最容易使 HashMap 发生哈希冲突的方法是什么呢?我们可以创建一个类,让它的哈希函数返回一个最糟糕的结果 —— 比如一个常数。
哈希方法返回常数会造成什么结果?有很多次面试者会回答说 map 集合里会有且仅有一个元素,因为 map 中的旧元素总会被新的覆盖。这个回答当然是错误的。
哈希冲突并不会导致 HashMap 覆盖一个已经存在于集合中的元素,这种情况只会在使用者试图向集合中放入两个元素,并且它们的键对于 equal() 方法是相等的时候才会发生。
键不相等但又会产生哈希冲突的不同元素最终会以某种数据结构存储在 HashMap 的同一个桶中(注意,在这种情况下,因为插入和查找的操作都要耗费更长的时间,所以整体的性能就会受到影响)。
首先,我们用一个小程序来模拟哈希冲突。下面的写法可能比较夸张,因为它造成的冲突比现实中多得多,但这个程序对于证实哈希冲突的条件还是很重要的。
我们使用一个 Person 对象作为 map 的键,以字符串作为值。下面是 Person 的具体实现,有一个 firstName 字段,一个 lastName 字段和一个 ID 属性,其中 ID 属性以 UUID 对象表示。
public class Person {
private String firstName;
private String lastName;
private UUID id;
public Person(String firstName, String lastName, UUID id) {
this.firstName = firstName;
this.lastName = lastName;
this.id = id;
}
@Override
public int hashCode() {
return 5;
}
@Override
public boolean equals(Object obj) {
// ... pertty good equals here taking into account the id field...
}
// ...
}现在我们可以开始制造一些冲突。
private static final int LIMIT = 500_000;
private void fillAndSearch() {
Person person = null;
Map<Person, String> map = new HashMap<>();
for (int i=0;i<LIMIT;i++) {
UUID randomUUID = UUID.randomUUID();
person = new Person("fn", "ln", randomUUID);
map.put(person, "comment" + i);
}
long start = System.currentTimeMillis();
map.get(person);
long stop = System.currentTimeMillis();
System.out.println(stop-start+" millis");
}上面的代码在一台高性能计算机上运行了两个半小时。其中,最后的查找操作耗费了大约 40 毫秒。现在我们对 Person 类进行修改:使它实现 Comparable 接口,并且添加了下面的方法:
@Override
public int compareTo(Person person) {
return this.id.compareTo(person.id);
}再一次运行之前的程序,这一次在我的机器上它耗费的时间少于 1 分钟。其中,最终的查找操作耗费的时间接近为 0 毫秒 —— 比之前提高了 150 倍!
就像前面说的,Java 8 做了很多优化,其中也包括HashMap 类。在 Java 7 中,两个不同的元素,如果它们的键产生了冲突,那么会被存储在同一个链表中。而从 Java 8 开始,如果发生冲突的频率大于某一个阈值(8),并且 map 的容量超过了另一个阈值(64),整个链表就会被转换成一个二叉树。
原来如此!所以,对于没有实现 Comparable 的键,最终的树是不平衡的;而对于实现了 Comparable 的键,其二叉树就会是高度平衡的。事实是这样吗?不是。HashMap 内部是红黑树,也就是说它总是平衡的。我通过反射机制,查看了最终的树结构。对于拥有 50000 个元素(不敢让数字更大了)的 HashMap 来说,两种不同的情况下(实现或是不实现 Comparable 接口)树的高度都是 19 。
那么,为什么之前的实验结果会有那么大的差别呢?原因在于,当 HashMap 想要为一个键找到对应的位置时,它会首先检查新键和当前检索到的键之间是否可以比较(也就是实现了 Comparable 接口)。如果不能比较,它就会通过调用 tieBreakOrder(Object a,Object b) 方法来对它们进行比较。这个方法首先会比较两个键对象的类名,如果相等再调用 System.identityHashCode 方法进行比较。这整个过程对于我们要插入的 500000 个元素来说是很耗时的。另一种情况是,如果键对象是可比较的,整个流程就会简化很多。因为键对象自身定义了如何与其它键对象进行比较,就没有必要再调用其他的方法,所以整个插入或查找的过程就会快很多。值得一提的是,在两个可比的键相等时(compareTo 方法返回 0)的情况下,仍然会调用 tieBreakOrder 方法。
总而言之,在 Java 8 的 HashMap 里,如果一个桶里存放了大量的元素,它在达到阈值时就会被转换为一棵红黑树,对于实现了 Comparable 接口的键来说,插入或删除的操作会比没有实现 Comparable 接口的键更简单。
通常,如果一个桶不会发生那么多次冲突的话,这整个机制不会带来多大的性能提升,但起码现在我们对 HashMap 的内部原理有了更多了解。
HashSet的底层是HashMap,TreeSet的底层是TreeMap。
TreeSet中存放自定义类时应该先指定比较的规则(compare)
要当前比较的类型实现一个借口Comparable接口,重写compareTo方法,方法的内部制定比较规则, 硬编码习惯,不够灵活,每次修改源代码。
public class Student implements Comparable<Student>{
.........
//重写compareTo方法
@Override
public int compareTo(Student o) {
return this.stuName.length()-o.stuName.length();
}
}
使用任何一个实现类实现一个接口Comparator,重写compare方法,方法的内部制定比较规则。
public class CompareDemo {
public static void main(String[] args) {
Comparator<Student> comparator=new Home();
//lambda表达式
comparator=(Student o1, Student o2)->{return o1.getStuName().length()-o2.getStuName().length();};
//指定使用参数比较器
//TreeSet(Comparator<? super E> comparator)
TreeSet treeSet=new TreeSet(comparator);
treeSet.add(new Student("张三爸",40,158));
treeSet.add(new Student("张三",20,168));
treeSet.add(new Student("张三爷爷",60,178));
System.out.println(treeSet);
}
}
class Home implements Comparator<Student>{
@Override
public int compare(Student o1, Student o2) {
return o1.getStuName().length()-o2.getStuName().length();
}
}
HashMap应该注意的事项 :
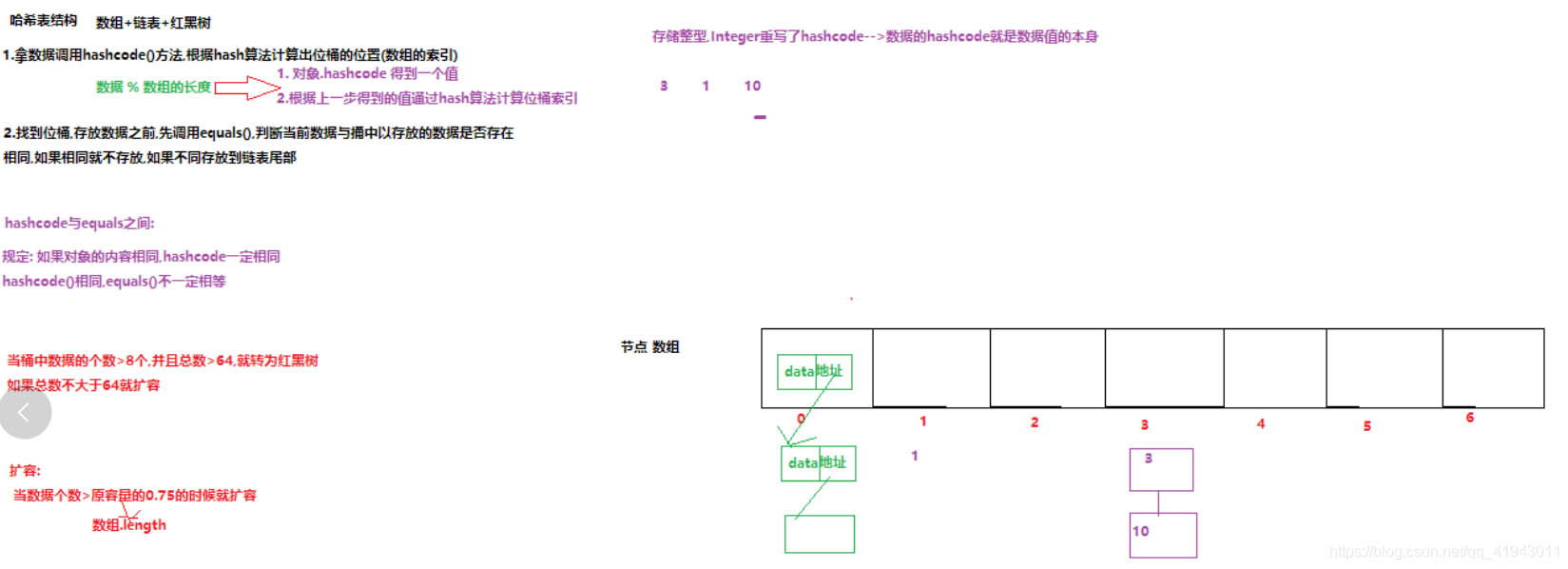
手写HashMap应该注意对key值进行比较,如果key相同则新的value覆盖旧的value。table是上图中横向的数组,默认初始值为16,计算key在数组中的位置时使用:key.hashcode%table.length,这种方式效率较低,一般使用 key.hashcode&(table.length-1)。
class MyHashMap{
private Node [] table;
private int size;
public void put(Object key, Object value) {
if(table==null){
table=new Node[16];
}
int hash=getHash(key);
Node node=table[hash];//获取他在数组上的位置
Node newNode=new Node(hash,key,value,null);
if(node==null){
table[hash]=newNode;
size++;
}else{
while(true){
//进行key值的比较
if(node.getKey().equals(key)){
node.setValue(value);
break;
}
if(node==null){
break;
}
node=node.getNext();
}
node.setNext(newNode);
size++;
}
}
public int getHash(Object key){
return key.hashCode()&(table.length-1);
}
@Override
public String toString() {
StringBuilder sbr=new StringBuilder("{");
for(Node node:table){
while(node!=null){
sbr.append(node.getKey()+"--->"+node.getValue()+",");
node=node.getNext();
}
}
sbr.setCharAt(sbr.length()-1,'}');
return sbr.toString();
}
}
Properties:用来代替hashMap,实现了Map接口,线程安全的HashTable:可以代替hashMap,线程安全以上为个人经验,希望能给大家一个参考,也希望大家多多支持。

