
C++开发人员使用 #include 导入头文件,与其将结构声明加入到每一个文件中,不如将其放在头文件中,然后在每一个源代码文件中包含该头文件。这样,要修改结构声明时,只需在头文件中做一次改动即可。另外,可以将函数原型放在头文件中。因此,可以将原来的程序分成三部分。
请不要将函数定义或变量声明放到头文件中。这样做对简单情况可能是可行的,但通常会引来麻烦。例如,如果在头文件包含一个函数定义,然后在其他两个文件中包含该头文件,则同一个程序中将包含同一个函数的两个定义,除非函数是内联的,否则将会出错。下面列出了头文件中常包含的内容。
将结构声明放在头文件中是可以的,因为它们不创建变量,而只是在源代码文件中声明结构变量时,告诉编译器如何创建该结构变量。同样,模板声明不是将被编译的代码,它们指示编译器如果和生成与源代码中的函数调用相匹配的函数定义。被声明为const的数据和内联函数有特殊的链接属性,因此可以将其放在头文件中,而不会引起问题。
头文件管理
在同一个文件中只能将同一个头文件包含一次。有一种标准的C/C++技术可以避免多次包含同一个头文件。它是基于预处理器编译指令 #ifndef (即 if not defined)的。下面代码片段意味着仅当以前没有使用预处理器编译指令#define定义名称COORDIN_H_时,才处理 #ifndef 和 #endif之间的语句:
#ifndef COORDIN_H_ ... #endif
通常,使用#define语句来创建符号常量,如下所示:
#define MAXIMUM 4096
但只要将#define用于名称,就足以完成该名称的定义,如下所示:
#ifndef COORDIN_H_ #define COORDIN_H_ // place include file contents here #endif
多个库的链接
C++标准允许每个编译器设计人员以他认为合适的方式实现名称修饰,因此由不同编译器创建的二进制模块(对象代码文件)很可能无法正确地链接。也就是说,两个编译器将为同一个函数生成不同的修饰名称。名称的不同将使链接器无法将一个编译器生成的函数调用与另一个编译器生成的函数定义匹配。在链接编译模块时,请确保所有对象文件或库都是由同一个编译器生成的。如有源代码,通常可以用自己的编译器重新编译源代码来消除链接错误。
接下来扩展存储类别如何影响信息在文件间的共享。C++使用三种(在C++11中是四种)不同的方案来存储数据,这些方案的区别就在于数据保留在内存中的时间。
作用域描述了名称在文件的多大范围内可见。例如,函数中定义的变量可在该函数中使用,但不能在其他函数中使用;而在文件中的函数定义之前定义的变量则可在所有函数中使用。链接性(linkage)描述了名称如何在不同单元间共享。链接性为外部的名称可在文件间共享,链接性为内部的名称只能由一个文件中的函数共享。自动变量的名称没有链接性,因为它们不能共享。
C++变量的作用域有多种。作用域为局部的变量只在定义它的代码块中可用,代码块是由花括号括起的一系列语句。
C++函数的作用域可以是整个类或整个名称空间(包括全局的),但不能是局部的(因为不能在代码块内定义的函数,如果函数的作用域为局部,则只对它自己是可见的,因此不能被其他函数调用。这样的函数将无法运行)。
默认情况下,在函数中声明的函数参数和变量的存储持续性为自动,作用域为局部,没有链接性。也就是说,如果main()中声明了一个名为texas的变量,并在函数oil()中也声明了一个名称texas的变量,则创建了两个独立的变量——只有在定义他们的函数中才能使用它们。堆iol()的texas执行的任何操作都不会影响main()中的texas,反之亦然。另外,当程序开始执行这些变量所属的代码块时,将为其分配内存;当函数结束时,这些变量都将消失。
使用C++11中的auto
在C++11中,关键字auto用于自动类型推断。但在C语言和以前的C++版本中,auto的含义截然不同,它用于显式地指出变量为自动存储:
int froob(int n)
{
auto float ford; //ford has automatic stroage
...
}
由于只能将关键字用于默认为自动的变量,因此程序员几乎不使用它。它的主要用途是指出当前变量为局部自动变量。在C++11中,这种用法不再合法。
1,自动变量的初始化
可以使用任何在声明时其值已知的表达式来初始化自动变量,下面的示例初始化变量x,y,z:
int w; int x=5; int big =INT_MAX -1; int y=x *x; int y=2*x; cin>>w; int z=3*w;
2,自动变量的初始化
了解典型的C++编译器如何实现自动变量有助于更深入地了解自动变量。由于自动变量的数目随函数的开始和结束而增减,因此程序必须在运行时对自动变量进行管理。常用的方法是留出一段内存,并将其视为栈,以管理变量的增减。之所以被称为栈,是由于新数据被象征性地放在原有数据的上面(也就是说,在相邻的内存单元中,而不是在同一个内存单元中),当程序使用完后,将其从栈中删除。栈的默认长度取决于实现,但编译器通常提供改变栈长度的选项。程序使用两个指针来跟踪栈,一个指针指向栈底——栈的开始位置,另一个指针指向堆顶——下一个可用内存单元。当函数被调用时,其自动变量被加入到栈中,栈顶指针指向变量后面的下一个可用的内存单元。函数结束时,栈顶指针被重置为函数被调用前的值,从而释放新变量使用的内存。
栈时LIFO(后进先出)的,即最后加入到栈中的变量首先被弹出。这种设计简化了参数传递。函数调用将其参数的值放在栈顶,然后重新设置栈顶指针。被调用的函数根据其形参描述来确定每个参数的地址。下图中,函数fib()被调用时,传递一个2字节的int和一个4字节的long。这些值被加入到栈中。当fib()开始执行时,它将real和tell同这两个值关联起来。当fib()结束时,栈顶指针重新指向以前的位置。新值没有被删除,但不再被标记,它们所占据的空间将被下一个将值加入到栈中的函数调用所使用。

3,寄存器变量
关键字register最初是由C语言引入的,它建议编译器使用CPU寄存器来存储自动变量:
register int count_fast; //request for a rregister variable
这旨在提高访问变量的速度。
在C++11之前,这个关键字在C++中的用法始终未变,只是随着硬件和编译器变得越来越复杂,这种提示表明变量用的很多,编译器可以对其做特殊处理。在C++11中,这种提示作用也失去了,编辑案子register只是显式地指出变量是自动的。鉴于关键字register只能用于原本就是自动的变量,使用它唯一的原因是,指出程序员想使用一个自动变量,这个变量的名称可能与外部变量相同。这与auto以前的用途完全相同。然而,保留关键字register的重要原因是,避免使用了该关键字的现有代码非法。
和C语言一样,C++也为静态存储持续性变量提供了3种链接性:外部链接性(可在其他文件中访问)、内部链接性(只能在当前文件中访问)和无链接性(只能在当前函数或代码块中访问)。这3种链接性都在整个程序执行期间存在,与自动变量相比,它们的寿命更长。由于静态变量的数目在程序运行期间是不变的,因此程序不需要使用特殊的装置(如栈)来管理它们。编译器将分配固定的内存块来存储所有的静态变量,这些变量在整个程序执行期间一直存在。另外,如果没有显式地初始化静态变量,编译器将把它设置为0。在默认情况下,静态数组和结构将每个元素或成员的所有位都设置为0。
创建外部静态持续变量,在代码块外面声明它;
创建内部的静态持续变量,在代码块的外面声明它,并使用static限定符;
创建无链接的静态持续变量,在代码块中声明它,并使用static限定符。
...
int global =1000; // static duration, external linkage
static int one_file =50; //static duration, internal linkage
int main()
{
...
}
void funct1(int n)
{
static int count =0; // static duration, no linkage
int llama =0;
}
所有的静态持续变量都有下述初始化特征: 未被初始化的静态变量的所有位都被设置为0。这种变量称为零初始化的(zero-initialized)。
下表9.1总结了引入名称空间之前使用的初始化特征。指出了关键字static的两种用法,但含义有些不同:用于局部声明,以指出变量是无链接性的静态变量,static表示的是存储持续性;而用于代码块外的声明时,static表示内部链接性,而变量已经是静态持续性了。有人称之为关键字重载,即关键字的含义取决于上下文。
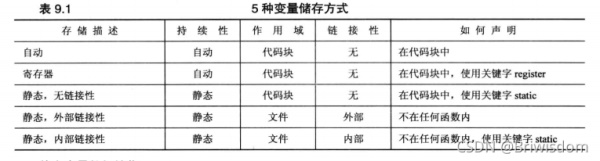
链接性为外部的变量通常称为外部变量,它们的存储持续性为静态,作用域为整个文件。外部变量是在函数外部定义的,因此对所有函数而言都是外部的。例如,可以在main()前面或头文件中定义它们。可以在文件中位于外部变量定义后面的任何函数中使用它,因此外部变量也称为全局变量。
1,单定义规则
一方面,在每个使用外部变量的文件中,都必须声明它;另一方面,C++有“单定义规则”(One Definition Rule, ODR), 该规则指出,变量只能有一次定义。为满足这种需求,C++提供了两种变量声明。一种是定义声明或简称定义,它给变量分配存储空间;另一种是引用声明或简称声明,它不给变量分配存储空间,因为它引用已有的变量。
引用声明使用关键字extern,且不进行初始化;否则,声明为定义,导致分配存储空间。
double up; //definition, up is 0; extern int blem; //blem defined elsewhere extern char gr ='z'; //definition because initialized
如果要在多个文件中使用外部变量,只需在一个文件中包含该变量的定义(单定义规则),但在使用变量的其他所有文件中,都必须使用关键字extern声明它。
全局变量和局部变量
既然可以选择使用全局变量或局部变量,那么到底应使用哪种呢?首先,全局变量很有吸引力——因为所有的函数能访问全局变量,因此不用传递参数。但易于访问的代价很大——程序不可靠。计算经验表明,程序越能避免对数据进行不必要的访问,就越能保持数据的完整性。通常情况下,应使用局部变量,应在需要知晓时才传递数据,而不应不加区分地使用全局变量来使数据可用。
将static限定符用于作用域为整个文件的变量时,该变量的链接性将为内部的。在多文件程序中,内部链接性和外部链接性之间的差别很有意义。链接性为内部的变量只能在其所属的文件中使用,但常规外部变量都具有外部链接性,即可以在其他文件中使用。
可使用外部变量在多文件程序的不同部分之间共享数据;可使用链接性为内部的静态变量在同一个文件中的多个函数之间共享数据(名称空间提供了另外一种共享数据的方法)。另外,如果将作用域为整个文件的变量变为静态的,就不必担心其名称与其他文件中的作用域为整个文件的变量发生冲突。
无链接性的局部变量是这样创建的,将static限定符用于在代码块中定义的变量。在代码块中使用static时,将导致局部变量的存储持续性为静态的。这意味着虽然该变量只在该代码块中可用,但它在该代码块不处于活动状态时仍然存在。因此在两次函数调用之间,静态局部变量的值将保持不变。(静态变量适用于再生)。另外,如果初始化了静态局部变量,则程序只在启动时进行一次初始化。以后再调用函数时,将不会像自动变量那样再次被初始化。
有些被称为存储说明符或cv-限定符的C++关键字提供了其他有关存储的信息。下面是存储说明符:
其中的大部分已经介绍过了,在同一个声明中不能使用多个说明符,但thread_local除外,它可与static或extern结合使用。前面讲过,在C++11之前,可以在声明中使用关键字auto指出变量为自动变量;但在C++11中,auto用于自动类型推断。关键字register用于在声明中指示寄存器存储,而在C++11中,它只是显式地指出变量是自动的。关键字static被用在作用域为整个文件的声明中时,表示内部链接性;被用于局部声明中,表示局部变量的存储持续性为静态的。关键字extern表明是引用声明,即声明在其他地方定义的变量。关键字thread_local指出变量的持续性与其所属线程的持续性相同。thread_local变量之于线程,犹如常规静态变量之于整个程序。关键字mutable的含义将根据const来解释,因此先来介绍cv-限定符,然后再解释它。
1. cv-限定符
下面就是cv限定符
const是常见的cv-限定符,它表明,内存被初始化后,程序便不能再对它进行修改。
关键字volatile表明,即使程序代码没有对内存单元进行修改,其值也可能发生变化。听起来似乎很神秘,实际上并非如此。例如,可以将一个指针指向某个硬件位置,其中包含了来自串行端口的时间或信息。在这种情况下,硬件(而不是程序)可能修改其中的内容。或者两个程序可能互相影响,共享数据。该关键字的作用是改善编译器的优化能力。例如,假设编译器发现,程序在几条语句中两次使用了某个变量的值,则编译器可能不是让程序查找这个值两次,而是将这个值缓存到寄存器中。这种优化假设变量的值在这两次使用之间不会变化。如果不将变量声明为volatile,则编译器将进行这种优化,将变量声明为volatile,相当于告诉编译器,不要进行这种优化。
2. mutable
现在回到mutable。可以用它来指出,即使结构(或类)变量为const。其某个成员也可以被修改。例如:
struct data
{
char name[30];
mutable int accesses;
...
};
const data veep = {"Claybourne Clodde",0, ...};
strcpy(veep.name, "Joye Joux"); //not allowed
veep.accesses++; //allowed
veep的const限定符禁止程序修改veep的成员,但access成员的mutable说明符使得access不受这种限制。
3. 再谈const
在C++(但不是在C语言)中,const限定符对默认存储类型稍有影响。在默认情况下全局变量的链接性为外部的,但const全局变量的链接性为内部的,也就是说,在C++看来,全局const定义就像使用了static说明符一样
const int fingers =10; //same as static const int fingers =10;
int main(void)
{
...
}
C ++修改了常量类型的规则,让程序员更轻松。例如,假设将一组常量放在头文件中,并在同一个程序的多个文件中使用该头文件。那么预处理器将头文件的内容包含到每个源文件中,所有的源文件都将包含类似下面的定义:
const int finers =10; const char * warning ="Wak!";
如果全局const声明的链接性像常规变量那样是外部的,则根据单定义规则,这将出错。也就是说,只能有一个文件可以包含前面的声明,而其他文件必须使用extern关键字来提供引用声明。另外,只有使用extern关键字的声明才能进行初始化:
//extern would be required if ocnst had external linkage extern const int fingers; //can't be initialized extern const char *warning;
因此,需要为某个文件使用一组定义,而其他文件使用另一组声明。然而,由于外部定义const数据的链接性为内部的,因此可以在所有文件中使用相同的声明。
内部链接性还意味着,每个文件都有自己的一组常量,而不是所有文件共享一组常量。每个定义都是其所属文件私有的,这就是能够将常量定义放在头文件中的原因。这样,只要在两个源代码文件中包括同一个头文件,则他们将获得同一组常量。
如果出于某种原因,程序员希望某个常量的链接性为外部的,则可以使用extern关键字来覆盖默认的内部链接性。
在函数或代码块中声明const时,其作用域为代码块,即仅当程序执行该代码块中的代码时,该常量才是可用的。这意味着在函数或代码块中创建常量时,不必担心其名称与其他地方定义的常量发生冲突。
和变量一样,函数也有链接性,虽然可选择的范围比变量小。和C语言一样,C++不允许在一个函数中定义另外一个函数,因此所有的存储持续性都自动为静态的,即在整个程序执行期间都一直存在。在默认情况下,函数的链接性为外部的,即可以在文件间共享。
实际上,可在函数原型中使用关键字extern来指出函数是在另一个文件中定义的,不过这是可选的(要让程序在另一个文件中查找函数,该文件必须作为程序的组成部分被编译,或者是由链接程序搜索的库文件)。还可以使用关键字static将函数的链接性设置为内部的,使之只能在一个文件中使用。必须同时在原型和函数定义中使用该关键字。
static int private(double x);
...
static int private(double x)
{
...
}
这意味着该函数只在这个文件中课件,还意味着可以在其他文件中定义同名的函数。和变量一样,在定义静态函数的文件中,静态函数将覆盖外部定义,因此即使在外部定义了同名的函数,该文件仍将用静态函数。
单定义规则也适用于非内联函数,因此对于每个非内联函数,程序只能包含一个定义,对于链接性为外部的函数来说,这意味着在多文件程序中,只能有一个文件(该文件可能是库文件,而不是您提供的)包含该函数的定义,但使用该函数的每个文件都应包含其函数原型。
内联函数不受这项规则的约束,这允许程序员能够将内联函数的定义放在头文件中。这样,包含了头文件的每个文件都有内联函数的定义。然而,C++要求同一个函数的所有内联定义都必须相同。
另一种形式的链接性——称为语言链接性也对函数有影响。链接程序要求每个不同的函数都有不同的符号名。在C语言中,一个名称只对应一个函数,因此这很容易实现。为满足内部需求,C语言编译器可能将spiff这样的函数名翻译为 _spiff。这种方法被称为C原因链接性。但在C++中,同一个名称可能对应多个函数,必须将这些函数翻译为不同的符号名称。因此,C++编译器执行名称矫正或名称修饰,为重载函数生成不同的符号名称。例如,可能将spiff(int)转换为_spoff_i,而将spiff(double, double)转换为_spiff_d_d。这种方法被称为C++语言链接。
链接程序寻找与C++函数调用匹配的函数时,使用的方法与C语言不同。但如果要在C++程序中使用C库中预编译的函数,将出现什么情况呢?例如,假设有下面的代码:
spiff(22); //want spiff(int) from a C library
它在C库文件中的符号名称为_spiff, 但对于我们假设的链接程序来说,C++查询约定时查找符号名称 _spiff_i。为解决这种问题,可以用函数原型来指出要使用的约定:
extern "C" void spiff(int); //use C protocol for name look-up extern void spoff(int); //use C++ protocol for name look-up extern "C++" void spaff(int); //use C++ protocol for name look-up
第一个原型使用C语言链接性;而后面的两个使用C++语言链接性。第二个原型是通过默认方式指出这一点的,而第三个显式地指出了这一点。
C和C++链接性是C++标准制定的说明符,但实现可提供其他语言链接性说明符。
前面介绍C++用来为变量(包括数组和结构)分配内存的5种方案(线程内存除外),他们不适用于使用C++运算符new(或C函数malloc())分配的内存,这种内存被称为动态内存。动态内存运算符由new和delete控制,而不是由作用域和链接性规则控制。因此,可以在一个函数中分配动态内存,而在另一个函数中将其释放。与自动内存不同,动态内存不是LIFO,其分配和释放顺序要取决于new和delete在何时以何种方式被使用。通常,编译器使用三块独立的内存:一块用于静态变量,一块用于自动变量,另外一块用于动态存储。
虽然存储方案概念不适用于动态内存,但适用于用来跟踪动态内存的自动和静态指针变量。例如,假设在一个函数中包含下面的语句:
float * p_free =new float [20];
由new分配的80个字节(假设float为4个字节)的内存将一直保留在内存中,直到使用delete运算符将其释放。但当包含该声明语句块执行完毕时,p_fees指针将消失。如果希望另一个函数能够使用这80个字节的内存,则必须将其地址传递或返回给该函数。另一方面,如果将p_fees的链接性声明为外部的,则文件中位于该声明后面的所有函数都可以使用它。另外,通过在另一个文件中使用下述声明,便可在其中使用该指针:
extern float * p_fees;
1. 使用new运算符初始化
如果要初始化动态分配的变量,该如何办呢?在C++98中,有时候可以这样做,C++11增加了其他可能性。
如果要为内置的标量类型(如int或double)分配存储空间并初始化,可在类型名后面加上初始值,并将其用括号括起:
int *pi =new int(6); double * pd =new double (99.99);
这种括号语法也有可用于构造函数的类,这将在本书后面介绍。
然而,要初始化常规结构或数组,需要使用大括号的列表初始化,这要求编译器支持C++11。C++11允许您这样做:
struct where {double x; double y; double z;};
where * one =new where {2.5, 5.3, 7.2}; //C++11
int * ar =new int [4] {2,4,6,7}; //C++11
在C++11中,还可将列表初始化用于单值变量:
int *pin =new int {};
double *pdo= new double {99.99};
2. new 失败时
new可能找不到请求的内存量。在最初10年中,C++在这种情况下让new返回空指针,但现在将引发一场std::bad_alloc。
3. new: 运算符、函数和替换函数
运算符new和new[]分别调用如下函数:
void * operator new(std::size_t); //used by new void * operator new[] (std:: size_t) //used by new[]
这些函数被称为分配函数,他们位于全局名称空间中。同样也有delete和delete[]调用的释放函数:
void operator delete(void *); void operator delete [](void *);
4. 定位new运算符
通常,new负责在堆中找到一个足以能够满足要求的内存块。new运算符还有另一种变体,被称为定位new运算符,它让您能够指定要使用的位置。程序员可能使用这种特性来设置其内存管理规程、处理需要通过特定地址进行访问的硬件或在特定位置创建对象。
要使用定位new特性,首先需要包含头文件new,它提供了这种版本的new运算符的原型;然后将new运算符用于提供了所需地址的参数。除需要指定参数外,句法与常规new运算符相同。具体地说,使用定位new运算符,变量后面可以有方括号,也可以没有。下面演示了new运算符的4种用法:
#include <new>
struct chaff
{
char dross[20];
int slag;
} ;
char buffer1[50];
int *p3, *p4;
//first, the regular forms of new
p1 = new chaff; //place structure in heap
p3 = new int [20]; // place int array in heap
//now, the two forms of placement new
p2 = new (buffer1) chaff; //place structure in buffer1
p4 = new (buffer2) int[20]; //place int array in buffer2
...
出于简化的目的,这个示例使用两个静态数组来为定位new运算符提供内存空间。因此,上述代码从buffer1中分配空间给结构chaff, 从buffer2中分配空间给一个包含20个元素的int数组。
C++中,名称可以是变量、函数、结构、枚举。类以及类和结构的成员。当随着项目的增大,名称相互冲突的可能性也将增加。使用多个厂商的类库时,可能导致名称冲突。例如,两个库可能都定义了名称为List、Tree和Node的类,但定义的方式不兼容。用户可能希望使用一个库的List类,而使用另一个库的Tree类。这种冲突被称为名称空间问题。
C++标准提供了名称空间工具,以便更好地控制名称的作用域。经过了一段时间后,编译器才支持名称空间,但现在这种支持很普遍。
介绍C++中新增的名称空间特性之前,先复习一下C++中已有的名称空间属性,以及概念。
声明区域。声明区域是可以在其中进行声明的区域。例如,可以在函数外面声明全局变量,对于这种变量,其声明区域为其所在的文件。对于在函数中声明的变量,其声明区域为其声明所在的代码块。
潜在作用域。变量的潜在作用域从声明点开始,到其声明区域的结尾。因此潜在作用域比声明区域小,这是由于变量必须定义后才能使用。
然而,变量并非在其潜在作用域内的任何位置都是可见的。例如,它可能被另一个嵌套声明区域中声明的同名变量隐藏。例如,在函数中声明的局部变量将隐藏在同一个文件中声明的全局变量。变量对程序而言可见的范围被称为作用域。
C++关于全局变量和局部变量的规则定义了一种名称空间层次。每个声明区域都可以声明名称,这些名称独立于在其他声明区域中声明的名称。在一个函数中声明的局部变量不会与在另一个函数中声明的局部变量发生冲突。
C++新增了这样一种功能,即通过定义一种新的声明区域来创建命名的名称空间,这样做得目的之一是提供一个声明名称的区域。一个名称空间中的名称不会与另外一个名称空间的相同名称发生冲突,同时允许程序的其他部分使用该名称空间中声明的东西。
名称空间可以是全局的,也可以位于另一个名称空间中,但不能位于代码块中。因此,在默认情况下,在名称空间中声明的名称的链接性为外部的。
除了用户定义的名称空间外,还存在另一个名称空间——全局名称空间。它对应于文件级声明区域,因此前面所说的全局变量现在被描述为位于全局名称空间中。
任何名称空间中的名称都不会与其他名称空间中的名称发生冲突。名称空间中的声明和定义规则同全局声明和定义规则相同。
名称空间是开放的,即可以把名称空间加入到已有的名称空间中。下面这条语句将名称goose添加到Jill中已有的名称列表中:
namespace Jill {
char * goose(const char *);
}
同样,原来的Jack名称空间为fetch()函数提供了原型。可以在该文件后面(或另外一个文件中)再次使用Jack名称空间来提供该函数的代码:
namespace Jack{
void fetch()
{
...
}
}
当然,需要有一种方法来访问给定名称空间中的名称。最简单的方法是,通过作用域解析运算符::,使用名称空间来限定该名称:
Jack:: pail =12.34; //use a variable Jill::Hill mole; //create a type Hill structure Jack::fetch(); //use a function
未被装饰的名称称为未限定的名称;包含名称空间的名称称为限定的名称。
1. using声明和using编译指令
C++提供两种机制(using声明和using编译指令)来简化对名称空间中名称的使用。using声明使特定的标识符可用,using编译指令使整个名称空间可用。
using声明由被限定的名称和它前面的关键字using组成,using声明将特定的名称添加到它所属的声明区域中。
using声明使一个名称可用,而using编译指令使所有的名称都可用。using编译指令由名称空间名和它前面的关键字using namespace组成,它使名称空间中的所有名称都可用,而不需要使用作用域解析运算符。
在全局声明区域中使用using编译指令,将使该名称空间的名称全局可用。在函数中使用using 编译指令,将使其中的名称在该函数中可用。
2. using编译指令和using声明之比较
使用using编译指令导入一个名称空间中所有的名称与使用多个using声明使不一样的,而更像是大量使用作用域解析运算符。使用using声明时,就好像声明了相应的名称一样。如果某个名称已经在函数中声明了,则不能用using声明导入相同的名称。然而,使用using编译指令时,将进行名称解析,就像在包含using声明和名称空间本身的最小声明区域中声明了名称一样。
注意:假设名称空间和声明区域定义了相同的名称。如果试图使用using声明将名称空间的名称导入该声明区域,则这两个名称会发生冲突,从而出错。如果使用using编译指令将该名称空间的名称导入该声明区域,则局部版本将隐层名称空间版本。
一般来说,使用using声明比使用using编译指令更安全,这是由于它只导入指定的名称。如果该名称与局部名称发生冲突,编译器将发出指示。using编译指令导入所有名称,包括可能并不需要的名称。如果与局部名称发生冲突,则局部名称将覆盖名称空间版本,而编译器并不会发出警告。另外,名称空间的开放性意味着名称空间的名称可能分散在多个地方,这使得难以准确知道添加了哪些名称。
3. 名称空间的其他特性
可以将名称空间声明进行嵌套:
namespace elements
{
namespace fire
{
int flame;
...
}
float water;
}
4. 未命名的名称空间
可以通过省略名称空间的名称来创建未命名的名称空间
namespace //unnamed namespace
{
int ice;
int bandycoot;
}
这就像后面跟着using编译指令一样,也就是说,在该名称空间中声明的名称潜在作用域为:从声明点到该声明区域末尾。从这个方面看,它们与全局变量相似。然而,由于这种名称空间没有名称,因此不能显式地使用using编译指令或using声明来使它在其他位置都可用。具体的说,不能在未命名名称空间所属文件之外的其他文件中,使用该名称空间中的名称。这提供了链接性为内部的静态变量的替代品。
随着程序员逐渐熟悉名称空间,将出现统一的编程理念。下面是当前的一些指导原则。
使用名称空间的主旨是简化大型编程项目的管理工作。对于只有一个文件的简单程序,使用using编译指令并非什么大逆不道的事。

本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注的更多内容!

