使用python网络爬虫登录12306,网站界面如下。因为网站的反爬是不断升级的,以下代码虽然当前可用,但早晚必将会不再能满足登录需求。但是知识的价值,是不容置疑的。
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
from selenium.webdriver import ChromeOptions
# 去除浏览器识别
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option("detach", True)
driver = webdriver.Chrome(options=option)
driver.get('https://kyfw.12306.cn/otn/resources/login.html')
# 解决特征识别
script = 'Object.defineProperty(navigator, "webdriver", {get: () => false,});'
driver.execute_script(script)
# 输入账号
driver.find_element_by_id('J-userName').send_keys('123@163.com')
# 输入密码
driver.find_element_by_id('J-password').send_keys('xxxxxxx')
# 点击登陆
driver.find_element_by_id('J-login').click()
# 等待2秒钟,不要点的太快,以免被识别或者以免网页加载跟不上。
time.sleep(2)
# 滑动
# 定位 滑块标签
span = driver.find_element_by_id('nc_1_n1z')
actions = ActionChains(driver) # 行为链实例化
time.sleep(2) # 等待2秒钟
# 经截图测量,滑块需要滑过的距离为300像素
actions.click_and_hold(span).move_by_offset(300, 0).perform() # 滑动解决浏览器识别:
其中的以下这几行代码,可用去除浏览器对selenium的识别,如图可以使浏览器页面不再显示图中“Chrome正受到自动测试软件的控制”字样。
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option("detach", True)
driver = webdriver.Chrome(options=option)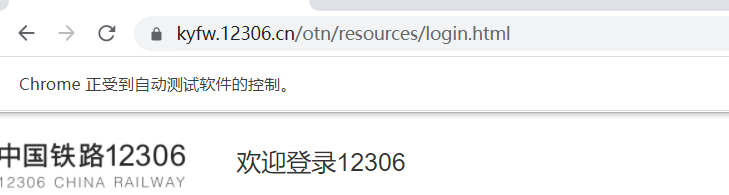
解决特征识别的代码:
script = 'Object.defineProperty(navigator, "webdriver", {get: () => false,});'
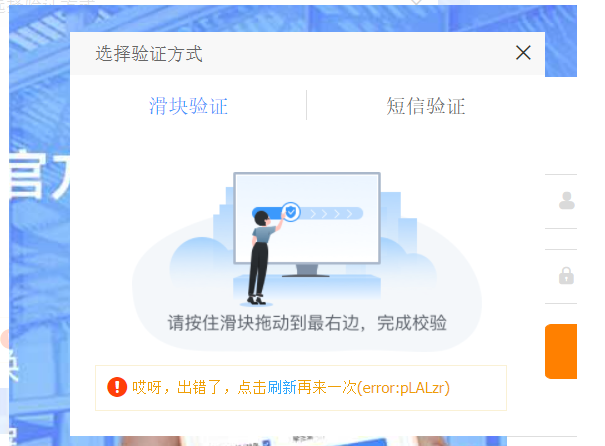
driver.execute_script(script)如果不采取去除特征识别,即以下两行代码。则页面的滑块验证码在滑动后,会显示如下图的出错,从而阻止登录进行。因为服务器识别到的selenium的特征。使用该两行代码更改了特征,即可以顺利通过识别。