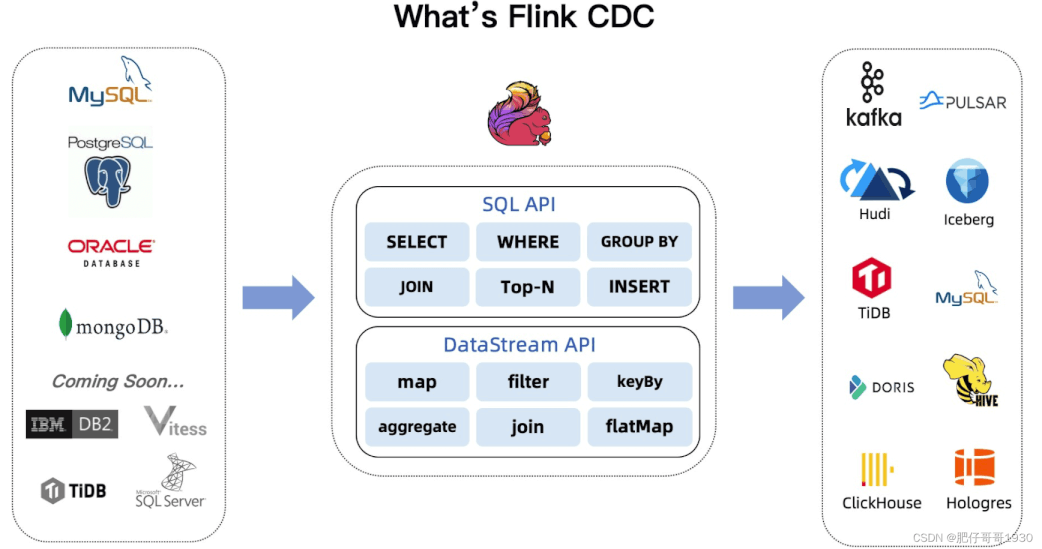
CDC (Change Data Capture) ,在广义的概念上,只要能捕获数据变更的技术,都可以称为 CDC 。但通常我们说的CDC 技术主要面向数据库(包括常见的mysql,Oracle, MongoDB等)的变更,是一种用于捕获数据库中数据变更的技术。
常见的主要包括Flink CDC,DataX,Canal,Sqoop,Kettle,Oracle Goldengate,Debezium等。
2020年 Flink cdc 首次在 Flink forward 大会上官宣, 由 Jark Wu & Qingsheng Ren 两位大佬提出。
Flink CDC connector 可以捕获在一个或多个表中发生的所有变更。该模式通常有一个前记录和一个后记录。Flink CDC connector 可以直接在Flink中以非约束模式(流)使用,而不需要使用类似 kafka 之类的中间件中转数据。
PS:
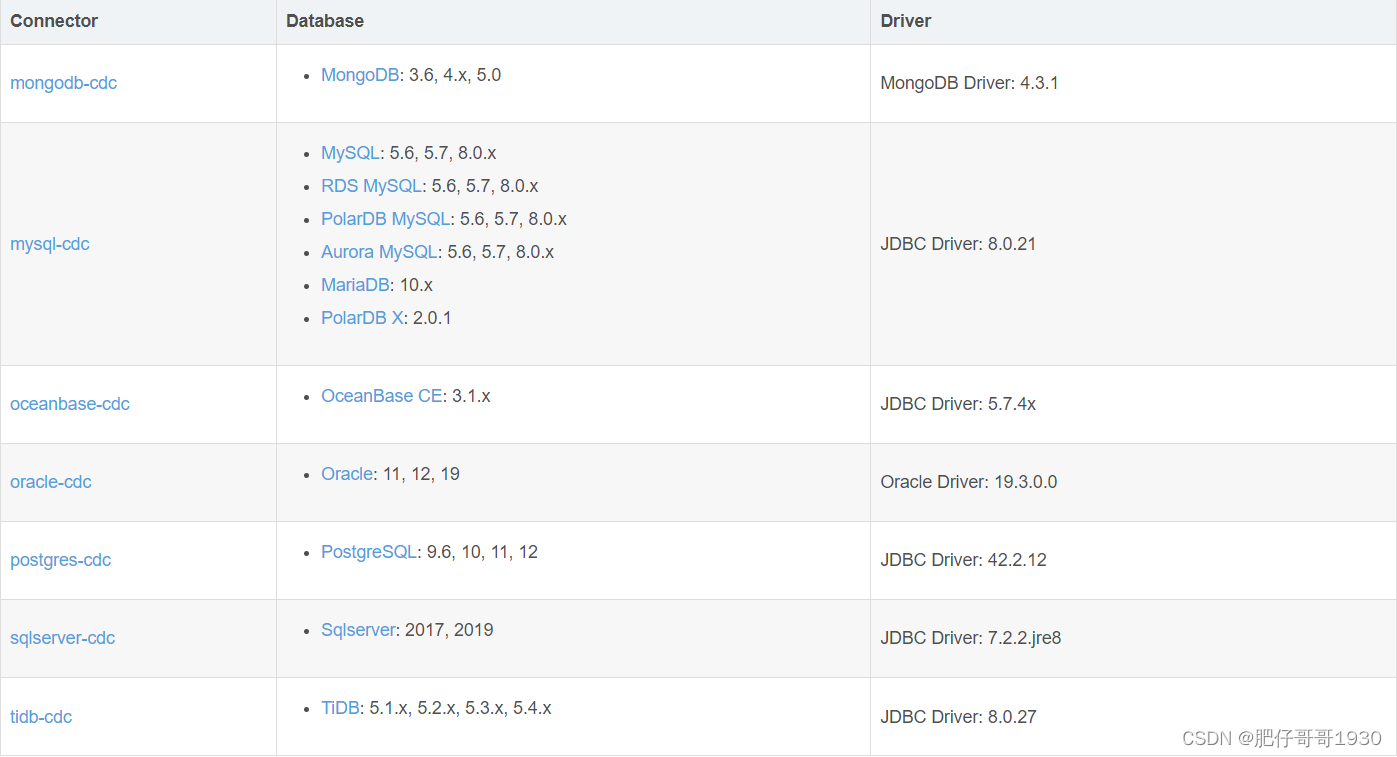
Flink CDC 2.2才新增OceanBase,PolarDB-X,SqlServer,TiDB 四种数据源接入,均支持全量和增量一体化同步。
截止到目前FlinkCDC已经支持12+数据源。
<!-- flink table支持 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 阿里实现的flink mysql CDC -->
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>1.4.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.80</version>
</dependency>
<!-- jackson报错解决 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>${jackson.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>${jackson.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.module</groupId>
<artifactId>jackson-module-parameter-names</artifactId>
<version>${jackson.version}</version>
</dependency>package spendreport.cdc;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import com.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import java.util.List;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
;
/**
* @author zhengwen
**/
public class TestMySqlFlinkCDC {
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.Flink-CDC 将读取 binlog 的位置信息以状态的方式保存在 CK,如果想要做到断点续传, 需要从 Checkpoint 或者 Savepoint 启动程序
//2.1 开启 Checkpoint,每隔 5 秒钟做一次 CK
env.enableCheckpointing(5000L);
//2.2 指定 CK 的一致性语义
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//2.3 设置任务关闭的时候保留最后一次 CK 数据
env.getCheckpointConfig().enableExternalizedCheckpoints(
CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//2.4 指定从 CK 自动重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 2000L));
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("127.0.0.1")
.serverTimeZone("GMT+8") //时区报错增加这个设置
.port(3306)
.username("root")
.password("123456")
.databaseList("wz")
.tableList("wz.user_info") //注意表一定要写库名.表名这种,多个,隔开
.startupOptions(StartupOptions.initial())
//自定义转json格式化
.deserializer(new MyJsonDebeziumDeserializationSchema())
//自带string格式序列化
//.deserializer(new StringDebeziumDeserializationSchema())
.build();
DataStreamSource<String> streamSource = env.addSource(sourceFunction);
//TODO 可以keyBy,比如根据table或type,然后开窗处理
//3.打印数据
streamSource.print();
//streamSource.addSink(); 输出
//4.执行任务
env.execute("flinkTableCDC");
}
private static class MyJsonDebeziumDeserializationSchema implements
com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema<String> {
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector)
throws Exception {
Struct value = (Struct) sourceRecord.value();
Struct source = value.getStruct("source");
//获取数据库名称
String db = source.getString("db");
String table = source.getString("table");
//获取数据类型
String type = Envelope.operationFor(sourceRecord).toString().toLowerCase();
if (type.equals("create")) {
type = "insert";
}
JSONObject jsonObject = new JSONObject();
jsonObject.put("database", db);
jsonObject.put("table", table);
jsonObject.put("type", type);
//获取数据data
Struct after = value.getStruct("after");
JSONObject dataJson = new JSONObject();
List<Field> fields = after.schema().fields();
for (Field field : fields) {
String field_name = field.name();
Object fieldValue = after.get(field);
dataJson.put(field_name, fieldValue);
}
jsonObject.put("data", dataJson);
collector.collect(JSONObject.toJSONString(jsonObject));
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
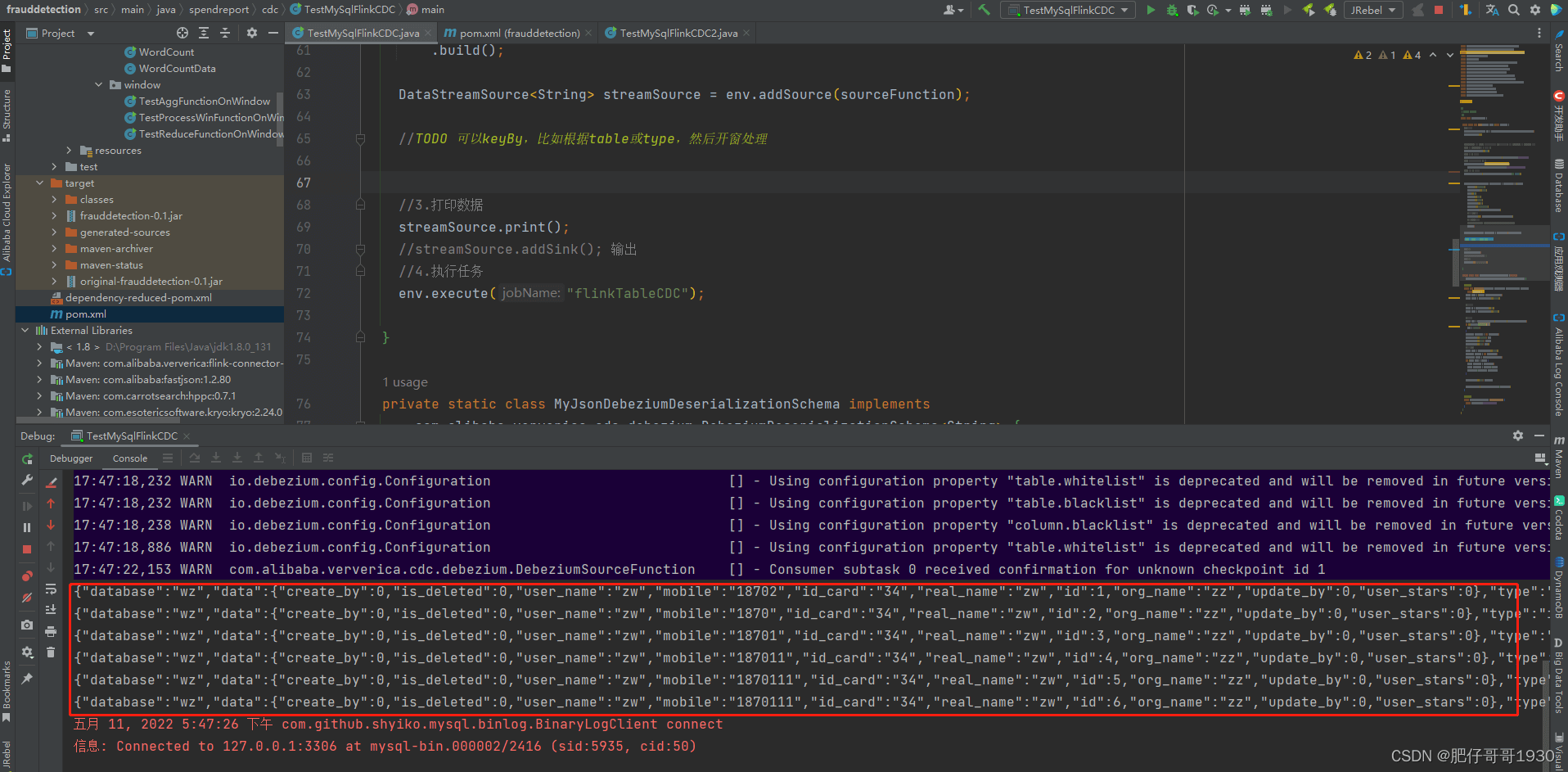
}运行效果
PS:
package spendreport.cdc;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* @author zhengwen
**/
public class TestMySqlFlinkCDC2 {
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.创建 Flink-MySQL-CDC 的 Source
String connectorName = "mysql-cdc";
String dbHostName = "127.0.0.1";
String dbPort = "3306";
String dbUsername = "root";
String dbPassword = "123456";
String dbDatabaseName = "wz";
String dbTableName = "user_info";
String tableSql = "CREATE TABLE t_user_info ("
+ "id int,mobile varchar(20),"
+ "user_name varchar(30),"
+ "real_name varchar(60),"
+ "id_card varchar(20),"
+ "org_name varchar(100),"
+ "user_stars int,"
+ "create_by int,"
// + "create_time datetime,"
+ "update_by int,"
// + "update_time datetime,"
+ "is_deleted int) "
+ " WITH ("
+ " 'connector' = '" + connectorName + "',"
+ " 'hostname' = '" + dbHostName + "',"
+ " 'port' = '" + dbPort + "',"
+ " 'username' = '" + dbUsername + "',"
+ " 'password' = '" + dbPassword + "',"
+ " 'database-name' = '" + dbDatabaseName + "',"
+ " 'table-name' = '" + dbTableName + "'"
+ ")";
tableEnv.executeSql(tableSql);
tableEnv.executeSql("select * from t_user_info").print();
env.execute();
}
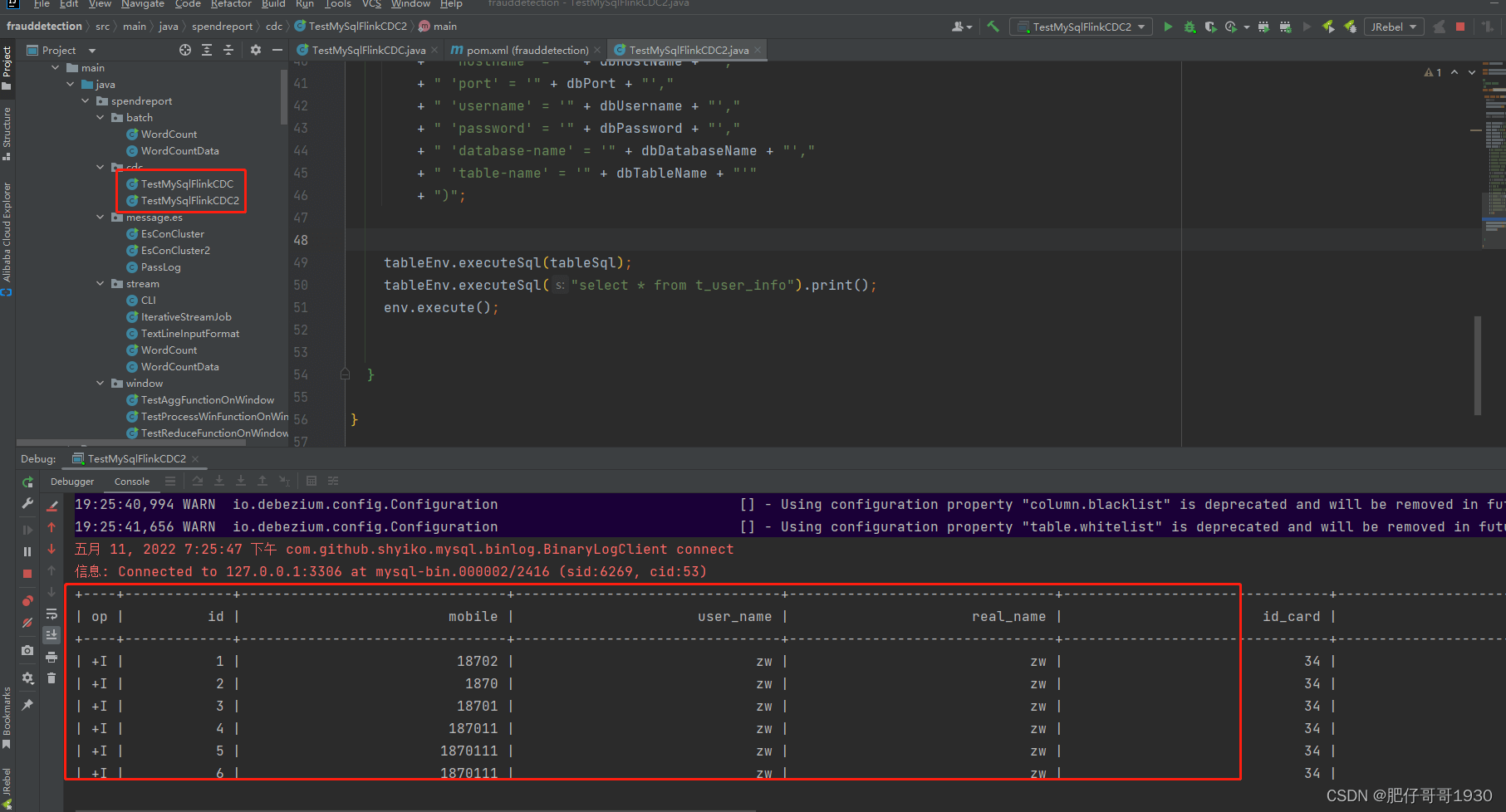
}运行效果:
既然是基于日志,那么数据库的配置文件肯定要开启日志功能,这里mysql需要开启内容

server-id=1
log_bin=mysql-bin
binlog_format=ROW #目前还只能支持行
expire_logs_days=30
binlog_do_db=wz #这里binlog的库如果有多个就再写一行,千万不要写成用,隔开
最后肯定证明这种方式同步数据可行,而且实时性特高,但是就是不知道我们的目标数据库是否可以开启这些日志配置。UP!

