本文数据采取文献[1]给出的数据集,该数据集前8列为特征,最后1列为标签(0/1)。本模型使用pandas处理该数据集,需要注意的是,原始数据集没有特征名称,需要自己在第一行添加上去,否则,pandas会把第一行的数据当成特征名称处理,从而影响最后的分类效果。
代码如下:
# 1、准备数据
import torch
import pandas as pd
import numpy as np
xy = pd.read_csv('G:/datasets/diabetes/diabetes.csv',dtype=np.float32) # 文件路径
x_data = torch.from_numpy(xy.values[:,:-1])
y_data = torch.from_numpy(xy.values[:,[-1]])本文采取文献[1]的思路,激活函数使用ReLU,最后一层使用Sigmoid函数,
代码如下:
class Model(torch.nn.Module): def __init__(self): super(Model,self).__init__() self.linear1 = torch.nn.Linear(8,6) self.linear2 = torch.nn.Linear(6,4) self.linear3 = torch.nn.Linear(4,1) self.activate = torch.nn.ReLU() def forward(self, x): x = self.activate(self.linear1(x)) x = self.activate(self.linear2(x)) x = torch.sigmoid(self.linear3(x)) return x model = Model()
将模型和数据加载到GPU上,代码如下:
### 将模型和训练数据加载到GPU上
# 模型加载到GPU上
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
# 数据加载到GPU上
x = x_data.to(device)
y = y_data.to(device)3、构造损失函数和优化器 criterion = torch.nn.BCELoss(reduction='mean') optimizer = torch.optim.SGD(model.parameters(),lr=0.1)
epoch_list = [] loss_list = [] epochs = 10000 for epoch in range(epochs): # Forward y_pred = model(x) loss = criterion(y_pred, y) print(epoch, loss) epoch_list.append(epoch) loss_list.append(loss.data.item()) # Backward optimizer.zero_grad() loss.backward() # Update optimizer.step()
查看各个层的权重和偏置:
model.linear1.weight,model.linear1.bias model.linear2.weight,model.linear2.bias model.linear3.weight,model.linear3.bias
损失值随迭代次数的变化曲线:
# 绘图展示
plt.plot(epoch_list,loss_list,'b')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.grid()
plt.show()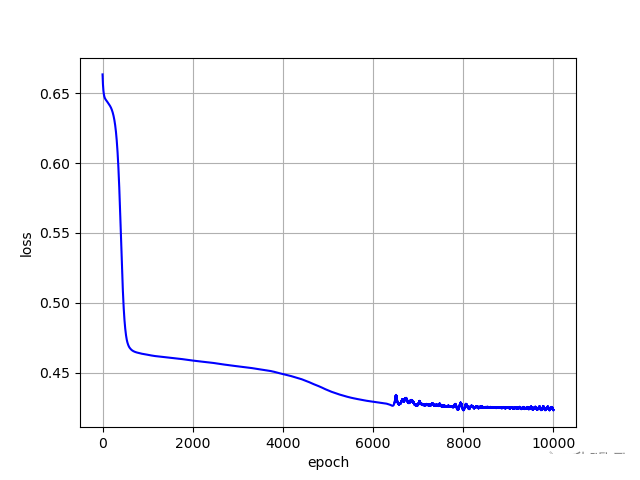
最终的损失和准确率:
# 准确率
y_pred_label = torch.where(y_pred.data.cpu() >= 0.5,torch.tensor([1.0]),torch.tensor([0.0]))
acc = torch.eq(y_pred_label, y_data).sum().item()/y_data.size(0)
print("loss = ",loss.item(), "acc = ",acc)
loss = 0.4232381284236908 acc = 0.7931488801054019到此这篇关于PyTorch实现多维度特征输入逻辑回归的文章就介绍到这了,更多相关PyTorch逻辑回归内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!

