在做数据导入导出的过程中,如果应用场景多了,相信各位都会遇到一个问题就是文件编码的问题,有些文件是ANSI编码,有些是utf8编码,有些又是utf8带bom编码,不同的文件编码如果都用同一种编码格式去解析读取出来的数据的话,肯定会遇到乱码的问题,这并不是Qt的问题,也不是什么Qt乱码的问题,而是要识别到文件的编码然后用对应的编码去读取内容,这样就不会出现乱码,当然乱码的出现肯定是中文,如果文件全部是英文数字,无论何种编码,都不会乱码。
那么问题来了,如何用程序自动识别文件的编码格式呢?找遍了搜索没有找到完整的答案。查阅资料得知utf8带bom编码都会有个固定的头部字节EFBBBF,所以这个好区分,由于ANSI编码和utf8编码没有对应的头部字节标识,所以需要转个弯来处理,依然是读取头部的三个字节,用QTextCodec的toUnicode函数转换,转换结果的ConverterState可以识别到可用字符数量,如果数量大于0说明是ANSI编码,需要用gbk去解码。
体验地址:http://pan.baidu.com/s/1eeL5MTz0rifwtVLegRpkoQ 提取码:erxm 文件名:bin_dataout.zip
国内站点:https://gitee.com/feiyangqingyun
国际站点:https://github.com/feiyangqingyun
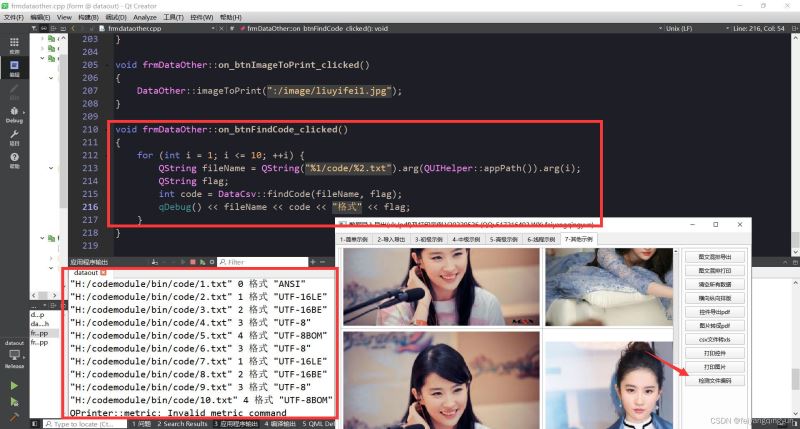
//检查文件编码 0=ANSI 1=UTF-16LE 2=UTF-16BE 3=UTF-8 4=UTF-8BOM
int DataCsv::findCode(const QString &fileName, QString &flag)
{
//假定默认编码utf8
int code = 3;
flag = "UTF-8";
QFile file(fileName);
if (file.open(QIODevice::ReadOnly)) {
//读取3字节用于判断
QByteArray buffer = file.read(3);
quint8 b1 = buffer.at(0);
quint8 b2 = buffer.at(1);
quint8 b3 = buffer.at(2);
if (b1 == 0xFF && b2 == 0xFE) {
code = 1;
flag = "UTF-16LE";
} else if (b1 == 0xFE && b2 == 0xFF) {
code = 2;
flag = "UTF-16BE";
} else if (b1 == 0xEF && b2 == 0xBB && b3 == 0xBF) {
code = 4;
flag = "UTF-8BOM";
} else {
//尝试用utf8转换,如果可用字符数大于0,则表示是ansi编码
QTextCodec::ConverterState state;
QTextCodec *codec = QTextCodec::codecForName("utf-8");
codec->toUnicode(buffer.constData(), buffer.size(), &state);
if (state.invalidChars > 0) {
code = 0;
flag = "ANSI";
}
}
file.close();
}
return code;
}

