亚马逊网站相较于国内的购物网站,可以直接使用python的最基本的requests进行请求。访问不是过于频繁,在未触发保护机制的情况下,可以获取我们想要的数据。本次通过以下三部分简单介绍下基本爬取流程:
使用requests的get请求,获取亚马逊列表和详情页的页面内容使用css/xpath对获取的内容进行解析,取得关键数据动态IP的作用及其使用方法
以游戏区为例:
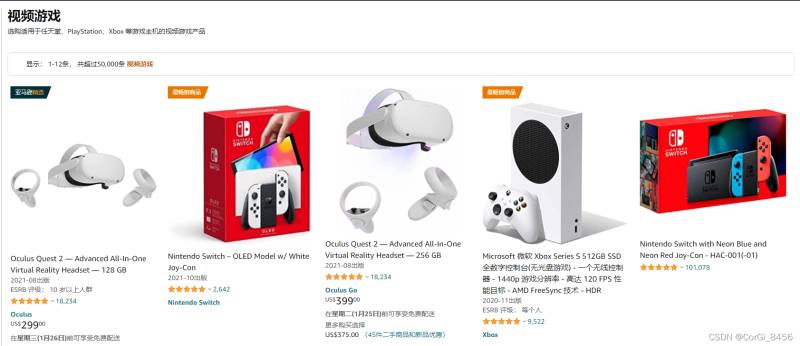
获取列表内能获取到的商品信息,如商品名,详情链接,进一步获取其他内容。
用requests.get()获取网页内容,设置好header,利用xpath选择器选取相关标签的内容:
import requests
from parsel import Selector
from urllib.parse import urljoin
spiderurl = 'https://www.amazon.com/s?i=videogames-intl-ship'
headers = {
"authority": "www.amazon.com",
"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_3 like Mac OS X) AppleWebKit/603.3.8 (KHTML, like Gecko) Mobile/14G60 MicroMessenger/6.5.19 NetType/4G Language/zh_TW",
}
resp = requests.get(spiderurl, headers=headers)
content = resp.content.decode('utf-8')
select = Selector(text=content)
nodes = select.xpath("//a[@title='product-detail']")
for node in nodes:
itemUrl = node.xpath("./@href").extract_first()
itemName = node.xpath("./div/h2/span/text()").extract_first()
if itemUrl and itemName:
itemUrl = urljoin(spiderurl,itemUrl)#用urljoin方法凑完整链接
print(itemUrl,itemName)此时已经获取的当前列表页目前能获得的信息:

进入详情页:

进入详情页之后,能获得更多的内容
用requests.get()获取网页内容,css选取相关标签的内容:
res = requests.get(itemUrl, headers=headers)
content = res.content.decode('utf-8')
Select = Selector(text=content)
itemPic = Select.css('#main-image::attr(src)').extract_first()
itemPrice = Select.css('.a-offscreen::text').extract_first()
itemInfo = Select.css('#feature-bullets').extract_first()
data = {}
data['itemUrl'] = itemUrl
data['itemName'] = itemName
data['itemPic'] = itemPic
data['itemPrice'] = itemPrice
data['itemInfo'] = itemInfo
print(data)此时已经生成详情页数据的信息:

目前涉及到的就是最基本的requests请求亚马逊并用css/xpath获取相应的信息。
目前,国内访问亚马逊会很不稳定,我这边大概率会出现连接不上的情况。如果真的需要去爬取亚马逊的信息,最好使用一些稳定的代理,我这边自己使用的是ipidea的代理,可以白嫖50M流量。如果有代理的话访问的成功率会高,速度也会快一点。
代理使用有两种方式,一是通过api获取IP地址,还有用账密的方式使用,方法如下:
3.1.1 api获取代理
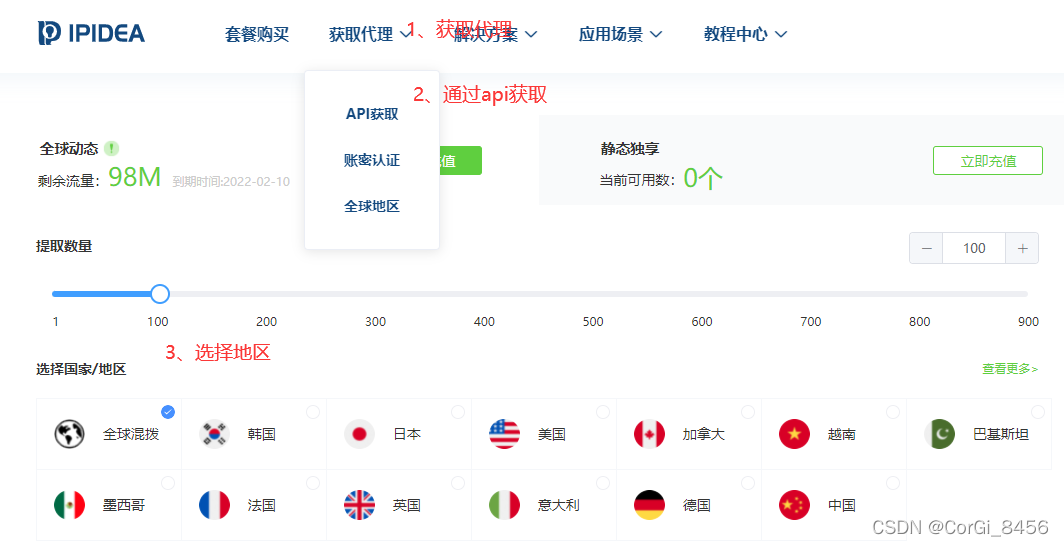
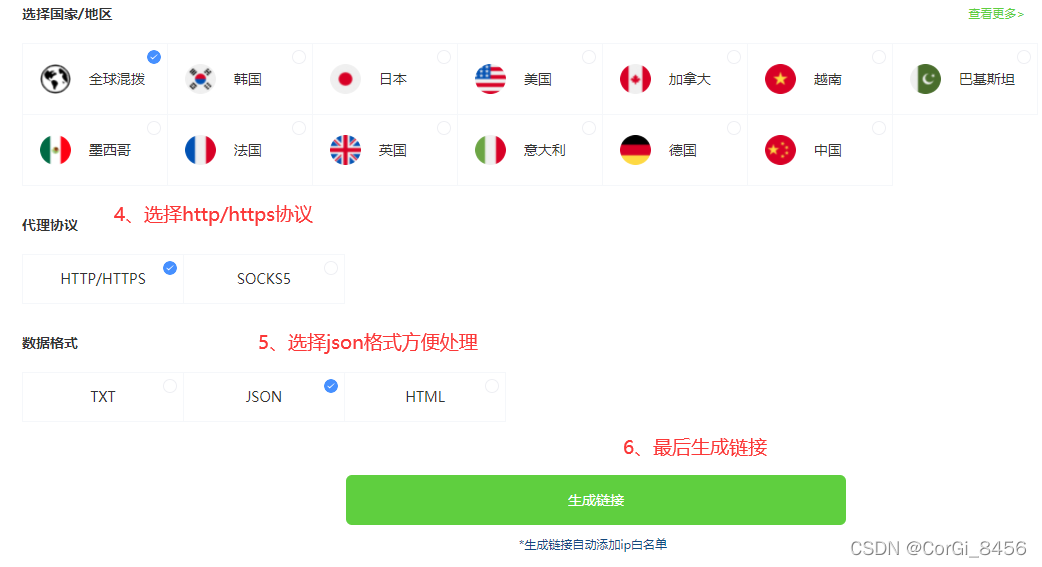
3.1.2 api获取ip代码
def getProxies():
# 获取且仅获取一个ip
api_url = '生成的api链接'
res = requests.get(api_url, timeout=5)
try:
if res.status_code == 200:
api_data = res.json()['data'][0]
proxies = {
'http': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
'https': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
}
print(proxies)
return proxies
else:
print('获取失败')
except:
print('获取失败')3.2.1 账密获取代理
因为是账密验证,所以需要 去到账户中心填写信息创建子账户:
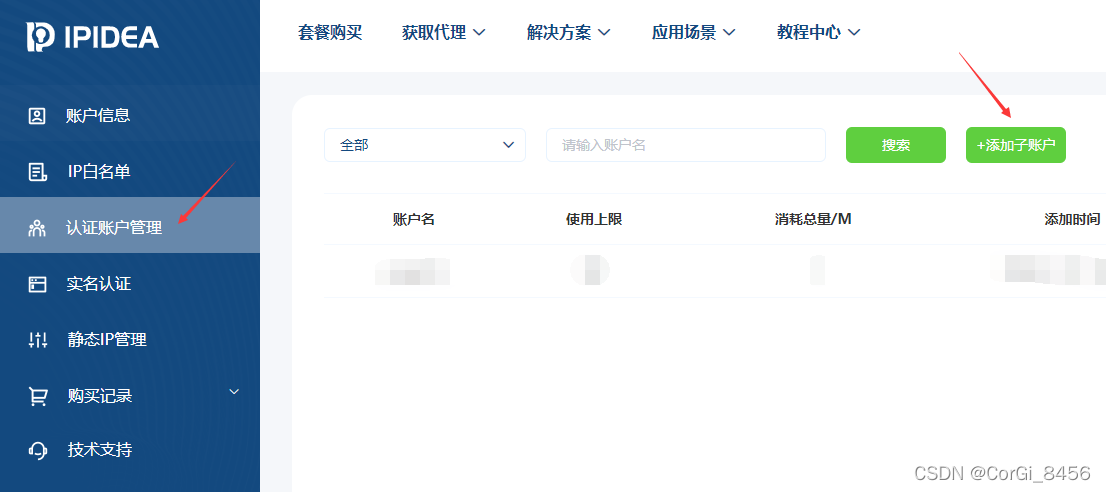
创建好子账户之后,根据账号和密码获取链接:
3.2.2 账密获取代理代码
# 获取账密ip
def getAccountIp():
# 测试完成后返回代理proxy
mainUrl = 'https://api.myip.la/en?json'
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_3 like Mac OS X) AppleWebKit/603.3.8 (KHTML, like Gecko) Mobile/14G60 MicroMessenger/6.5.19 NetType/4G Language/zh_TW",
}
entry = 'http://{}-zone-custom{}:proxy.ipidea.io:2334'.format("帐号", "密码")
proxy = {
'http': entry,
'https': entry,
}
try:
res = requests.get(mainUrl, headers=headers, proxies=proxy, timeout=10)
if res.status_code == 200:
return proxy
except Exception as e:
print("访问失败", e)
pass使用代理之后,亚马逊商品信息的获取改善了不少,之前代码会报各种连接失败的错误,在requests请求之前调用代理获取的方法,方法return回代理ip并加入requests请求参数,就可以实现代理请求了。
# coding=utf-8
import requests
from parsel import Selector
from urllib.parse import urljoin
def getProxies():
# 获取且仅获取一个ip
api_url = '生成的api链接'
res = requests.get(api_url, timeout=5)
try:
if res.status_code == 200:
api_data = res.json()['data'][0]
proxies = {
'http': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
'https': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
}
print(proxies)
return proxies
else:
print('获取失败')
except:
print('获取失败')
spiderurl = 'https://www.amazon.com/s?i=videogames-intl-ship'
headers = {
"authority": "www.amazon.com",
"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_3 like Mac OS X) AppleWebKit/603.3.8 (KHTML, like Gecko) Mobile/14G60 MicroMessenger/6.5.19 NetType/4G Language/zh_TW",
}
proxies = getProxies()
resp = requests.get(spiderurl, headers=headers, proxies=proxies)
content = resp.content.decode('utf-8')
select = Selector(text=content)
nodes = select.xpath("//a[@title='product-detail']")
for node in nodes:
itemUrl = node.xpath("./@href").extract_first()
itemName = node.xpath("./div/h2/span/text()").extract_first()
if itemUrl and itemName:
itemUrl = urljoin(spiderurl,itemUrl)
proxies = getProxies()
res = requests.get(itemUrl, headers=headers, proxies=proxies)
content = res.content.decode('utf-8')
Select = Selector(text=content)
itemPic = Select.css('#main-image::attr(src)').extract_first()
itemPrice = Select.css('.a-offscreen::text').extract_first()
itemInfo = Select.css('#feature-bullets').extract_first()
data = {}
data['itemUrl'] = itemUrl
data['itemName'] = itemName
data['itemPic'] = itemPic
data['itemPrice'] = itemPrice
data['itemInfo'] = itemInfo
print(data)通过上面的步骤,可以实现最基础的亚马逊的信息获取。
目前只获得最基本的数据,若想获得更多也可以自行修改xpath/css选择器去拿到你想要的内容。而且稳定的动态IP能是你进行请求的时候少一点等待的时间,无论是编写中的测试还是小批量的爬取,都能提升工作的效率。以上就是全部的内容。

