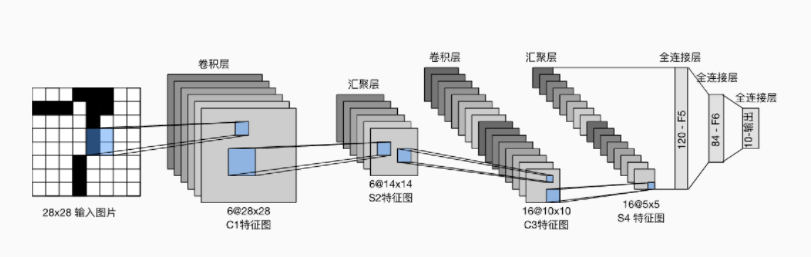
LeNet网络过卷积层时候保持分辨率不变,过池化层时候分辨率变小。实现如下
from PIL import Image
import cv2
import matplotlib.pyplot as plt
import torchvision
from torchvision import transforms
import torch
from torch.utils.data import DataLoader
import torch.nn as nn
import numpy as np
import tqdm as tqdm
class LeNet(nn.Module):
def __init__(self) -> None:
super().__init__()
self.sequential = nn.Sequential(nn.Conv2d(1,6,kernel_size=5,padding=2),nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,kernel_size=5),nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2,stride=2),
nn.Flatten(),
nn.Linear(16*25,120),nn.Sigmoid(),
nn.Linear(120,84),nn.Sigmoid(),
nn.Linear(84,10))
def forward(self,x):
return self.sequential(x)
class MLP(nn.Module):
def __init__(self) -> None:
super().__init__()
self.sequential = nn.Sequential(nn.Flatten(),
nn.Linear(28*28,120),nn.Sigmoid(),
nn.Linear(120,84),nn.Sigmoid(),
nn.Linear(84,10))
def forward(self,x):
return self.sequential(x)
epochs = 15
batch = 32
lr=0.9
loss = nn.CrossEntropyLoss()
model = LeNet()
optimizer = torch.optim.SGD(model.parameters(),lr)
device = torch.device('cuda')
root = r"./"
trans_compose = transforms.Compose([transforms.ToTensor(),
])
train_data = torchvision.datasets.MNIST(root,train=True,transform=trans_compose,download=True)
test_data = torchvision.datasets.MNIST(root,train=False,transform=trans_compose,download=True)
train_loader = DataLoader(train_data,batch_size=batch,shuffle=True)
test_loader = DataLoader(test_data,batch_size=batch,shuffle=False)
model.to(device)
loss.to(device)
# model.apply(init_weights)
for epoch in range(epochs):
train_loss = 0
test_loss = 0
correct_train = 0
correct_test = 0
for index,(x,y) in enumerate(train_loader):
x = x.to(device)
y = y.to(device)
predict = model(x)
L = loss(predict,y)
optimizer.zero_grad()
L.backward()
optimizer.step()
train_loss = train_loss + L
correct_train += (predict.argmax(dim=1)==y).sum()
acc_train = correct_train/(batch*len(train_loader))
with torch.no_grad():
for index,(x,y) in enumerate(test_loader):
[x,y] = [x.to(device),y.to(device)]
predict = model(x)
L1 = loss(predict,y)
test_loss = test_loss + L1
correct_test += (predict.argmax(dim=1)==y).sum()
acc_test = correct_test/(batch*len(test_loader))
print(f'epoch:{epoch},train_loss:{train_loss/batch},test_loss:{test_loss/batch},acc_train:{acc_train},acc_test:{acc_test}')epoch:12,train_loss:2.235553741455078,test_loss:0.3947642743587494,acc_train:0.9879833459854126,acc_test:0.9851238131523132
epoch:13,train_loss:2.028963804244995,test_loss:0.3220392167568207,acc_train:0.9891499876976013,acc_test:0.9875199794769287
epoch:14,train_loss:1.8020273447036743,test_loss:0.34837451577186584,acc_train:0.9901833534240723,acc_test:0.98702073097229
找了一张图片,将其分割成只含一个数字的图片进行测试

images_np = cv2.imread("/content/R-C.png",cv2.IMREAD_GRAYSCALE)
h,w = images_np.shape
images_np = np.array(255*torch.ones(h,w))-images_np#图片反色
images = Image.fromarray(images_np)
plt.figure(1)
plt.imshow(images)
test_images = []
for i in range(10):
for j in range(16):
test_images.append(images_np[h//10*i:h//10+h//10*i,w//16*j:w//16*j+w//16])
sample = test_images[77]
sample_tensor = torch.tensor(sample).unsqueeze(0).unsqueeze(0).type(torch.FloatTensor).to(device)
sample_tensor = torch.nn.functional.interpolate(sample_tensor,(28,28))
predict = model(sample_tensor)
output = predict.argmax()
print(output)
plt.figure(2)
plt.imshow(np.array(sample_tensor.squeeze().to('cpu')))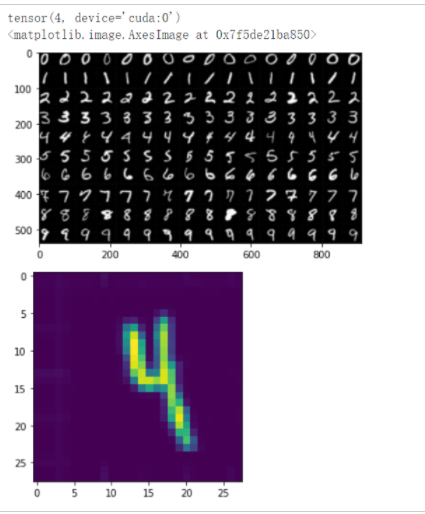
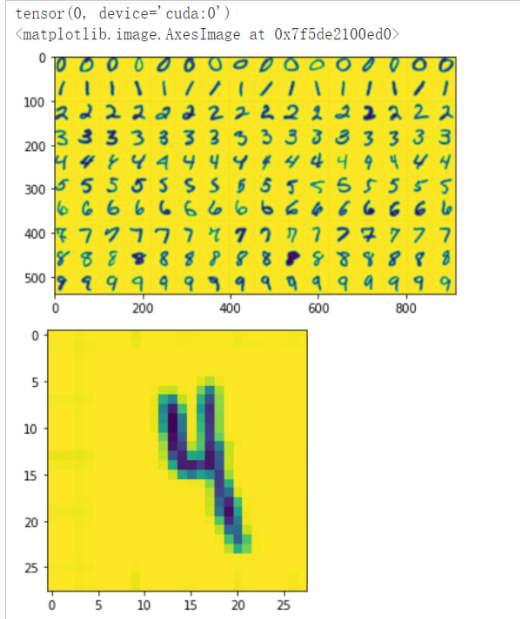
此时预测结果为4,预测正确。从这段代码中可以看到有一个反色的步骤,若不反色,结果会受到影响,如下图所示,预测为0,错误。
模型用于输入的图片是单通道的黑白图片,这里由于可视化出现了黄色,但实际上是黑白色,反色操作说明了数据的预处理十分的重要,很多数据如果是不清理过是无法直接用于推理的。
将所有用来泛化性测试的图片进行准确率测试:
correct = 0
i = 0
cnt = 1
for sample in test_images:
sample_tensor = torch.tensor(sample).unsqueeze(0).unsqueeze(0).type(torch.FloatTensor).to(device)
sample_tensor = torch.nn.functional.interpolate(sample_tensor,(28,28))
predict = model(sample_tensor)
output = predict.argmax()
if(output==i):
correct+=1
if(cnt%16==0):
i+=1
cnt+=1
acc_g = correct/len(test_images)
print(f'acc_g:{acc_g}')如果不反色,acc_g=0.15
acc_g:0.50625

