surfaceflinger作用是接受多个来源的图形显示数据,将他们合成,然后发送到显示设备。比如打开应用,常见的有三层显示,顶部的statusbar底部或者侧面的导航栏以及应用的界面,每个层是单独更新和渲染,这些界面都是有surfaceflinger合成一个刷新到硬件显示。在显示过程中使用到了bufferqueue,surfaceflinger作为consumer方,比如windwomanager管理的surface作为生产方产生页面,交由surfaceflinger进行合成。

bufferqueue分为生产者和消费者
比如应用通过windowsmanager分配一个surface,需要分配(dequeueBuffer)显示空间在上面进行绘图,在图形绘制完成后需要推送(queueBuffer)到surfaceflinger进行合成显示。
surfaceflinger作为消费者,通过acquireBuffer()得到一个要合成的图形,在合成完毕后再releaseBuffer()将图形释放。
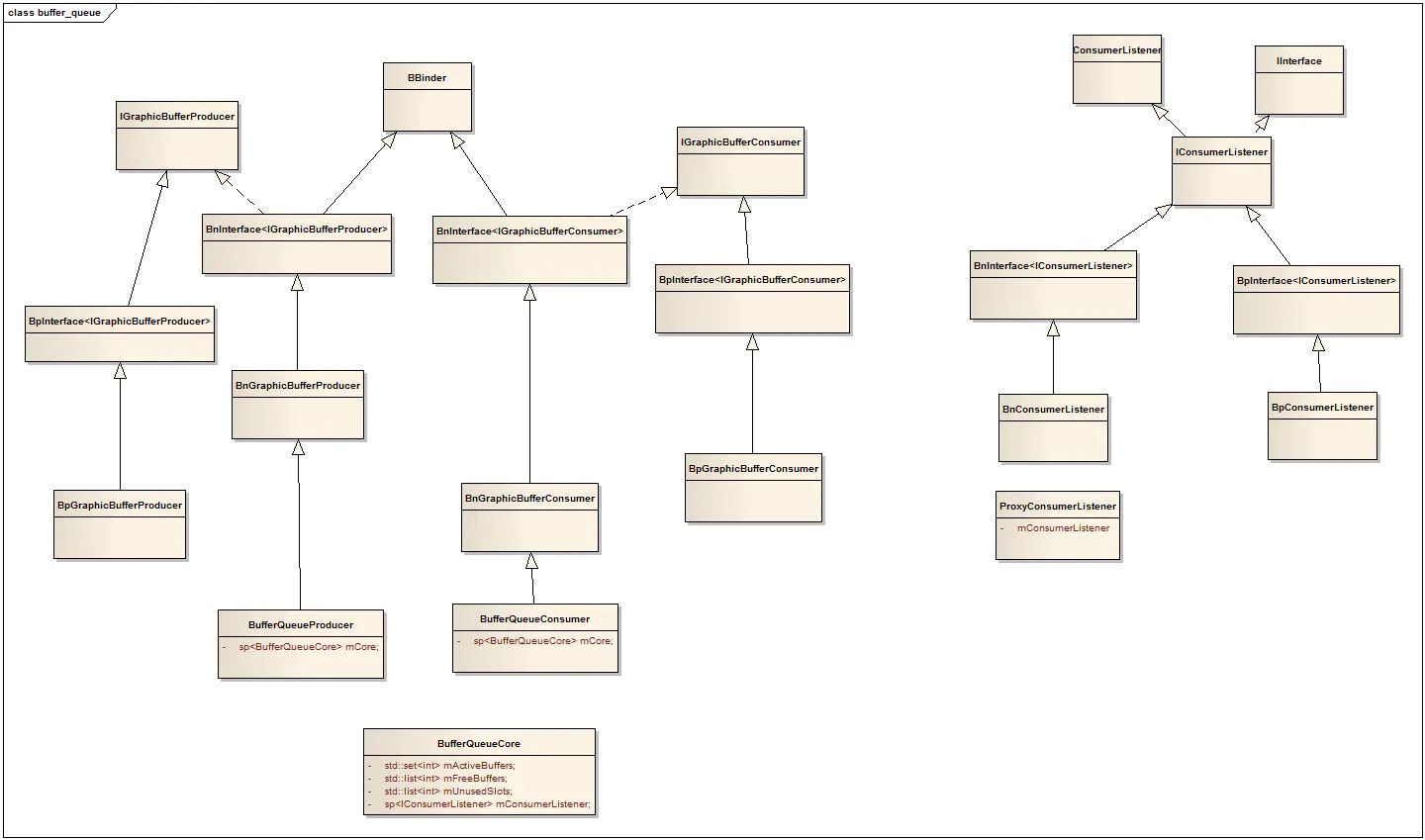
bufferqueue类图关系如下:

ComposerService 为单例模式负责与surfaceflinger建立binder连接代码如下:
class ComposerService : public Singleton<ComposerService>
{
sp<ISurfaceComposer> mComposerService;
sp<IBinder::DeathRecipient> mDeathObserver;
Mutex mLock;
ComposerService();
void connectLocked();
void composerServiceDied();
friend class Singleton<ComposerService>;
public:
// Get a connection to the Composer Service. This will block until
// a connection is established.
static sp<ISurfaceComposer> getComposerService();
};
void ComposerService::connectLocked() {
const String16 name("SurfaceFlinger");
while (getService(name, &mComposerService) != NO_ERROR) {
usleep(250000);
}
assert(mComposerService != NULL);
// Create the death listener.
class DeathObserver : public IBinder::DeathRecipient {
ComposerService& mComposerService;
virtual void binderDied(const wp<IBinder>& who) {
ALOGW("ComposerService remote (surfaceflinger) died [%p]",
who.unsafe_get());
mComposerService.composerServiceDied();
}
public:
DeathObserver(ComposerService& mgr) : mComposerService(mgr) { }
};
mDeathObserver = new DeathObserver(*const_cast<ComposerService*>(this));
mComposerService->asBinder()->linkToDeath(mDeathObserver);
}
/*static*/ sp<ISurfaceComposer> ComposerService::getComposerService() {
ComposerService& instance = ComposerService::getInstance();
Mutex::Autolock _l(instance.mLock);
if (instance.mComposerService == NULL) {
ComposerService::getInstance().connectLocked();
assert(instance.mComposerService != NULL);
ALOGD("ComposerService reconnected");
}
return instance.mComposerService;
}
SurfaceComposerClient则在于surfaceflinger建立连接后建立与Client的连接,通过client调用createSurface,然后返回SurfaceControl
sp<SurfaceControl> SurfaceComposerClient::createSurface(
const String8& name,
uint32_t w,
uint32_t h,
PixelFormat format,
uint32_t flags)
{
sp<SurfaceControl> sur;
if (mStatus == NO_ERROR) {
sp<IBinder> handle;
sp<IGraphicBufferProducer> gbp;
status_t err = mClient->createSurface(name, w, h, format, flags,
&handle, &gbp);
ALOGE_IF(err, "SurfaceComposerClient::createSurface error %s", strerror(-err));
if (err == NO_ERROR) {
sur = new SurfaceControl(this, handle, gbp);
}
}
return sur;
}
SurfaceControl负责这个显示层的控制。
sp<Surface> SurfaceControl::getSurface() const
{
Mutex::Autolock _l(mLock);
if (mSurfaceData == 0) {
// This surface is always consumed by SurfaceFlinger, so the
// producerControlledByApp value doesn't matter; using false.
mSurfaceData = new Surface(mGraphicBufferProducer, false);
}
return mSurfaceData;
}
通过SurfaceControl::getSurface(),得到的真正的显示层,这样之后可以通过Lock和unlock将surface空间分配绘图,再返回给surfaceflinger
上面只是cpp侧的分析,上层比如WMS是java层,他的管理也是同底层一样,只不过是有层JNI的封装。
surface创建后得到 mGraphicBufferProducer,通过mGraphicBufferProducer dequeubuffer在surfaceflinger的BnGraphicBufferProducer dequeuebuffer
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, mSwapIntervalZero,
reqW, reqH, mReqFormat, mReqUsage);
sp<GraphicBuffer>& gbuf(mSlots[buf].buffer);
if ((result & IGraphicBufferProducer::BUFFER_NEEDS_REALLOCATION) || gbuf == 0) {
result = mGraphicBufferProducer->requestBuffer(buf, &gbuf);
if (result != NO_ERROR) {
ALOGE("dequeueBuffer: IGraphicBufferProducer::requestBuffer failed: %d", result);
return result;
}
*buffer = gbuf.get();
}
}
在producer的server侧,new GraphicBuffer分配一个GraphicBuffer
if (returnFlags & BUFFER_NEEDS_REALLOCATION) {
BQ_LOGV("dequeueBuffer: allocating a new buffer for slot %d", *outSlot);
sp<GraphicBuffer> graphicBuffer = new GraphicBuffer(
width, height, format, BQ_LAYER_COUNT, usage,
{mConsumerName.string(), mConsumerName.size()});
在graphicbuffer中就是分配一个共享内存
GraphicBuffer::GraphicBuffer(uint32_t inWidth, uint32_t inHeight,
PixelFormat inFormat, uint32_t inLayerCount, uint64_t usage, std::string requestorName)
: GraphicBuffer()
{
mInitCheck = initWithSize(inWidth, inHeight, inFormat, inLayerCount,
usage, std::move(requestorName));
}
status_t GraphicBuffer::initWithSize(uint32_t inWidth, uint32_t inHeight,
PixelFormat inFormat, uint32_t inLayerCount, uint64_t inUsage,
std::string requestorName)
{
GraphicBufferAllocator& allocator = GraphicBufferAllocator::get();
uint32_t outStride = 0;
status_t err = allocator.allocate(inWidth, inHeight, inFormat, inLayerCount,
inUsage, &handle, &outStride, mId,
std::move(requestorName));
if (err == NO_ERROR) {
mBufferMapper.getTransportSize(handle, &mTransportNumFds, &mTransportNumInts);
width = static_cast<int>(inWidth);
height = static_cast<int>(inHeight);
format = inFormat;
layerCount = inLayerCount;
usage = inUsage;
usage_deprecated = int(usage);
stride = static_cast<int>(outStride);
}
return err;
}
GraphicBufferAllocator::get() 使用gralloc进行内存分配,分配完成后,得到bufferIdx 将他发给client端也就是surface端
virtual status_t requestBuffer(int bufferIdx, sp<GraphicBuffer>* buf) {
Parcel data, reply;
data.writeInterfaceToken(IGraphicBufferProducer::getInterfaceDescriptor());
data.writeInt32(bufferIdx);
status_t result =remote()->transact(REQUEST_BUFFER, data, &reply);
if (result != NO_ERROR) {
return result;
}
bool nonNull = reply.readInt32();
if (nonNull) {
*buf = new GraphicBuffer();
result = reply.read(**buf);
if(result != NO_ERROR) {
(*buf).clear();
return result;
}
}
result = reply.readInt32();
return result;
返回虚拟地址给上层
void* vaddr;
status_t res = backBuffer->lockAsync(
GRALLOC_USAGE_SW_READ_OFTEN | GRALLOC_USAGE_SW_WRITE_OFTEN,
newDirtyRegion.bounds(), &vaddr, fenceFd);
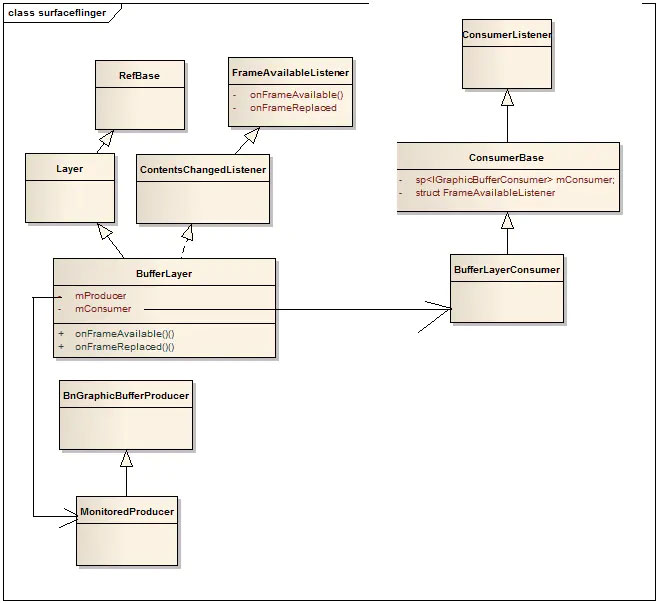
上面创建一个surface后,surfaceflinger对应的是一个layer,当上层layer调用刷新后,onFrameAvailable被调用,通知surfaceflinger有layer更新
void BufferLayer::onFrameAvailable(const BufferItem& item) {
mFlinger->signalLayerUpdate();
}
到此这篇关于Android显示系统SurfaceFlinger分析的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持。

