聚类分析或聚类是对一组对象进行分组的任务,使得同一组(称为聚类)中的对象(在某种意义上)与其他组(聚类)中的对象更相似(在某种意义上)。它是探索性数据挖掘的主要任务,也是统计 数据分析的常用技术,用于许多领域,包括机器学习,模式识别,图像分析,信息检索,生物信息学,数据压缩和计算机图形学。
聚类分析本身不是一个特定的算法,而是要解决的一般任务。它可以通过各种算法来实现,这些算法在理解群集的构成以及如何有效地找到它们方面存在显着差异。流行的群集概念包括群集成员之间距离较小的群体,数据空间的密集区域,间隔或特定的统计分布。因此,聚类可以表述为多目标优化问题。适当的聚类算法和参数设置(包括距离函数等参数)使用,密度阈值或预期聚类的数量)取决于个体数据集和结果的预期用途。这样的聚类分析不是自动任务,而是涉及试验和失败的知识发现或交互式多目标优化的迭代过程。通常需要修改数据预处理和模型参数,直到结果达到所需的属性。
常用的聚类算法分为基于划分、层次、密度、网格、统计学、模型等类型的算法,典型算法包括K均值(经典的聚类算法)、DBSCAN、两步聚类、BIRCH、谱聚类等。
聚类算法中k-means是最常使用的方法之一,但是k-means要注意数据异常:
有异常的数据可以使用DBSCAN聚类方法进行处理,DBSCAN的全称是Density-Based Spatial Clustering of Applications with Noise,中文含义是“基于密度的带有噪声的空间聚类”。
跟K均值相比,它具有以下优点:
由于他对整个数据集进行操作且聚类时使用了一个全局性的表征密度的参数,因此也存在比较明显的弱点:
K均值在算法稳定性、效率和准确率(相对于真实标签的判别)上表现非常好,并且在应对大量数据时依然如此。它的算法时间复杂度上界为O(nkt),其中n是样本量、k是划分的聚类数、t是迭代次数。当聚类数和迭代次数不变时,K均值的算法消耗时间只跟样本量有关,因此会呈线性增长趋势。
但是当面对海量数据时,k均值算法计算速度慢会产生延时,尤其算法被用于做实时性处理时这种弊端尤为明显。针对K均值的这一问题,很多延伸算法出现了,MiniBatchKMeans就是其中一个典型代表。MiniBatchKMeans使用了一个种名为Mini Batch(分批处理)的方法计算数据点之间的距离。Mini Batch的好处是计算过程中不必使用所有的数据样本,而是从不同类别的样本中抽取一部分样本(而非全部样本)作为代表参与聚类算法过程。由于计算样本量少,所以会相应减少运行时间;但另一方面,由于是抽样方法,抽样样本很难完全代表整体样本的全部特征,因此会带来准确度的小幅度下降,但是并不明显。
在大数据背景下,有很多高纬度数据场景,如电子商务交易数据、web文本数据日益丰富。高维数据聚类时耗时长、聚类结果准确性和稳定性都不尽如人意。因为,在高维数据,基于距离的相似度计算效率极低;特征值过多在所有维度上存在簇的可能性非常低;由于稀疏性和紧邻特性,基于距离的相似度几乎为0,导致高维空间很难出现数据簇。这时我们可以选着使用子空间聚类,或是降维处理。
子空间聚类算法是在高维数据空间中对传统聚类算法的一种扩展,其思想是选取与给定簇密切相关的维,然后在对应的子空间进行聚类。比如谱聚类就是一种子空间聚类方法,由于选择相关维的方法以及评估子空间的方法需要自定义,因此这种方法对操作者的要求较高。
用较少的数据量来表示原有的像素矩阵的过程,这个过程称为图像编码。数据图像的显著特点是数据量庞大,需要占用相当大的储存空间,这给图像的存储、计算、传输等带来了不便。因此,现在大多数数字网络下的图像都会经过压缩后再做进一步应用,图像压缩的方法之一便是聚类算法。
在使用聚类算法做图像压缩时,我们会定义K个颜色数(例如128种颜色),颜色数就是聚类类别的数量;K均值聚类算法会把类似的颜色分别放在K个簇中,然后每个簇使用一种颜色来代替原始颜色,那么结果就是有多少个簇,就生成了多少种颜色构成的图像,由此实现图像压缩。
图像分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣的目标技术和过程,这是图像处理和分析的关键步骤。图像分割后提取出的目标可以用于图像语义识别,图像搜索等领域。例如从图像中分割出前景人脸信息,然后做人脸识别。聚类算法是图像分割方法的一种,其实施的关键是通过不同区域间明显不同的图像色彩特征做聚类,聚类数量就是要分割的区域的数量。
在图像理解中,有一种称为基于区域的提取方法。基于区域的提取方法是在图像分割和对象识别的前提下进行的,利用对象模板、场景分类器等,通过识别对象及对象之间的拓扑关系挖掘语义,生成对应的场景语义信息。例如,先以颜色、形状等特征对分割后的图像区域进行聚类,形成少量BLOB;然后通过CMRM模型计算出BLOB与某些关键词共同出现的概率。
异常检测有多种实施方法,其中常用的方法是基于距离的异常检测方法。即使数据集不满足任何特定分布模型,它仍能有效地发现离群点,特别是当空间维度比较高时,算法的效率比基于密度的方法要高得多。算法具体实现时,首先算出数据样本间的距离(如曼哈顿距离、欧氏距离等),然后对数据做预处理后就可以根据距离的定义来检测异常值。
例如,可以使用K-means的聚类可以将离中心店最远的类或者不属于任何一个类的数据点提取出来,然后将其定义为异常值。
python代码实现
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
%matplotlib inline
# 数据准备
data = make_blobs(n_samples=2000, centers=[[1,1], [-1, -1]], cluster_std=0.7, random_state=2018)
X = data[0]
y = data[1]
#设置聚类数量
n_clusters = 2
# 建立聚类模型对象
kmeans = KMeans(n_clusters=n_clusters, random_state=2018)
# 训练聚类模型
kmeans.fit(X)
# 预测聚类模型
pre_y = kmeans.predict(X)
### 模型效果指标评估 ###
# 样本距离最近的聚类中心的总和
inertias = kmeans.inertia_
# 调整后的兰德指数
adjusted_rand_s = metrics.adjusted_rand_score(y, pre_y)
# 互信息
mutual_info_s = metrics.mutual_info_score(y, pre_y)
# 调整后的互信息
adjusted_mutual_info_s = metrics.adjusted_mutual_info_score(y, pre_y)
# 同质化得分
homogeneity_s = metrics.homogeneity_score(y, pre_y)
# 完整性得分
completeness_s = metrics.completeness_score(y, pre_y)
# V-measure得分
v_measure_s = metrics.v_measure_score(y, pre_y)
# 平均轮廓系数
silhouette_s = metrics.silhouette_score(X, pre_y, metric='euclidean')
# Calinski 和 Harabaz 得分
calinski_harabaz_s = metrics.calinski_harabaz_score(X, pre_y)
df_metrics = pd.DataFrame([[inertias, adjusted_rand_s,mutual_info_s, adjusted_mutual_info_s, homogeneity_s,completeness_s,v_measure_s, silhouette_s ,calinski_harabaz_s]],
columns=['ine','tARI','tMI','tAMI','thomo','tcomp','tv_m','tsilh','tc&h'])
df_metrics

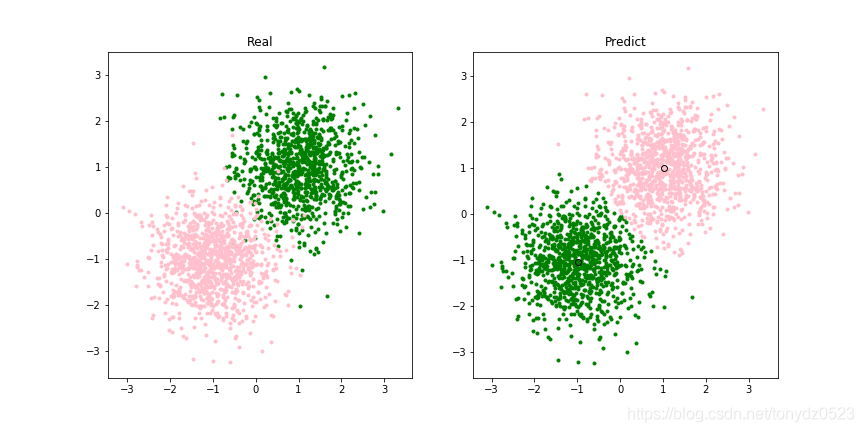
## 模型可视化##
centers = kmeans.cluster_centers_
# 颜色设置
colors = ['green', 'pink']
# 创建画布
plt.figure(figsize=(12,6))
titles = ['Real', 'Predict']
for j, y_ in enumerate([y, pre_y]):
plt.subplot(1,2, j+1)
plt.title(titles[j])
# 循环读类别
for i in range(n_clusters):
# 找到相同的索引
index_sets = np.where(y_ == i)
# 将相同类的数据划分为一个聚类子集
cluster = X[index_sets]
# 展示样本点
plt.scatter(cluster[:, 0], cluster[:, 1], c=colors[i], marker='.')
if j==1:
# 簇中心
plt.plot(centers[i][0], centers[i][1], 'o',markerfacecolor=colors[i],markeredgecolor='k', markersize=6)
plt.savefig('xx.png')
plt.show()
评估指标解析:
参考:
《python数据分析与数据化运营》 宋天龙

